
EverydayOneCat
“什么时候?” “猫!”
MobileNet
传统卷积神经网络,内存需求大、运算量大,导致无法在移动设备以及嵌入式设备上运行。
MobileNet V1
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)
MobileNet V1网络中的亮点:
- Depthwise Convolution(大大减少运算量和参数数量)
- 增加超参数α、β
DW卷积
先来看我们传统的卷积
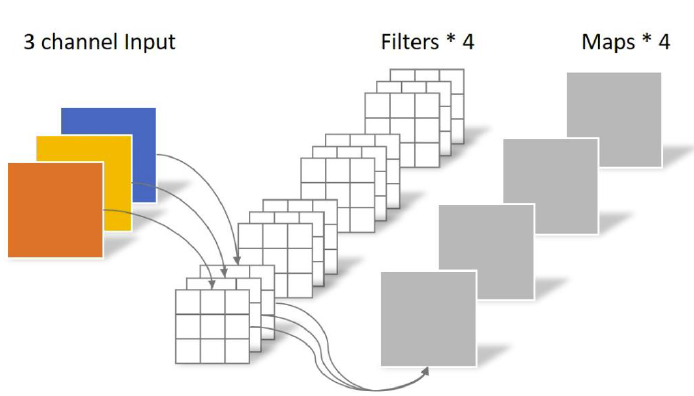
传统卷积卷积核channel = 输入特征矩阵的channel 、 输出特征矩阵的channel = 卷积核个数
接下来我们来看DW卷积(Depthwise Conv)是什么
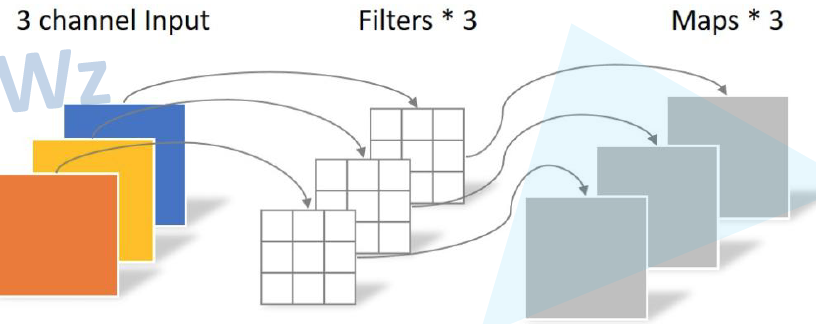
每个卷积核的深度都是1,每个卷积核都只负责和输入特征矩阵的一个通道数进行计算,得到输出特征矩阵的一个channel,一个卷积核负责一个channel;所以卷积核的个数和输入特征矩阵的深度相同;输出特征矩阵的深度也就和卷积核的个数相同。
而我们MobileNet所用的是深度可分的卷积操作(depthwise separable Conv) ,由两部分组成:DW卷积+PW卷积
PW卷积就是卷积核大小为1*1的传统卷积

我们来对比深度可分卷积和普通卷积计算量大小。
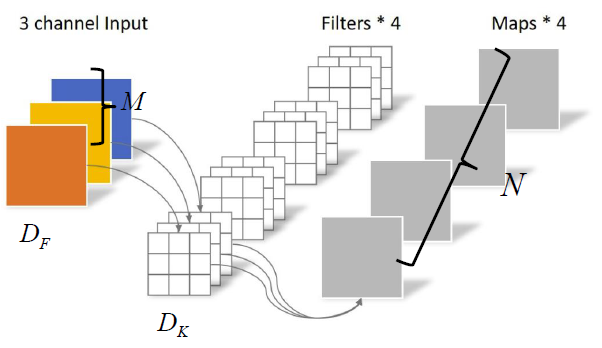
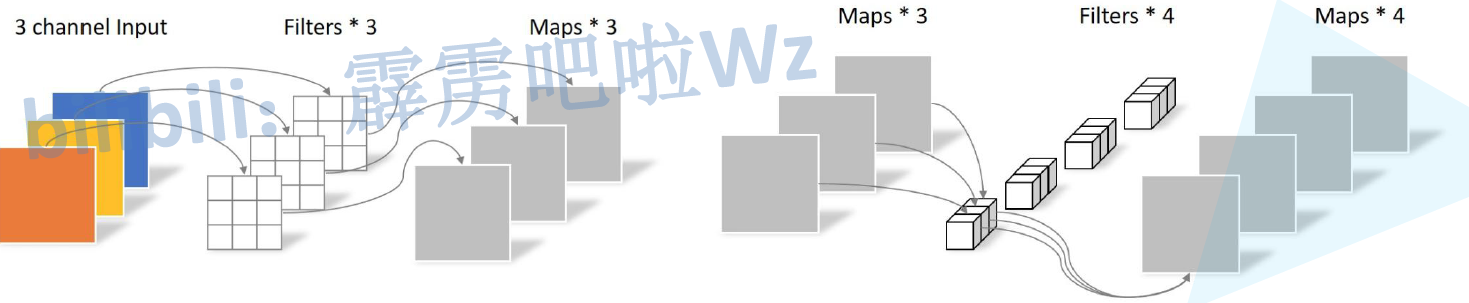
