
EverydayOneCat
很多很多很多💃💃🕺🕺

Generative Models
我们之前学过的Network通常是一个x作为input,放入Network后输出一个y,但这在实际生活中并不能涵盖所有情况。
有些情况下,一个输入有多种可能的输出,不是固定的一对一映射。也就是说,这种模型架构适合“没有标准答案”的情况,例如绘画,聊天机器人 (chat-bot) 等创作型任务。
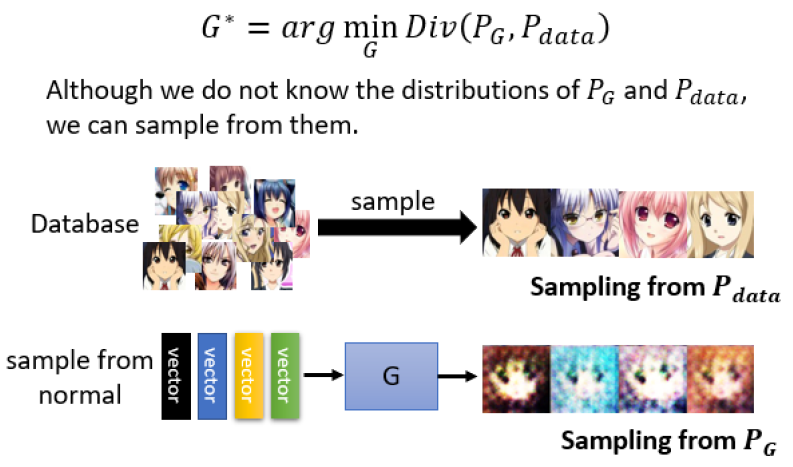
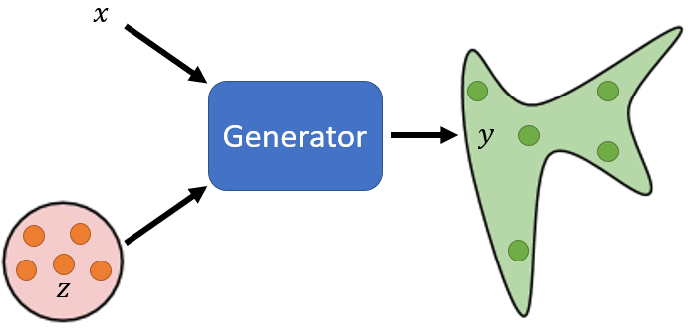
这时候就需要用到分布(Distribution),把network拿来,当作generator使用,他特别的地方是现在network的输入,会加上一个random的variable,我们称之为Z。
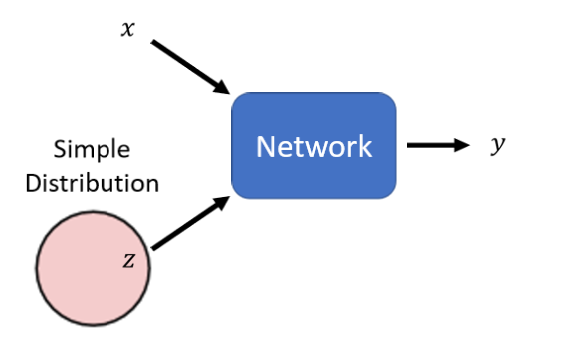
这个Z,是从某一个distribution sample出来的,所以现在network它不是只看一个固定的X得到输出,它是同时看X跟Z得到输出
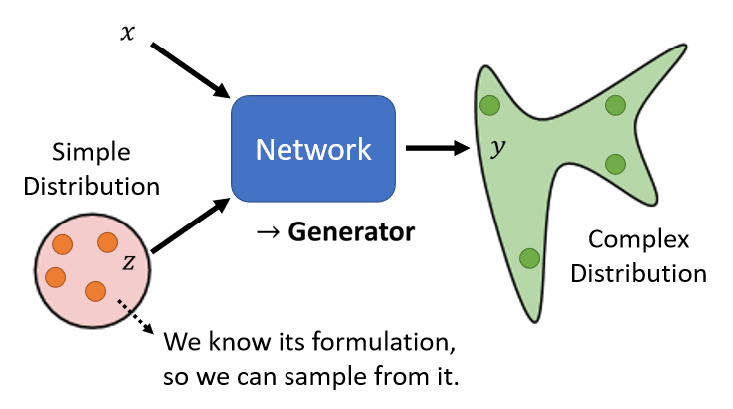
Network 作为 Generator 时,模型的输入包含了从简单分布(简单分布的意思是我们需要知道这个分布的数学公式长什么样子)中采的 sample,如下图所示。输入的随机性传递到输出,因此输出是一个复杂的分布。
Generative Adversarial Network(GAN)
Generative的model,其中一个非常知名的就是generative adversarial network,它的缩写是GAN
Unconditional generation
我们首先来看简单的GAN——Unconditional generation,就是把输入的x先拿掉,输入看作是一个已知的分布distribution。
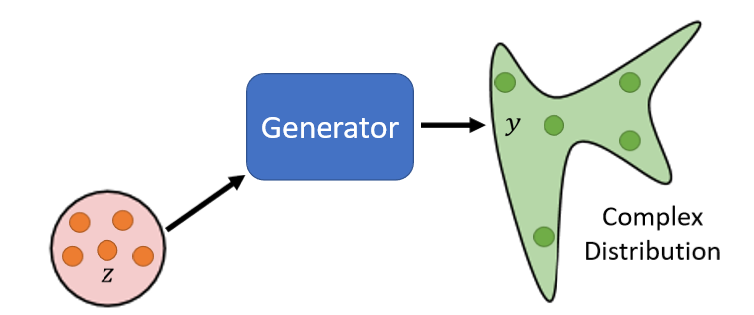
我们举一个例子,现在我们的任务就是让机器生成二次元人物头像。我们假设Z是Normal Distribution里Sample出来的向量,输出一张图片,一张图片就是一个非常高维的向量,所以generator实际上做的事情,就是产生一个非常高维的向量。

Discriminator
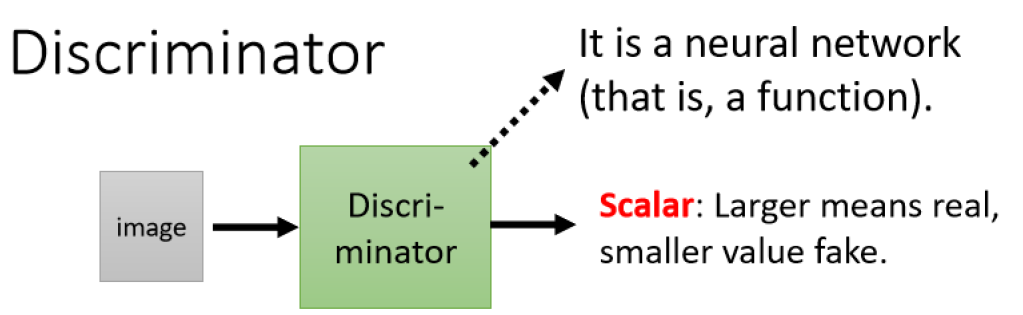
在GAN里面,我们除了要训练产生图片的Generator之外,我们还需要训练一个额外的Network——分辨器Discriminator。
