
前言
本博文根据B站用户”葬心不留情“编写的笔记修改改编而成,如有侵权请联系作者。
什么是微服务架构:

SpringCloud 是微服务一站式服务解决方案,微服务全家桶。它是微服务开发的主流技术栈。它采用了名称,而非数字版本号。
springCloud 和 springCloud Alibaba 目前是最主流的微服务框架组合。
版本选择:
选用 springboot 和 springCloud 版本有约束,不按照它的约束会有冲突。
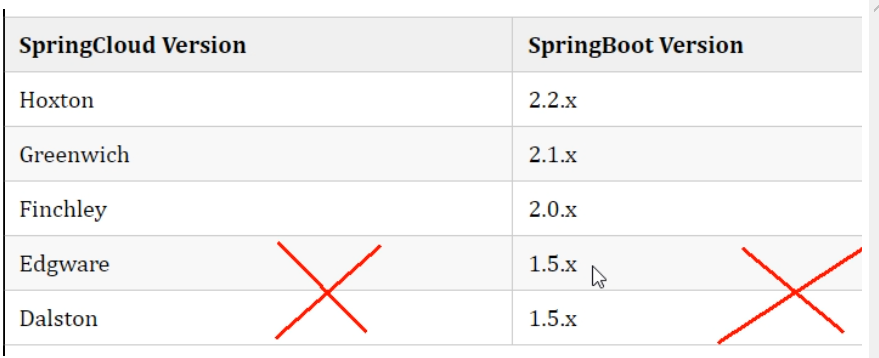