参数解读:
$D_F$:Input高宽大小
M:Input维度
$D_K$:卷积核大小(默认为3)
N:Output维度
传统卷积所需参数:$D_KD_KMND_F*D_F$
深度可分卷积所需参数:$D_KD_KD_FD_FM+D_FD_FM*N$

MobileNet V1结构分析
V1网络整体结构:

表中conv/s2代表普通卷积,stride=2,filter shape那一列中的高3 宽3 输入特征矩阵的深度3 * 卷积核个数32;
conv dw /s1对应DW卷积操作且stride=1,filter shape列中DW卷积的深度为1,所以他的卷积核的shape是高3 宽3 卷积核深度1 * 输出特征矩阵深度32;
参照原论文表格可以看出计算量大幅减少:

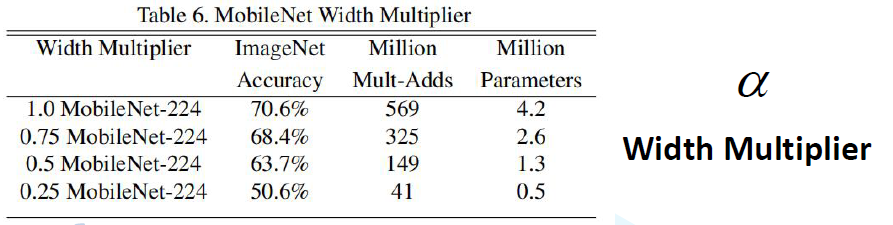
α超参数是卷积核个数的倍率,也就是控制卷积过程中卷积核的个数,alpha=1.0时,准确率为70.6%,alpha=0.75,也就是卷积核个数缩减为原来的0.75倍,准确率为68.4%;可以看出卷积核个数减少了不多,但是模型参数却减少了很多。
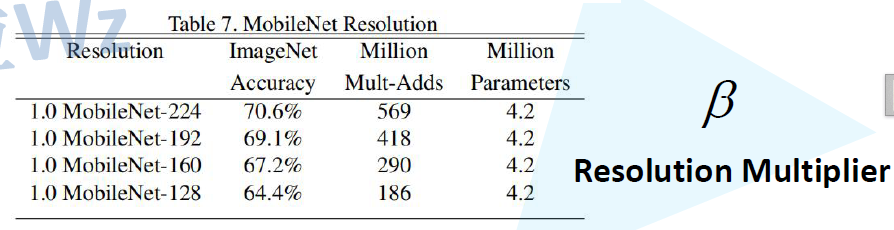
β是分辨率的参数,表格7看出不同的输入图像尺寸对于网络准确率和模型计算量的对比,224224的RGB图像,计算准确率为70.6%,计算量是569million;192192的RGB图像,计算准确率为69.1%,计算量是418;可以适当减少输入图像的大小来使得准确率降低一点的情况下,计算量大幅减少。