discriminator它的作用是,它会拿一张图片作为输入,它的输出是一个数值,这个discriminator本身,也是一个neural network,它就是一个function
放到我们上面的例子,它输入一张图片,它的输出就是一个数字,它输出就是一个scalar,这个scalar越大就代表说,现在输入的这张图片,越像是真实的二次元人物的图像。
有了Generator和Discriminator我们就可以来训练我们的GAN了。第一代的generator它的参数几乎是,它的参数完全是随机的,所以它根本就不知道,要怎么画二次元的人物,所以它画出来的东西就是一些,莫名其妙的杂讯,那discriminator接下来,它学习的目标是,要分辨generator的输出,跟真正的图片的不同,那在这个例子裡面可能非常的容易,对discriminator来说它只要看说,图片裡面有没有眼睛,有眼睛就是真正的二次元人物,没有眼睛就是generator,产生出来的东西,接下generator就调整它的裡面的参数,Generator就进化了,它调整它裡面的参数 它调整的目标,是为了要骗过discriminator。如此循环往复。
Algorithm
接下来介绍一下GAN的算法演示。
首先需要将Generator和Discriminator的参数全部初始化。
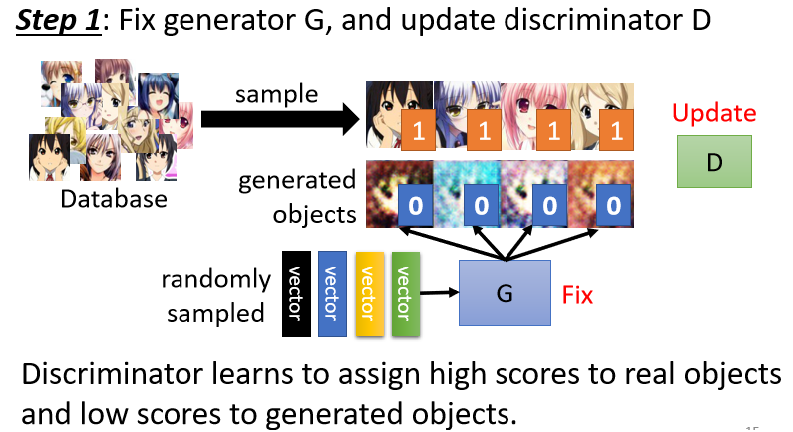
接着第一步就是定住Generator,只Train Discriminator,然后从二次元头像Database中sample出一些二次元头像来,让Discriminator能分辨出Generator产生出来的图片和真正的二次元头像的区别。具体一点就是你实际上的操作是这个样子,你可能会把这些真正的人物都标1,Generator产生出来的图片都标0。其实对于Discriminator来说,这就是一个分类问题或者说regression的问题。
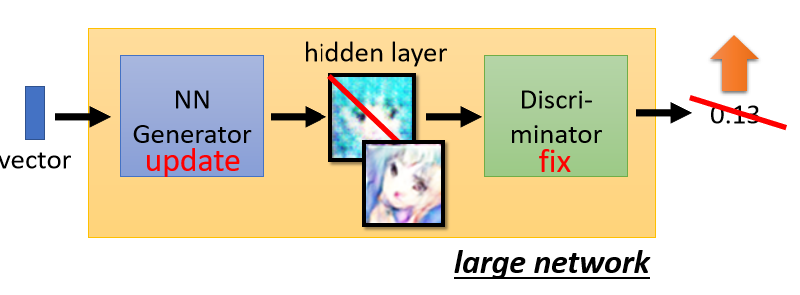
训练完Discriminator后,第二步就是定住discriminator改成训练generator。怎么训练呢,我们分别把generator和discriminator分别堪称好几层的network,然后把他们连接起来看成一个大的network,这个巨大的network,它会吃一个向量作为输入,然后他会输出一个分数,那我们希望调整这个network,让输出的分数越大越好,但是要注意一下 我们不会去调,对应到Discriminator的部分,只调Generator对应的那几层。
所以现在讲了两个步骤
- 第一个步骤 固定generator,训练discriminator