本次学习的各种软件的版本:

Cloud简介
如今2020处于新老迭代的时期,以下图列举了目前热门的和即将进入历史长河的微服务技术选型
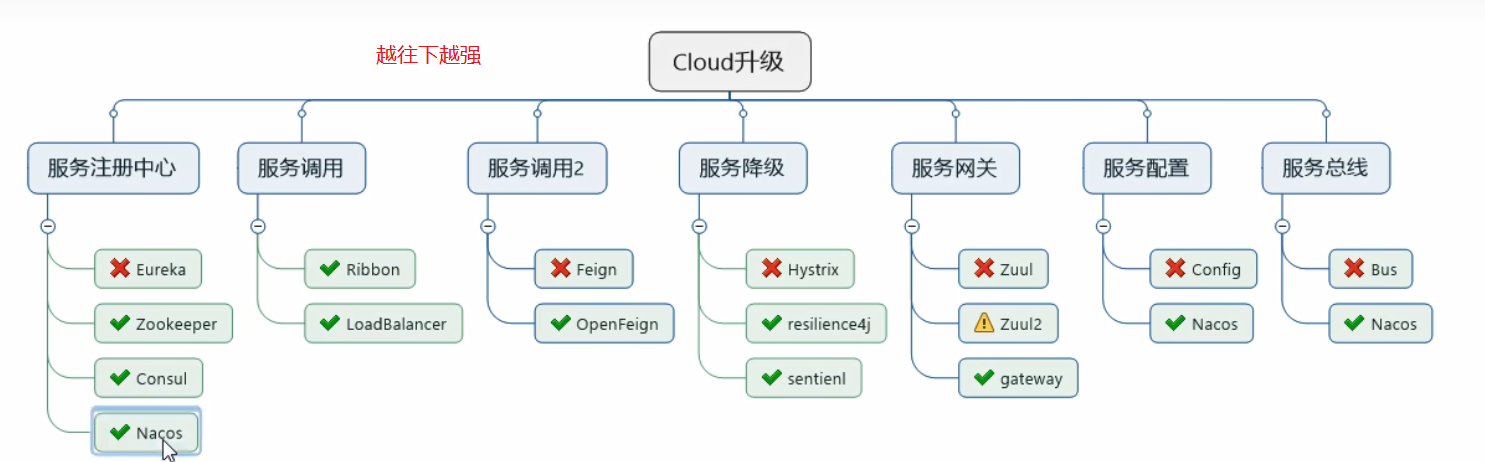
参考资料,尽量去官网
https://cloud.spring.io/spring-cloud-static/Hoxton.SR1/reference/htmlsingle/
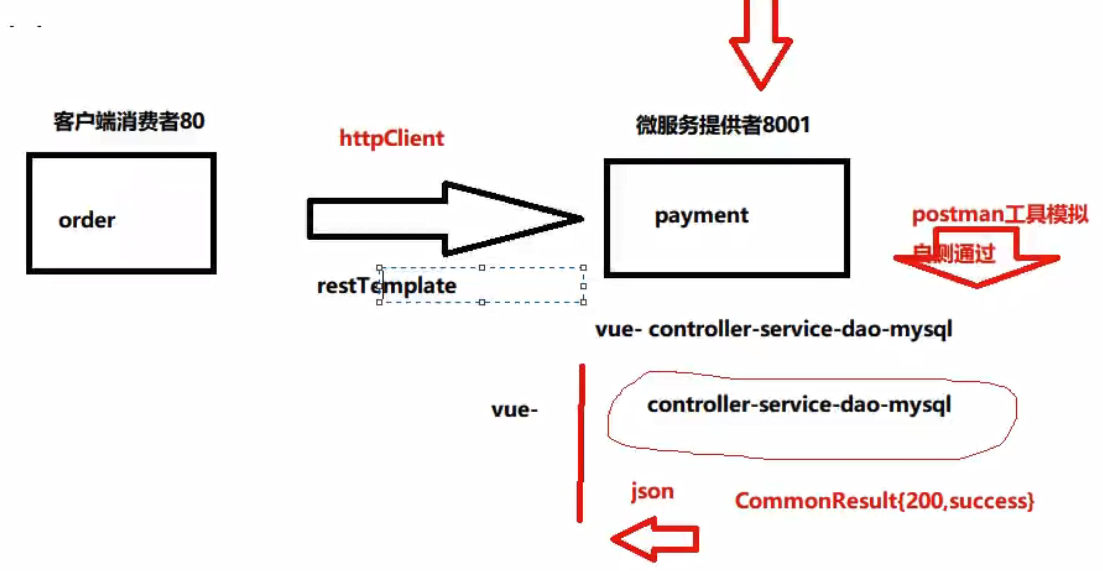