V1有一个很大的缺陷:depthwise部分的卷积核容易费掉,即卷积核参数大部分为零。由此V2应运而生。
MobileNet V2
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。
本网络的亮点:
- Inverted Residuals(倒残差结构)
- Linear Bottlenecks
倒残差结构

如上图,左边是之前在ResNet中介绍的残差结构,它是先对输入特征矩阵采用1 × 1的卷积核来对特征矩阵进行压缩,也就是减少输入特征矩阵的channel,然后用3 × 3卷积核处理,最后用1 × 1的卷积核来扩充channel;
右边则是MobileNet V2新增的倒残差结构,先用1×1的卷积核进行升维操作,将channel变的更深,通过卷积核大小为3×3的DW操作进行卷积,再用1×1的卷积核进行降维。
倒残差结构是先用卷积升维,在用卷积降维;残差结构是反过来的,先用卷积降维,在用卷积升维。
普通残差结构的激活函数为ReLU,倒残差结构的激活函数为ReLU6。(原因:ReLU激活函数对低维特征信息照成大量损失)


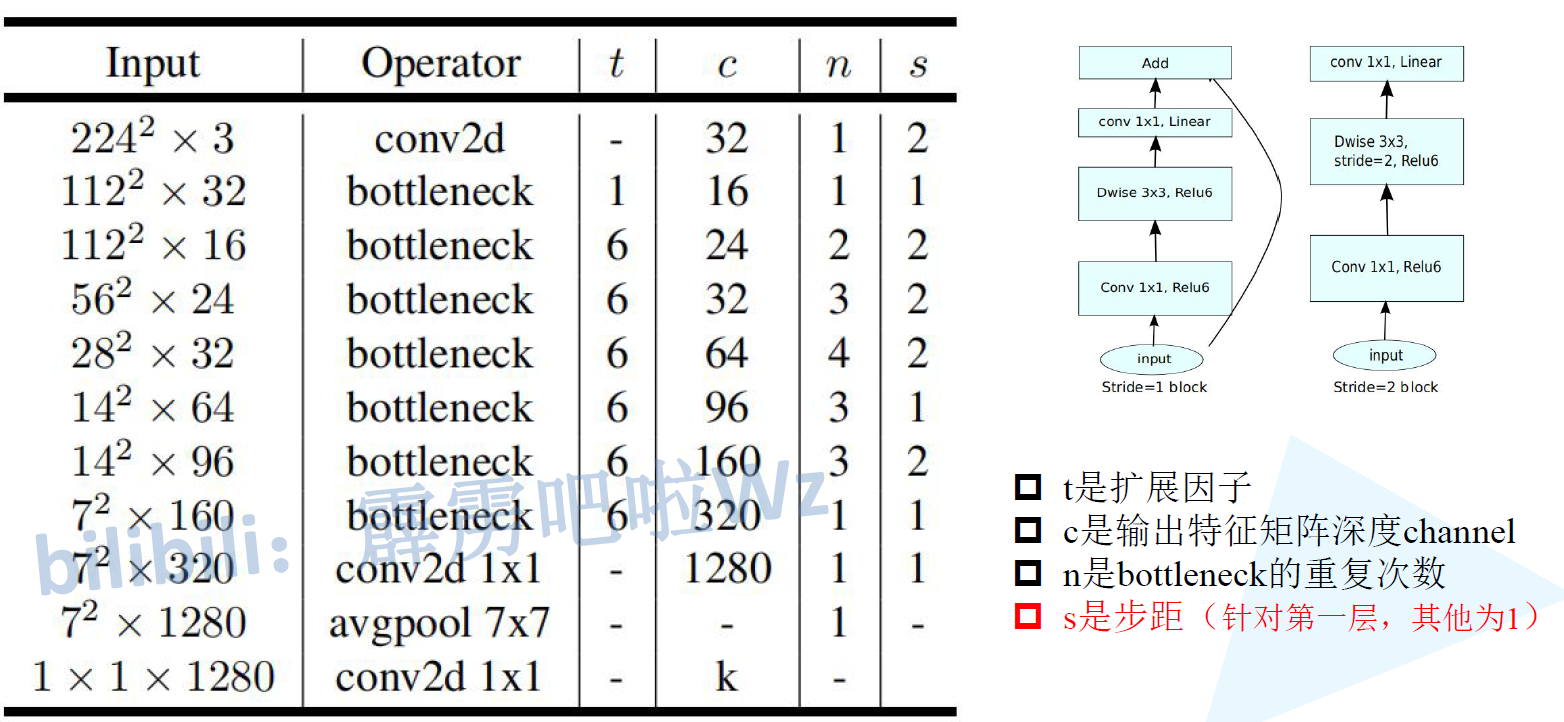
左边是Mobilenet V2倒残差网络结构图,通过1×1的卷积,ReLU6激活,3×3的DW卷积,ReLU6激活,1×1的卷积来处理,线性激活。对应右表给的每一层信息,第一层输入特征矩阵的高宽深度h×w×k,1×1卷积核进行升维处理,output里面的t是扩展因子,表示1×1卷积核的个数是tk个,输出特征矩阵的深度就是tk;第二层输入等于第一层输出,经过3×3的DW卷积核,步长为s,输出矩阵的深度和输入矩阵深度相同;第三层,采用1×1的卷积核降维,使用k’个卷积核。