- 第二个步骤,固定discriminator训练generator
接下来就是反覆的训练。
GAN 中 Generator 和 Discriminator 的关系:既是敌人,又在这种较量中促进了彼此的提高,这就是 GAN (Generative Adversarial Network) 中 Adversarial 的由来,在对抗中提升。
Thoery behind GAN
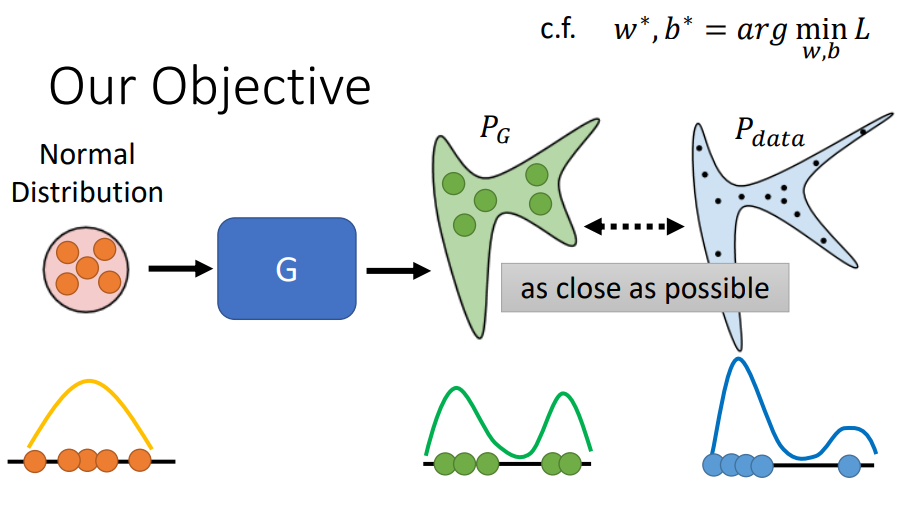
GAN的训练目标:从简单的 Normal Distribution 采样的数据,经过 Generator,得到的输出分布$P_G$接近目标分布$P_{data}$,如下图所示。
如果写成式子的话,可以写成如下这个样子
$Div(P_G,P_{data})$意思就是 $P_G$ 跟 $P_{data}$,这两个 Distribution 之间的 Divergence(散度)
Divergence 这边指的意思就是,这两个你可以想成是,这两个 Distribution 之间的某种距离。
那么问题来了,要怎么计算$Div(P_G,P_{data})$呢?你可能知道一些 Divergence 的式子,比如说 KL Divergence,比如说 JS Divergence,这些 Divergence 用在这种 Continues 的,Distribution 上面,实作上你几乎不知道要怎么算积分,那我们根本就无法把这个 Divergence算出来。
而 GAN是一个很神奇的做法,它可以突破,我们不知道怎么计算 Divergence 的限制。你不需要知道 $P_G$ 跟$P_{data}$它们实际上的 Formulation 长什么样子,只要能从 $P_G$ 和 $P_{data}$这两个 Distributions Sample东西出来,就有办法算 Divergence。
为什么可以用 sampling 来代表 distribution 计算 divergence?
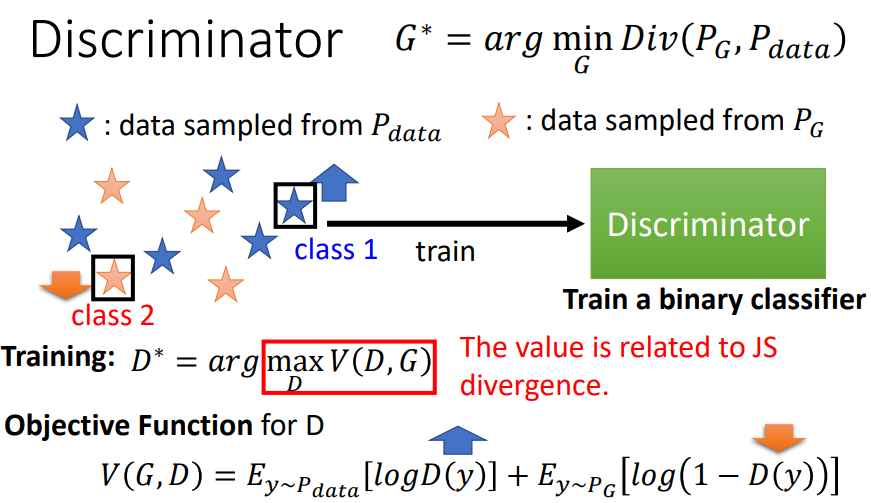
这与 Discriminator 的设计有关。Discriminator 就是要尽量把从$P_{data}$ sample 的数据与从 $P_G$ sample 的数据分开,这其实也可以用 Binary Classifier 做,把 $P_{data}$ sample 当作 class 1, $P_G$ sample 当作 class 2,如下图所示。设计 Classifier 的目标函数 $V(G,D) $为: $P_{data}$ sample 经过 Discriminator 得到的分数为 $logD(y)$ ,这个分数要尽量高;$P_G$ sample 经过 Discriminator 得到的分数为 $log(1−D(y)) $,这个分数要尽量低。因此,训练的目标要使 $V(G,D) $最大。
