
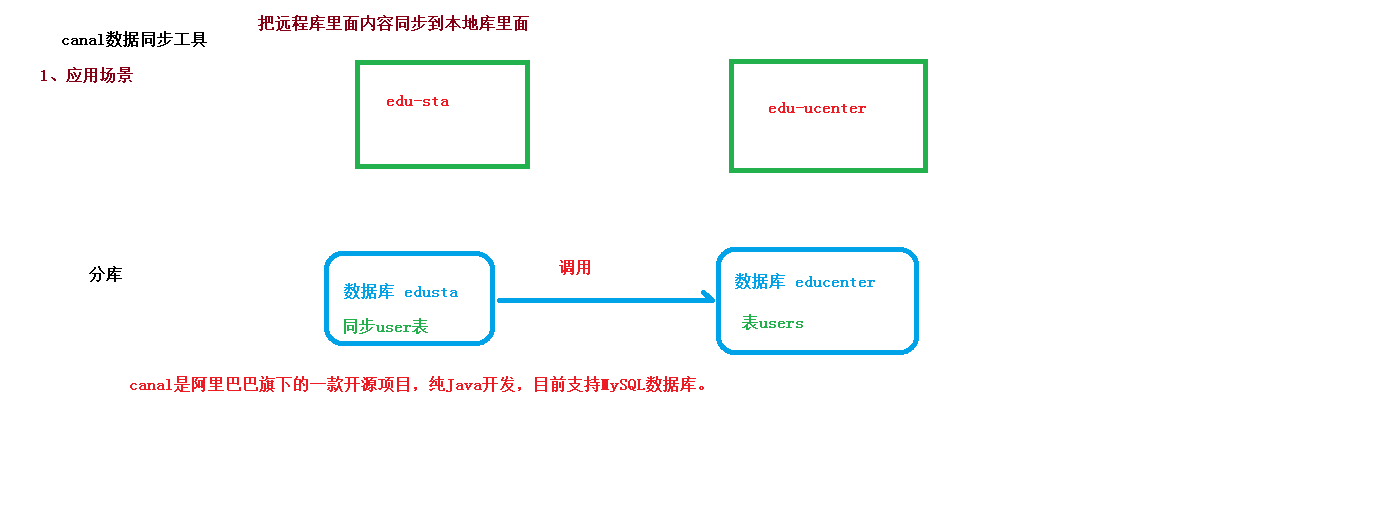
应用场景
在谷粒学院的统计分析功能中,我们采取了服务调用获取统计数据,这样耦合度高,效率相对较低,目前我采取另一种实现方式,通过实时同步数据库表的方式实现,例如我们要统计每天注册与登录人数,我们只需把会员表同步到统计库中,实现本地统计就可以了,这样效率更高,耦合度更低,Canal就是一个很好的数据库同步工具。canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL。
长话短说,Canal就是一个将本地数据库得以和远程数据库同步的工具。
Linux下的安装
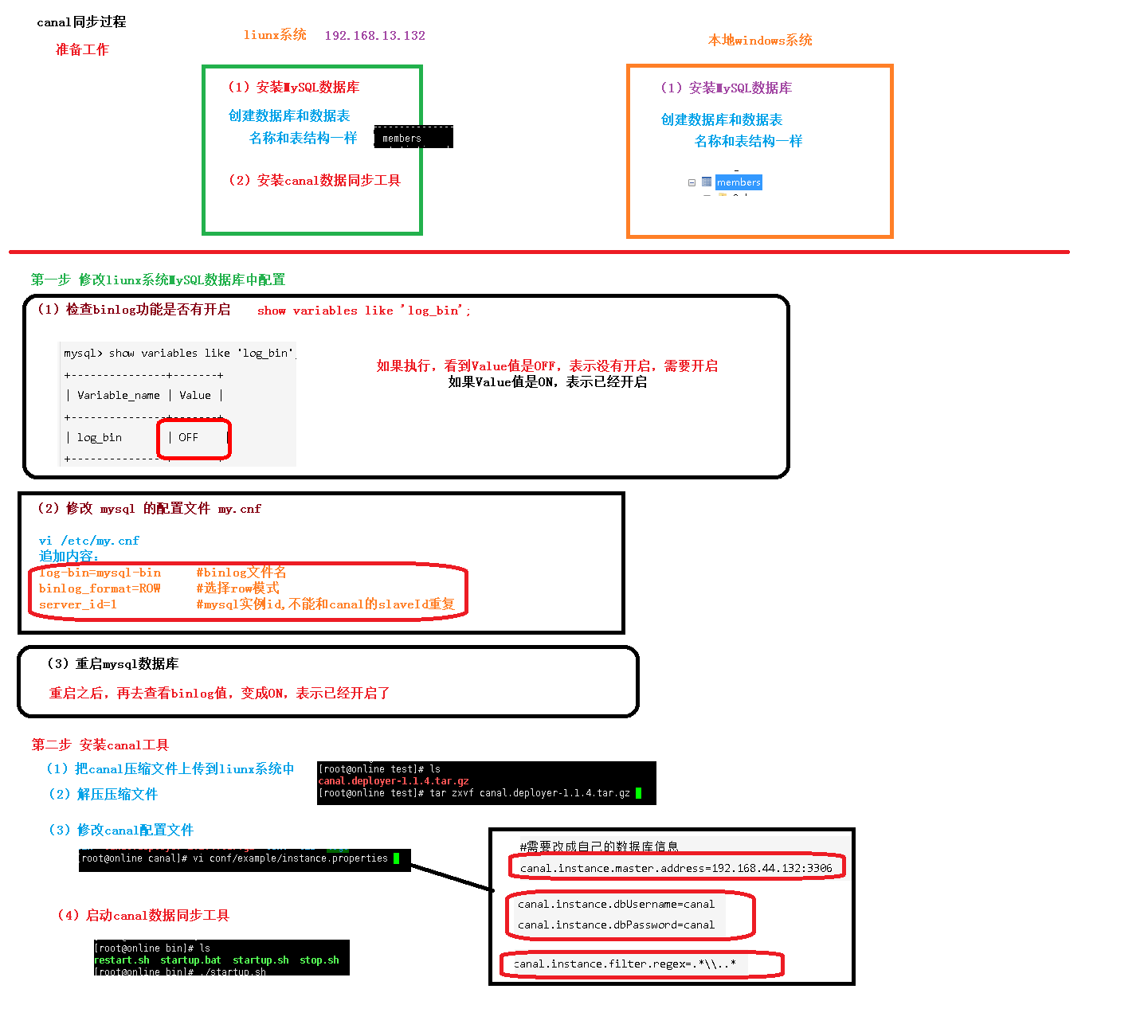
1.准备工作
canal的原理是基于mysql binlog技术,所以这里一定需要开启mysql的binlog写入功能
(1)开启mysql服务: service mysql start
(2)检查binlog功能是否有开启
1 | show variables like 'log_bin'; |
(3)如果显示状态为OFF表示该功能未开启,开启binlog功能
1 | 1,修改 mysql 的配置文件 my.cnf |
(4)由于一般mysql默认不可远程访问,我们需要在mysql里面添加以下的相关用户和权限
1 | CREATE USER 'canal'@'%' IDENTIFIED BY 'canal'; |
2.正式安装
下载地址:
https://github.com/alibaba/canal/releases
(1)下载之后,放到目录中,解压文件
1 | cd /usr/local/canal |
(2)修改配置文件
1 | vi conf/example/instance.properties |
1 | #需要改成自己的数据库信息 |
注:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\)
常见例子:
- 所有表:. or .\..*
- canal schema下所有表: canal\..*
- canal下的以canal打头的表:canal\.canal.*
- canal schema下的一张表:canal.test1
- 多个规则组合使用:canal\..*,mysql.test1,mysql.test2 (逗号分隔)
注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
(3)进入bin目录下启动:sh bin/startup.sh
本地实现数据库同步
(1)创建canal_client模块,引入相关依赖
1 | <dependencies> |
(2)创建application.properties配置文件
1 | # 服务端口 |
(3)编写canal客户端类
1 | import com.alibaba.otter.canal.client.CanalConnector; |
(4)创建启动类
1 |
|
(5)接着我们在linux下测试修改数据库,发现本地服务会监听其的动作并在本地数据库做出同样动作。