当stride=1且输入特征矩阵与输出特征矩阵shape相同才有shortcut连接
MobileNet V2结构分析
model
定义我们的基础卷积结构
1 | class ConvBNReLU(nn.Sequential): |
定义倒残差结构
1 | class InvertedResidual(nn.Module): |
最后定义模型
1 | #返回ch值最接近divisor的整数倍 |
MobileNet V3
V3网络的亮点:
- 更新Block(bneck)
- 使用NAS搜索参数
- 重新设计耗时层结构
V3相比V2更准确,更高效
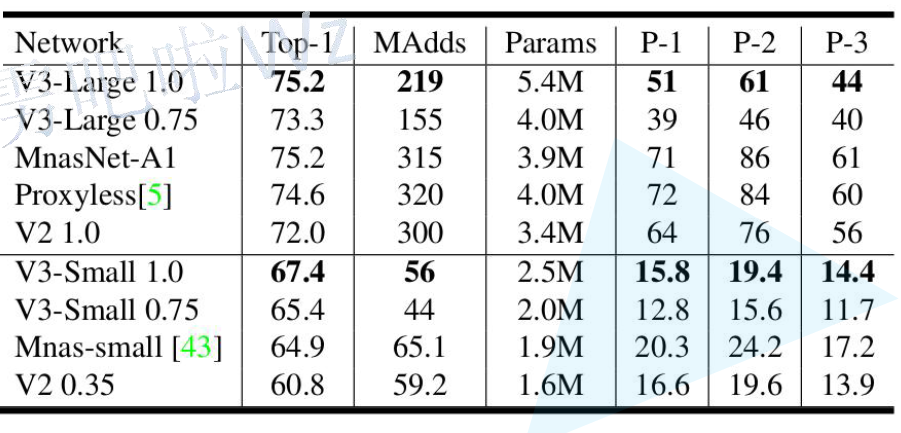
V3的Block
BLOCK相比于V2,增加了以下特性:
- 加入SE模块(引入注意力机制)
- 更新了激活函数
SE模块
SENet是Squeeze-and-Excitation Networks的简称,拿到了ImageNet2017分类比赛冠军,其效果得到了认可,其提出的SE模块思想简单,易于实现,并且很容易可以加载到现有的网络模型框架中。SENet主要是学习了channel之间的相关性,筛选出了针对通道的注意力,稍微增加了一点计算量,但是效果比较好。

上图是SE模块的一个例子,我们首先通过平均池化得到每个channel的平均值,接着通过ReLu和H-Sigmoid两个全连接层得到各个channel的权重,原先的特征矩阵乘以得到的权重就实现了注意力机制。具体而言,就是通过学习来自动获取到每个特征通道的重要程度,然后依照这一结果去提升有用的特征并抑制对当前任务用处不大的特征。