而神奇的地方就在于,我们发现这个值与 JS divergence 有关。我们可以从直观的角度来看一下,为什么这个Objective Function的值会和divergence有关。
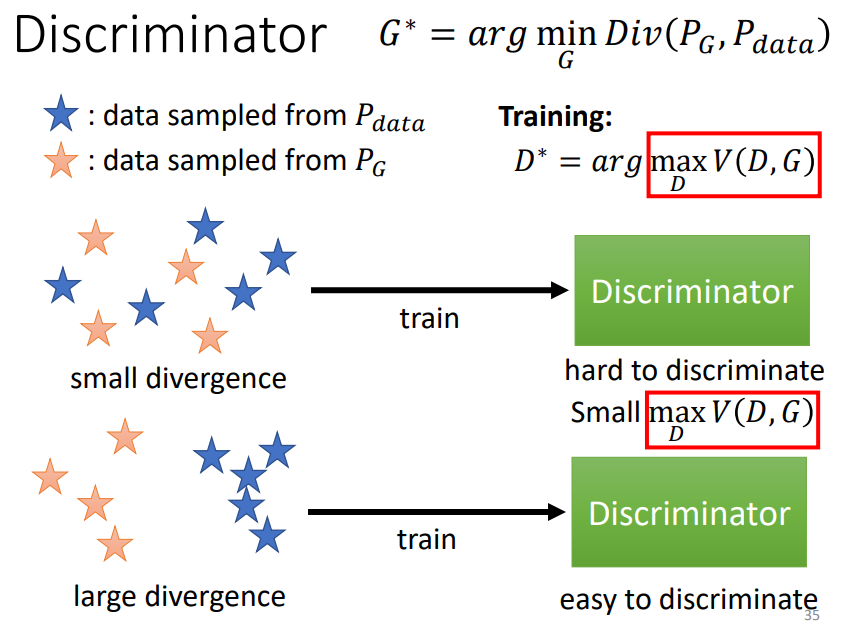
- 假设$P_G$和$P_{data}$他们的Divergence很小,也就是说$P_G$和$P_{data}$他们很像,他们差距并没有很大,是混在一起的,这时候Discriminator就很难将他们分开,也就是这个Objective Function的值并不会很大。
- 假设$P_G$和$P_{data}$他们的Divergence很大,那对于Discriminator而言就能很轻易地将他们分开,这个 Objective Function 就可以冲得很大。
详细的证明请参见 GAN 原始的 Paper。
如果说训练 Discriminator的目标是使 $V(G,D) $最大,那么 Generator 的目标就是要使这个最大可能的$ V(G,D)$ 尽量小,也就是说使 $P_G$和$P_{data}$ 的 JS divergence 尽量小。因此,就有下图所示的 $min$ $max $两个符号。

最终式子看上去很复杂,它有一个 Minimum,又有一个 Maximum,其实分开就是干了两件事:
- 我们是要找一个 Generator,去 Minimize 红色框框裡面这件事
- 但是红框框裡面这件事,又是另外一个 Optimization Problem,它是在给定 Generator 的情况下,去找一个 Discriminator,这个 Discriminator,可以让 V 这个 Objective Function 越大越好
WGAN
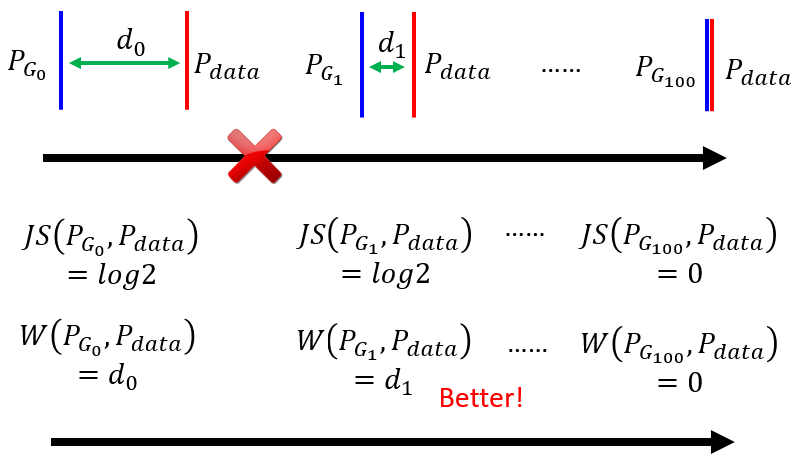
PG 跟 Pdata 有一个非常关键的特性是,PG 跟 Pdata 它们重叠的部分往往非常少
而JS Divergence 有个特性,是两个没有重叠的分布,JS Divergence 算出来,就永远都是 Log2。而实际上在我们Train玩Discriminator后,Discriminator 始终可以准确分开这两类,如下图所示。这导致 Generator 无法知道训练是否带来结果的提升,训练学不到东西。

解决方法:改用 Wasserstein distance。