重新设计
重新设计耗时层结构:
- 减少第一个卷积层的卷积核个数(32->16)
- 精简Last Stage
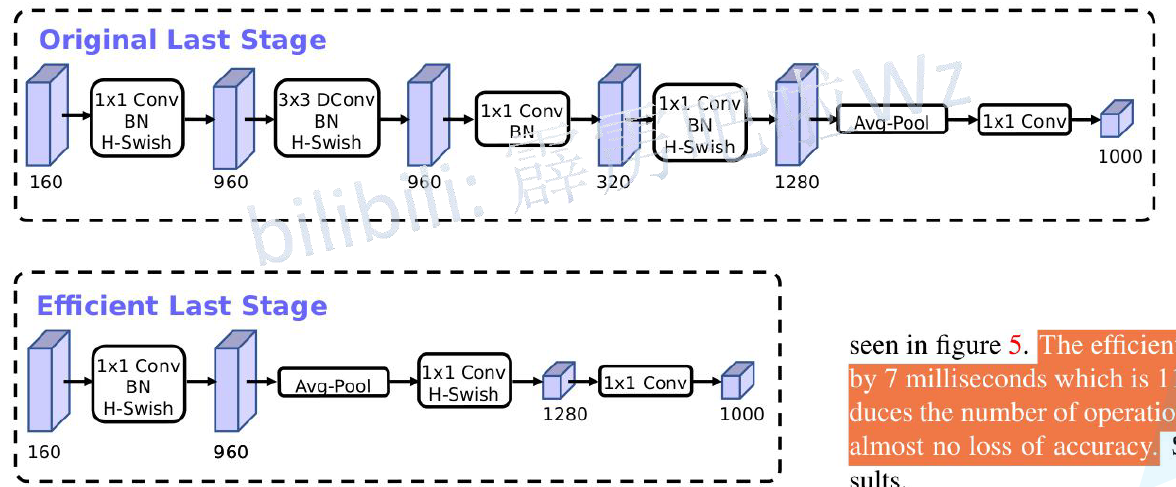
重新设计激活函数:
V3结构
MobileNetV3-Large:

MobileNetV3-Small:

model
定义V3基础卷积层
1 | class ConvBNActivation(nn.Sequential): |
定义SE模块
1 | class SqueezeExcitation(nn.Module): |
定义倒残差结构:
1 | class InvertedResidualConfig: |
定义模型
1 | def _make_divisible(ch, divisor=8, min_ch=None): |
实例化MobileNetV3-Large
1 | def mobilenet_v3_large(num_classes: int = 1000, |
实例化MobileNetV3-Small
1 | def mobilenet_v3_small(num_classes: int = 1000, |
ShuffleNet
ShuffleNet V1
ShuffleNet是一种专门为计算资源有限的设备设计的神经网络结构,主要采用了pointwise group convolution 和 channel shuffle两种技术,在保留了模型精度的同时极大减少了计算开销。