Wasserstein Distance 的思想:我们把分布想象成一个小土堆,Wasserstein distance 计算的是要把土堆(分布)A 变换到土堆 B,推土机挪动土堆 A 的距离。
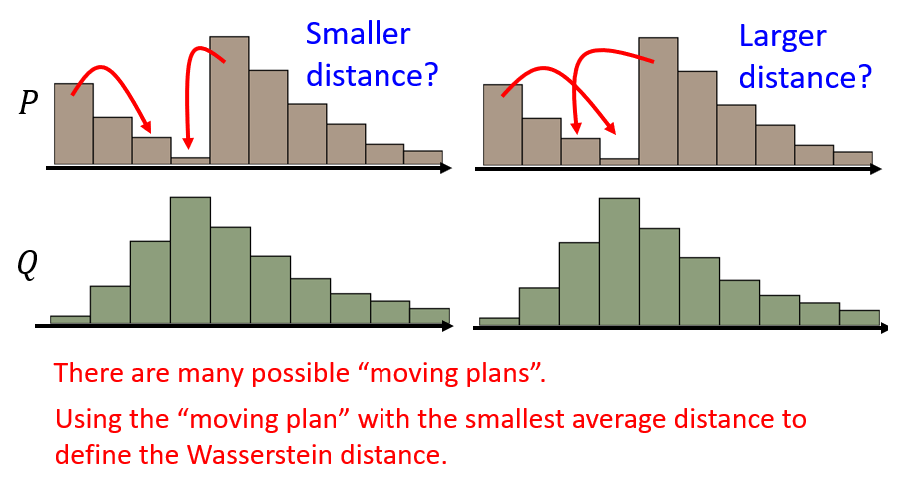
为了让 Wasserstein Distance 只有一个值,所以这边 Wasserstein Distance 的定义是,穷举所有的Moving Plans,然后看哪一个推土的方法,哪一个 Moving 的计划,可以让平均的距离最小,那个最小的值,才是 Wasserstein Distance。
Wasserstein distance 虽然难计算,但是好处是计算出了两个类别分布的距离大小,因此能够捕捉一点一滴的改变(或者说进化),如下图所示。这样,Generator 就可以根据结果来一点点提高。
俗话说得好,“一口吃不成个胖子”,量变产生质变。这里 Wasserstein distance 较 JS Divergence 的改进之处正在于注重了对“量变”的及时反馈。JS Divergence 就像是一步到位,从新手一下子就到高手,可想而知这很难。而 Wasserstein distance 就是对每一阶段的努力都有一个反馈:现在是进步还是退步了,一点点地提高,最终到达目标。
当你用 Wasserstein Distance,来取代 JS Divergence 的时候,这个 GAN 就叫做WGAN。
使用 Wasserstein distance 的目标函数如下图所示。注意这里有一个条件 $D∈1−Lipschitz$ ,换言之, D 函数要平滑。为什么呢?如果没有这个条件设置,为了让目标函数的值最大,D 函数就会变成:对于 $P_{data} $sample, $D(y)=+∞$ ;对于 $P_G$ sample, $D(y)=−∞$ 。这就会和 JS divergence 一样,训练中学不到东西。而加上这个平滑限制,如下图所示,因为曲线要连续而不能剧烈变化,也就不会到$ ∞$ ,这才是 Wasserstein distance,能让 Generator 渐进提高。

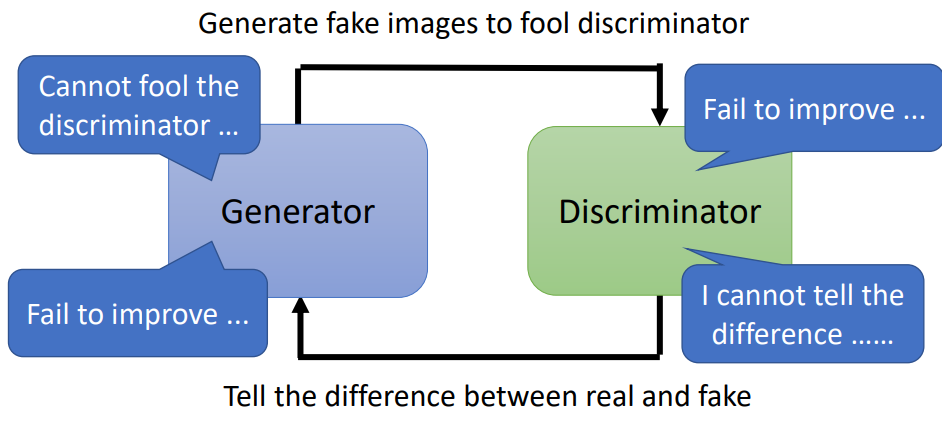
虽然说已经有 WGAN,但其实并不代表说GAN就一定特别好 Train,GAN 仍然是以很难把它 Train 起来而闻名的。GAN在本质上就存在一个问题:GAN 结构的 Generator 和 Discriminator 要棋逢对手,如果有一个没有提高,那么另一方也会停止改进,如下图所示。在实际训练中,无法保证每一次 Discriminator 的 loss 都会下降,一旦 loss 不下降,就会出现连锁反应,整个结构都不再改进。
GAN for Sequence Generation
Train GAN 最难的其实是要拿 GAN 来生成文字。
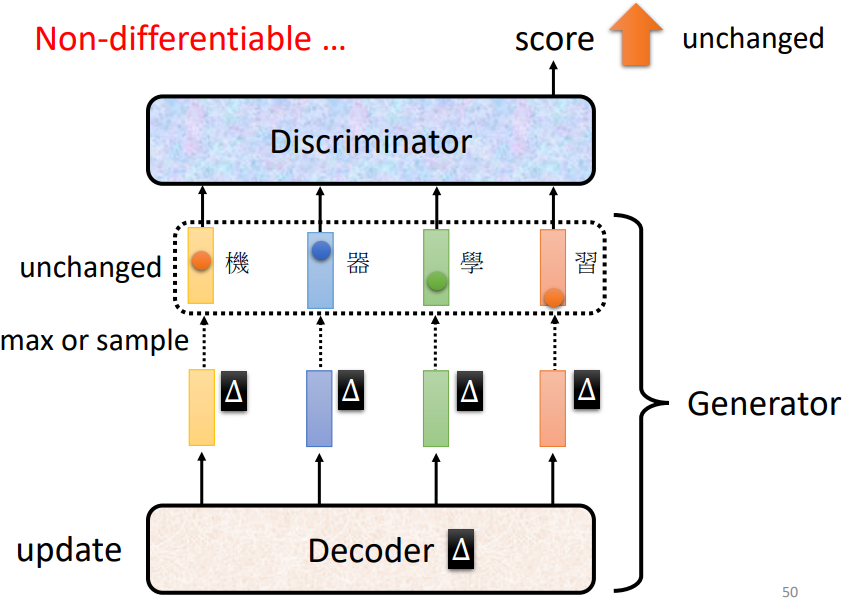
如果你要生成一段文字,那你可能会有一个,Sequence To Sequence 的 Model,你有一个 Decoder,如下图所示,我们可以把 Transformer 的 Decoder 部分看成是 GAN 的 Generator ,生成的 sequence 送入 Discriminator 中判断是不是真的文字。这里的问题是 loss 没办法做微分。为什么呢?大家知道,在用Gradient Descent方法中计算微分的时候,所谓的 Gradient,所谓的微分,其实就是某一个参数,它有变化的时候,对你的目标造成了多大的影响。假设 Decoder 的输入有微小的变化,因为 Generator 的输出是取概率最大的那个,输出 sequence 不变,进而 Discriminator 的输出也不变,没有变化也就算不出微分。
Evaluation of Generation
评估一个 Generator 的好坏,并没有那么容易,最直觉的做法也许是找人来看,但是完全用人来看显然有很多的问题,比如说不客观,不稳定等等诸多的问题。
有一种方法,把你的 GAN 产生出来的图片,丢到一个的影像的分类系统裡面,看它产生什么样的结果。
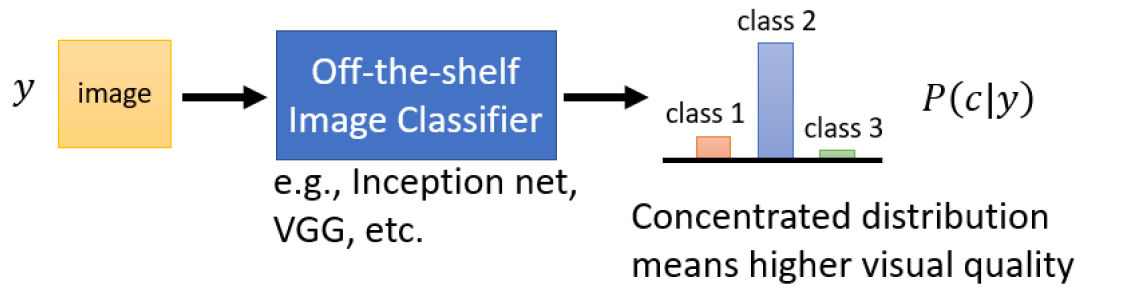
然后我们就可以推断说,这个机率的分布如果越集中,就代表说现在产生的图片可能越好。但是这个方法还是很有问题:如果你产生出来的图片是一个四不像,根本看不出是什么动物,那影像辨识系统就会非常地困惑,它产生出来的这个机率分布,就会非常地平坦,非常地平均分布,那如果是平均分布的话,那就代表说你的 GAN,产生出来的图片,可能是比较奇怪的,所以影像辨识系统才会辨识不出来。
Mode Collapse问题:
在真正Train的过程中,又是你会碰到这种现象。你会发现说 Generative Model,它输出来的图片来来去去,就是那几张,可能单一张拿出来,你觉得好像还做得不错,但让它多产生几张就露出马脚。

Mode Dropping问题:
有另外一种更难被侦测到的问题,叫做 Mode Dropping,Mode Dropping 的意思是说,你的真实的资料分布可能是下图这个样子,但是你的产生出来的资料,只有真实资料的一部分,单纯看产生出来的资料,你可能会觉得还不错,而且分布的这个多样性也够。

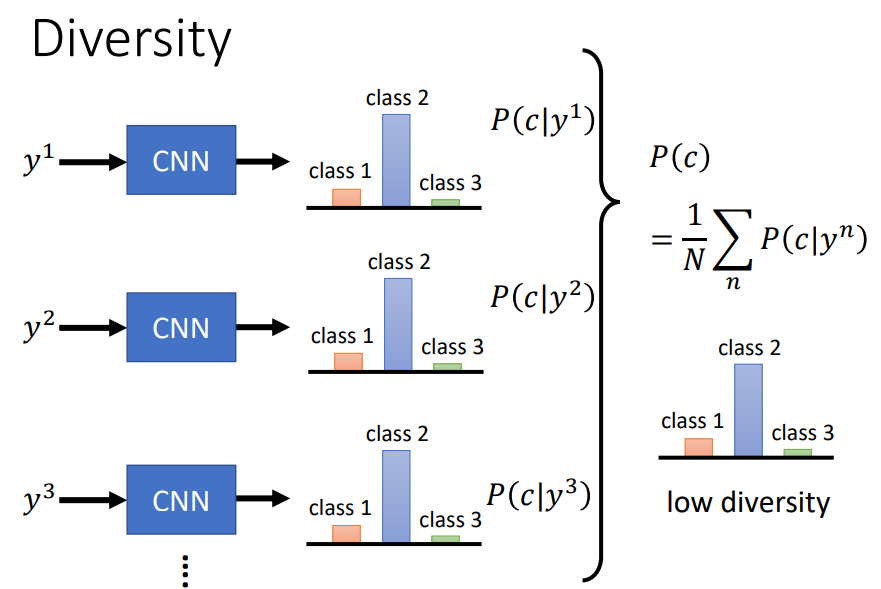