channel shuffle
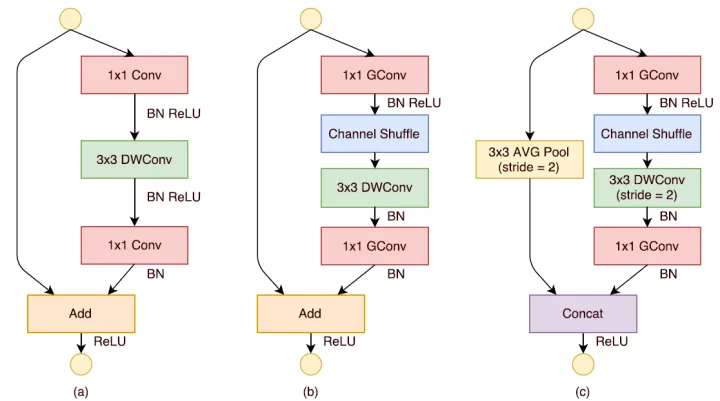
ShuffleNet的核心设计理念是对不同的channels进行shuffle来解决group convolution带来的弊端。之前我们介绍Renext的时候它的核心思想就是将channel分组来降低计算量,但是group convolution存在另外一个弊端:如图1-a所示,其中GConv是group convolution,这里分组数是3。可以看到当堆积GConv层后一个问题是不同组之间的特征图是不通信的,这就好像分了三个互不相干的路,大家各走各的,这目测会降低网络的特征提取能力。这也是为什么之前的网络在group convolution后采用密集的1x1卷积,因为要保证group convolution之后不同组的特征图之间的信息交流。
ShuffleNet参照了group convolution的思想并在其基础上做出改进,如图1-b所示,你可以对group convolution之后的特征图进行“重组”,这样可以保证接下了采用的group convolution其输入来自不同的组,因此信息可以在不同组之间流转。这个操作等价于图2-c,即group convolution之后对channels进行shuffle,但并不是随机的,其实是“均匀地打乱”。
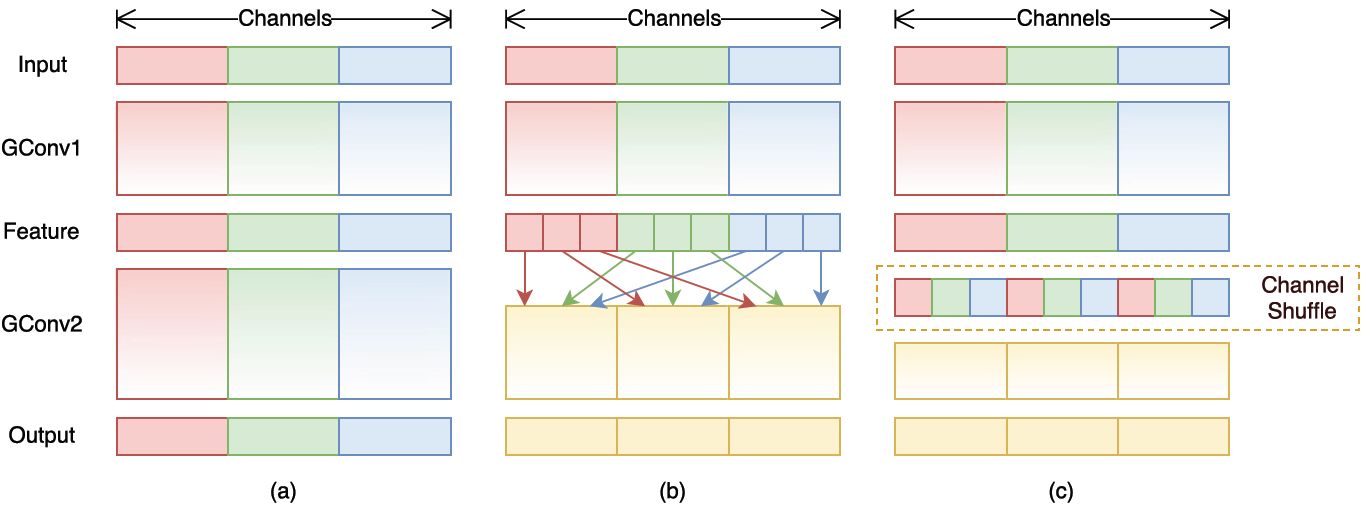
网络结构