要解决上述问题,可以把一组 generated data 输入 CNN Classifier,然后把得到的各分类概率分布取平均作为结果。如果这个平均概率分布中,各类别的分布比较平均,那就说明 generated data 有足够的 diversity。
Conditional Generation(CGAN)
简单 GAN 产生的图片天马行空,可能不是我们想要的,所以要加入一些限制条件。我们给它一个 Condition x,让它根据 x 跟 z来產生 y。
我们举一个实际应用的例子:Text To Image。这样的任务裡面,我们的 x 就是一段文字,输出的y就是跟文字描述一致的照片。
我们现在的 Generator 有两个输入,一个是从 Normal DistributionSample 出来的 z,另外一个是 x,也就是一段文字,输出图像y。接着我们需要一个Discriminator,来判断图片是Generator生成的还是真实的。然后 Discriminator 跟 Generator 反覆训练。
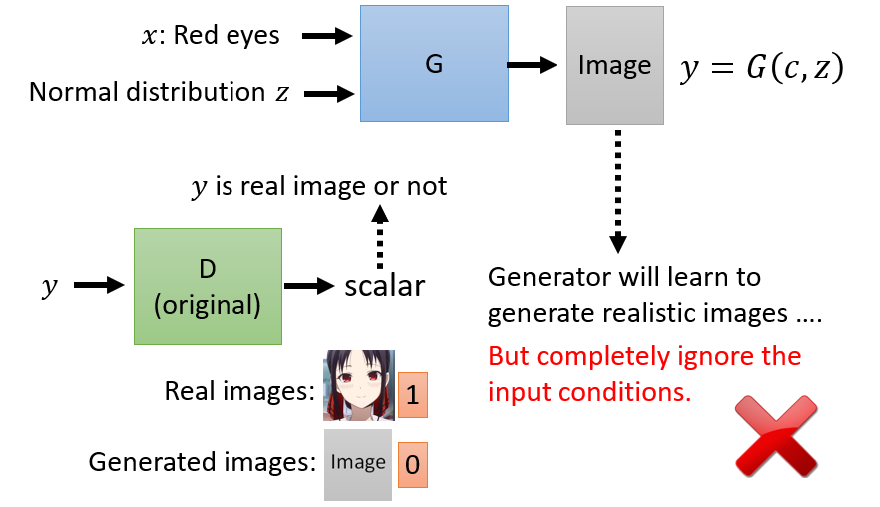
但这样的方法,没办法真的解 Conditional GAN 的问题,为什么,因为如果我们只有 Train 这个 Discriminator,这个 Discriminator 只会看 y 当做输入的话,那 Generator会学到的是,它会產生可以骗过 Discriminator 的非常清晰的图片,但是可能和文字x没有丝毫关系。因為对 Generator 来说,它只要產生清晰的图片就可
以骗过 Discriminator 了,它何必要去管 Input 文字叙述是什麼。
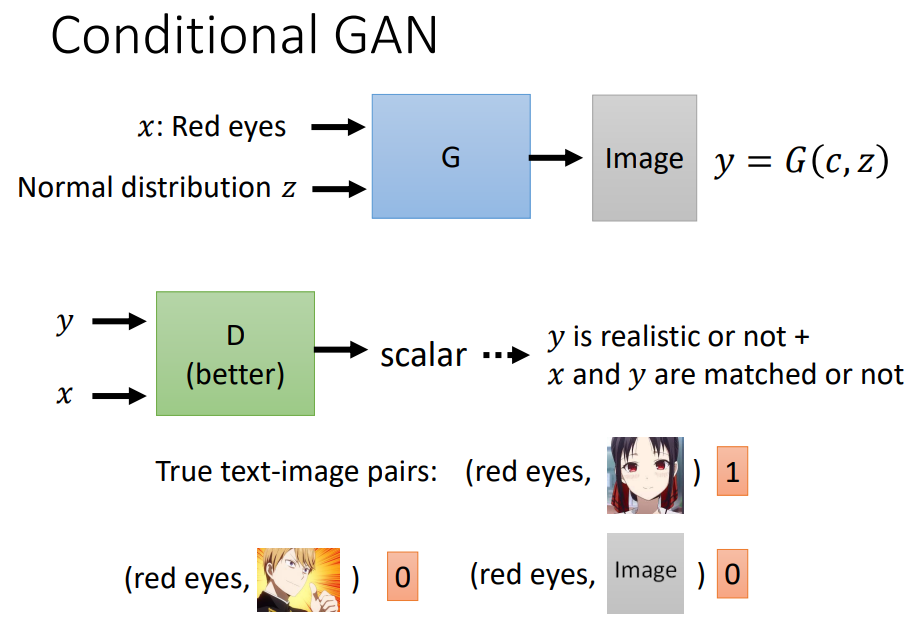
所以在 Conditional GAN 裡面,你的 Discriminator 不是只吃图片 y,它还要吃Condition x。然后產生一个数值,那这个数值不只是看 y 好不好,光图片好没有用,Discriminator 还是不会给高分。Discriminator 给高分的时候,一方面图片要好,另外一方面,这个图片跟文字的叙述必须要是相配的。
所以Conditional GAN训练的时候,是需要成对的资料的,需要有标注的资料。但是这样还是不够,根据实际经验,这些资料不仅要有标签和图片相匹配的,还需要加上一种不好的状况是,已经產生好的图片但是文字叙述配不上的状况。
当然,CGAN还有很多应用的例子,如看一个图片产生另一张图片,叫做Image translation (pix2pix)。
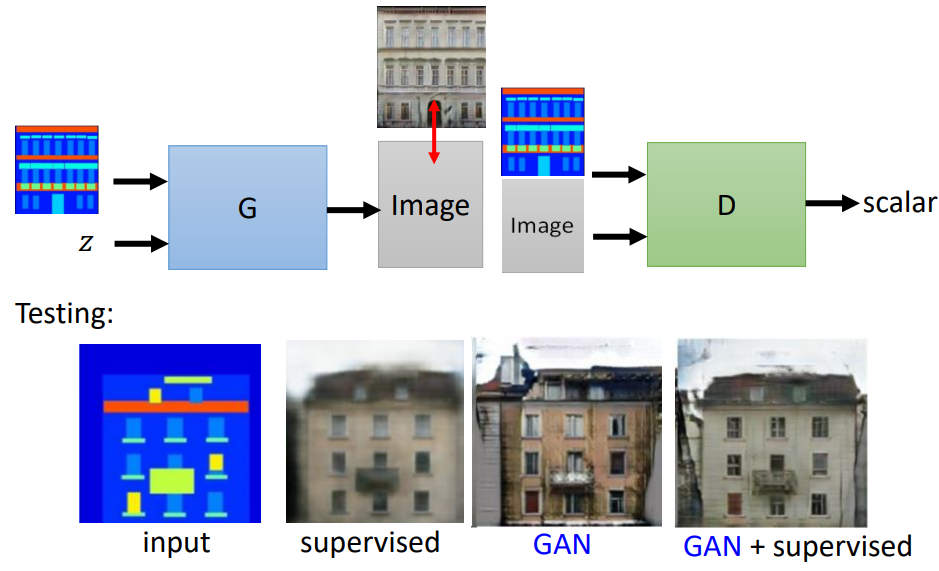
比如:黑白到彩色,白天景物到夜景,轮廓素描到实物图。例如:从建筑结构图到房屋照片的转换效果如下图所示,如果用 supervised learning,得到的图片很模糊,为什么?因为一个建筑结构图对应有多种房屋外形,这样训练时机器就会考虑多种情况,做平均。如果用 GAN,机器有点自由发挥了,房屋左上角有一个烟囱或窗户的东西。而用 GAN+supervised,也就是 conditional GAN,生成的图片效果就很好。
还有sound-to image:从声音生成相应的图片,比如输入水声,生成溪流图片。
再如talking head generation:静态图转动态,让照片里的人物动起来。
具体参考https://arxiv.org/abs/1905.08233
Cycle GAN
目前来说,我们都是介绍的Supervised Learning,但在实际应用中,Unsupervised Learning的情况也不在少数,比如影像风格转化。假设我们今天要做的就是将真人照片集X Domain转化为二次元人物集Y Domian对应的头像,两者没有对应关系,也就是 unpaired data。
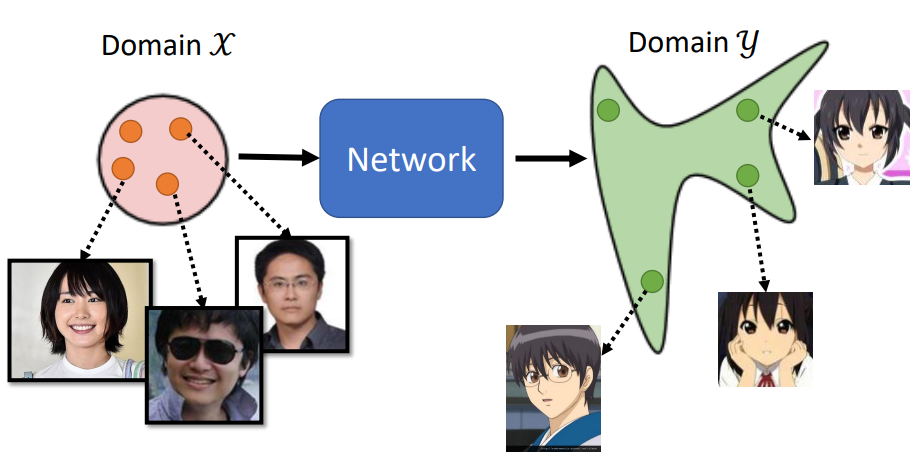
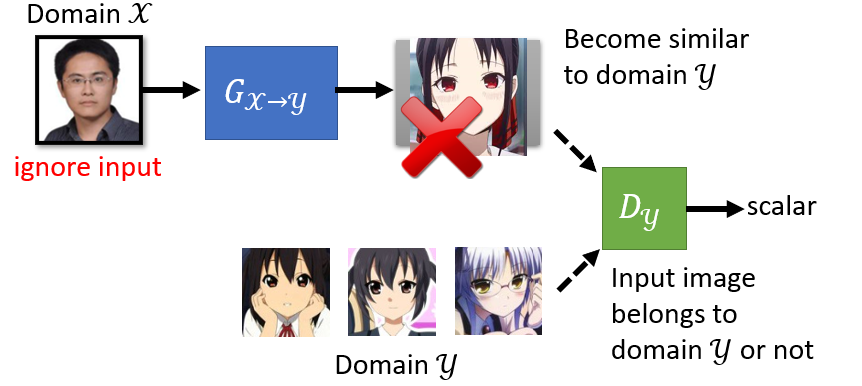
我们完全可以套用之前的GAN训练步骤,从真人集Sample出一个分布作为输入,把他丢入GAN里面让他产生另外一个distribution里面的图片。再来一个Discrimination,让他分辨看到Y domain的图就给它高分,看到不是Y domain的图,不是二次元人物就给它低分。generator它可能真的可以学到输出Y domain的图,但是它输出的Y domain的图一定要跟输入有关系吗?你没有任何的限制要求你的generator做这件事。最后导致训练出来的Generator,它可以生成二次元人物头像,但是和输入进去的图像没有任何关系。
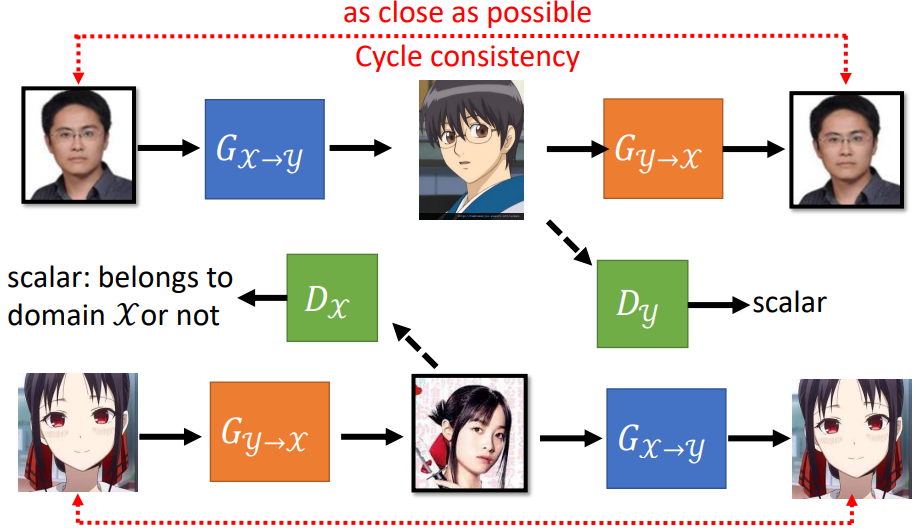
Cycle GAN 增加了一个 $G_{y−>x}$ ,把生成的动漫图片再变换到人物图片。训练使 $G_{y−>x}$ 生成的人物图片与原图尽量接近,以此达到了原图和生成动漫头像的对应,如下图所示。
此外,还可以反向训练,从动漫图片到人物图片,再到动漫图片。训练 Cycle GAN 时可以两个方向同时训练。
类似的应用:文字风格转换 (Text Style Transfer),比如把消极的文字都转换为积极的文字。
结语
你🍐的幕刃含金量我是认可的,一个小小空间都能有这么多故事,震惊我半年😲