ShuffleNet的基本单元是在一个残差单元的基础上改进而成的。如图2-a所示,这是一个包含3层的残差单元:首先是1x1卷积,然后是3x3的depthwise convolution(DWConv,主要是为了降低计算量),这里的3x3卷积是瓶颈层(bottleneck),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。现在,进行如下的改进:将密集的1x1卷积替换成1x1的group convolution,不过在第一个1x1卷积之后增加了一个channel shuffle操作。值得注意的是3x3卷积后面没有增加channel shuffle,按paper的意思,对于这样一个残差单元,一个channel shuffle操作是足够了。还有就是3x3的depthwise convolution之后没有使用ReLU激活函数。改进之后如图2-b所示。对于残差单元,如果stride=1时,此时输入与输出shape一致可以直接相加,而当stride=2时,通道数增加,而特征图大小减小,此时输入与输出不匹配。一般情况下可以采用一个1x1卷积将输入映射成和输出一样的shape。但是在ShuffleNet中,却采用了不一样的策略,如图2-c所示:对原输入采用stride=2的3x3 avg pool,这样得到和输出一样大小的特征图,然后将得到特征图与输出进行连接(concat),而不是相加。这样做的目的主要是降低计算量与参数大小。
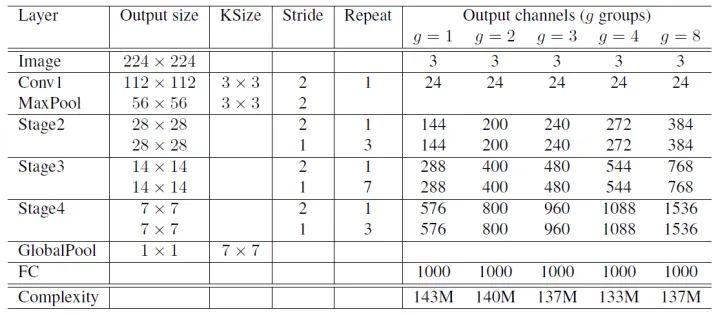
ShuffleNet V2
网络结构
ShuffleNetV2对shufflenet进行了进一步的改进,并且提出了四个设计轻量化网络的原则:
- 当卷积层的输入特征矩阵与输出特征矩阵channel相等时内存访问量MAC最小(保持FLOPs不变时)
- 当GConv的groups增大时(保持FLOPs不变时),MAC也会增大
- 网络设计的碎片化程度越高(复杂的并行串行结构),速度越慢
- Element-wise操作带来的影响是不可忽视的(如Relu、AddTensor等)
我们基于上述四个原则对V1的网络结构进行优化(左边两个为V1,右边两个为V2优化过后的结构)
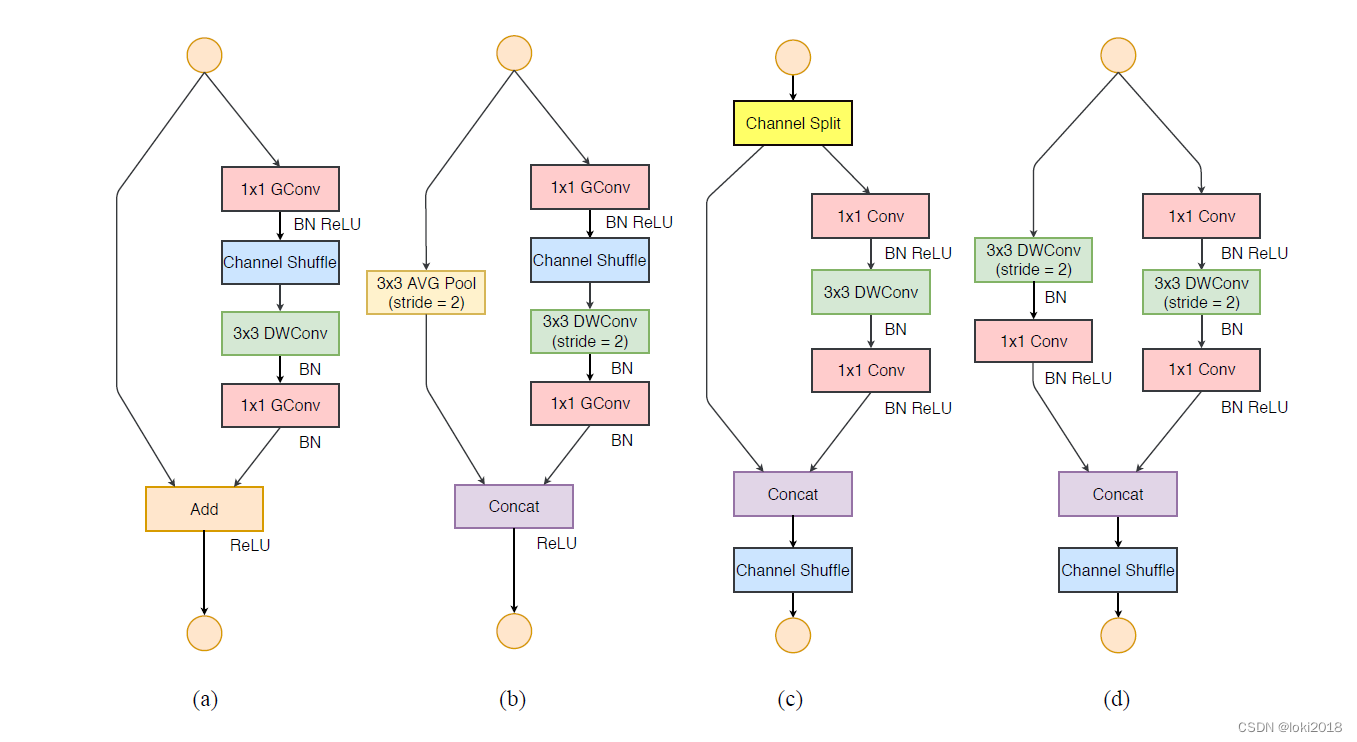
如图( c )所示,在每个单元的开始,c特征通道的输入被分为两个分支(在ShuffleNetV2中这里是对channels均分成两半)。根据G3,不能使用太多的分支,所以其中一个分支不作改变,另外的一个分支由三个卷积组成,它们具有相同的输入和输出通道以满足G1。两个1 × 1卷积不再是组卷积,而改变为普通的1x1卷积操作,这是为了遵循G2(需要考虑组的代价)。卷积后,两个分支被连接起来,而不是相加(G4)。因此,通道的数量保持不变(G1)。然后使用与ShuffleNetV1中相同的“channels shuffle”操作来启用两个分支之间的信息通信。需要注意,ShuffleNet v1中的“Add”操作不再存在。像ReLU和depthwise convolutions 这样的元素操作只存在于一个分支中。
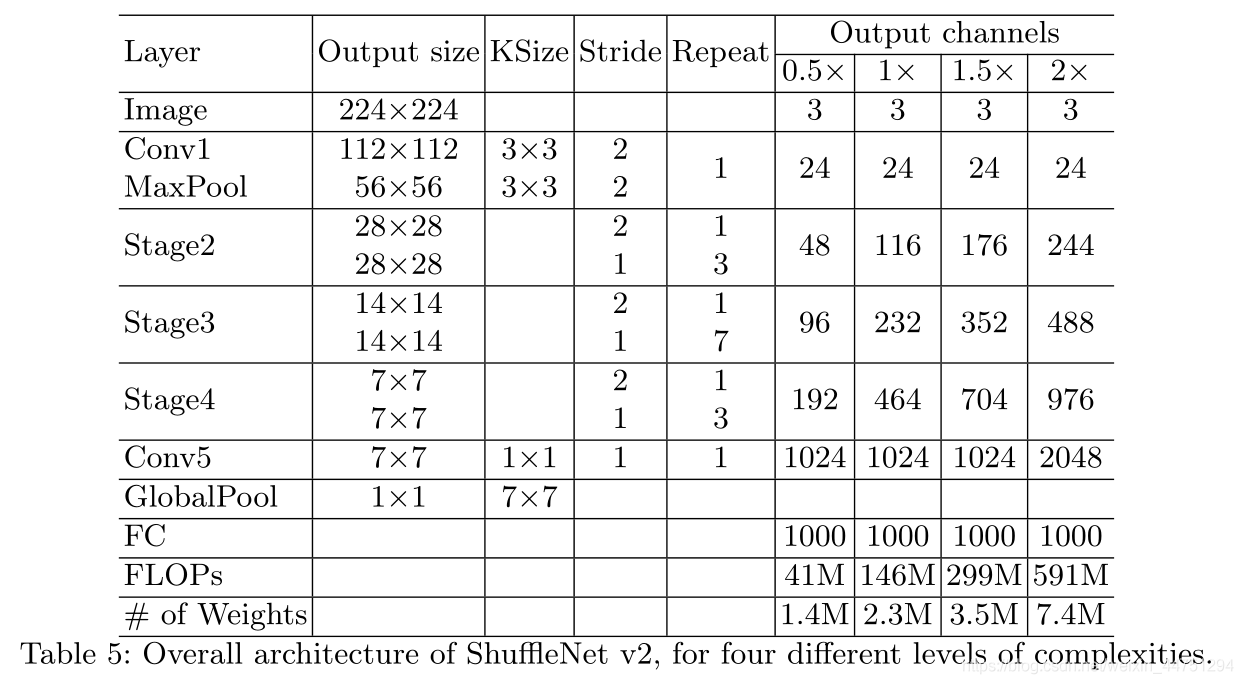
model
1 | from typing import List, Callable |
结语
英文论文对我来说还真是一道不可逾越的大山😭