Demo工程建造
写一个下图的Hello World
构建父工程,后面的项目模块都在此工程中:
设置编码:Settings -> File Encodings
注解激活: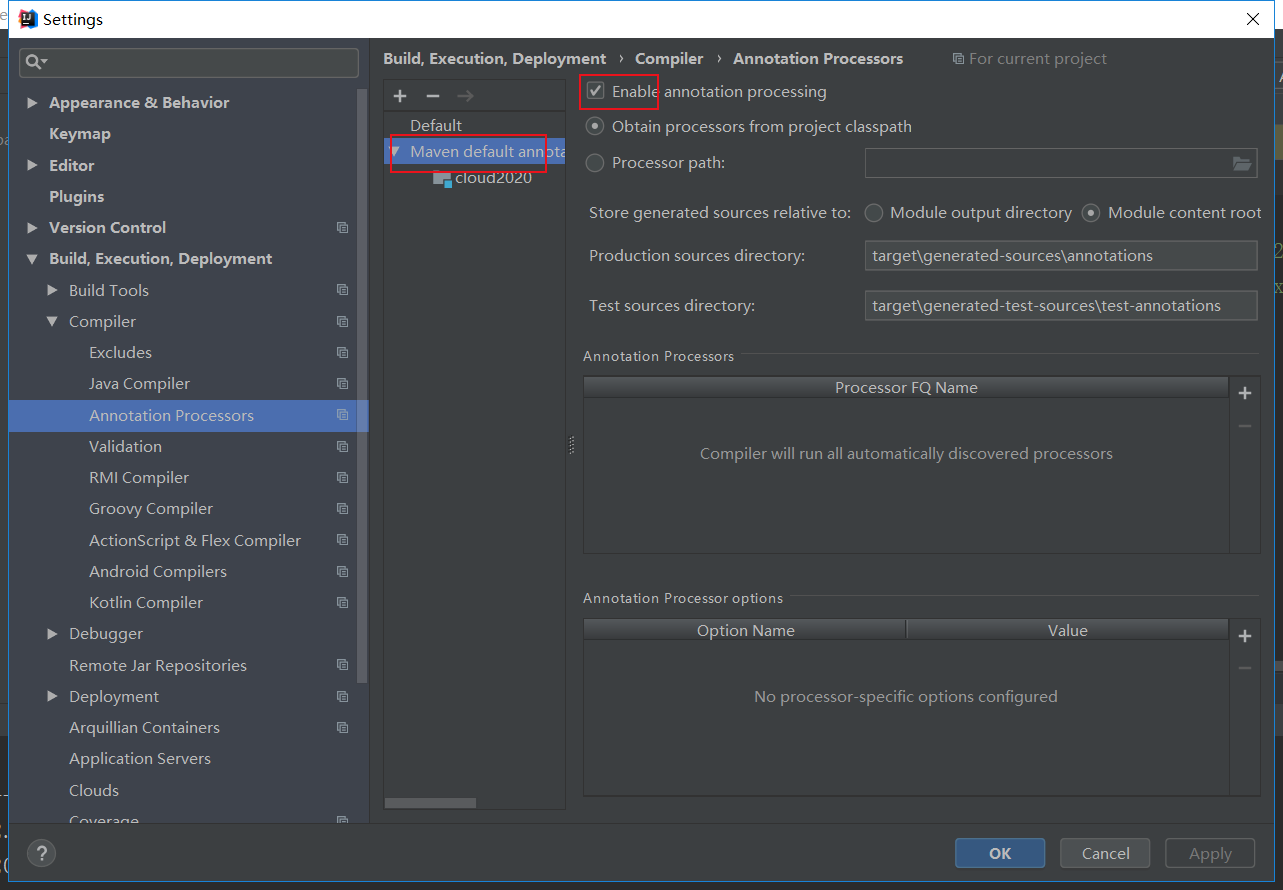
Java版本确定:

父工程pom配置
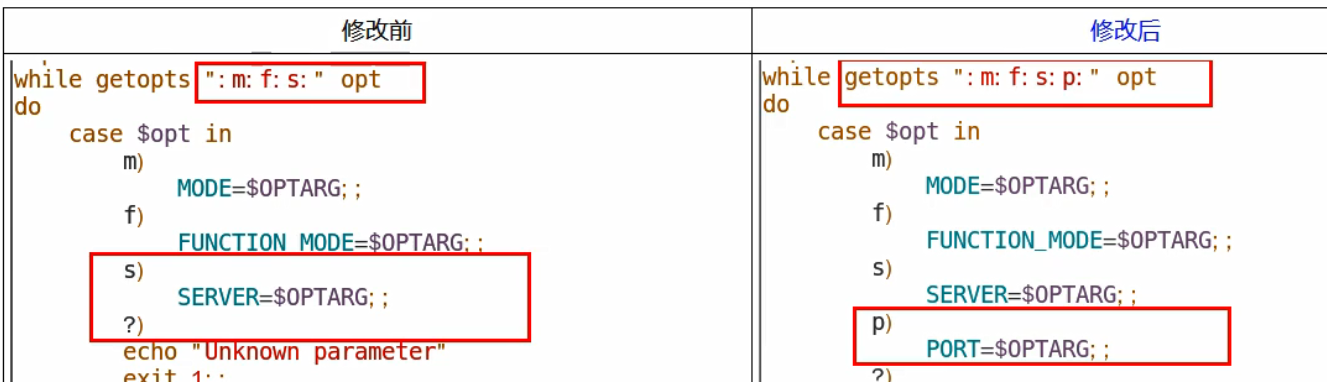
1 |
|
上面配置的解释:
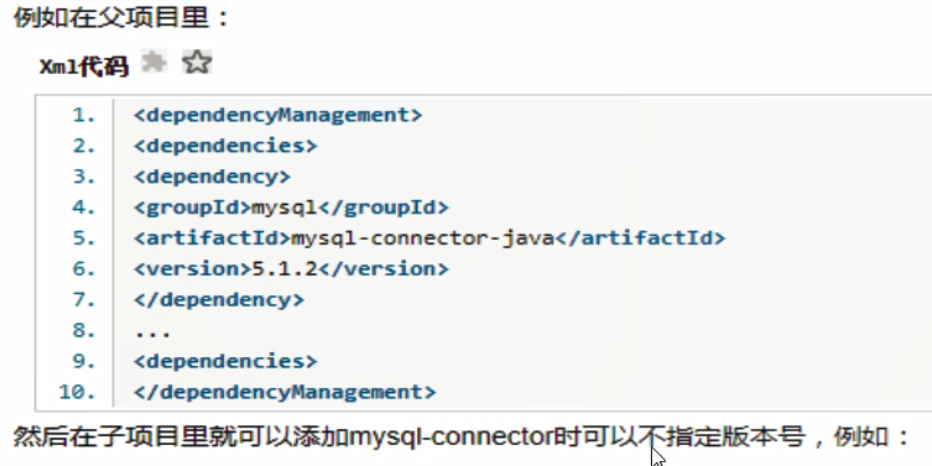
首先要加
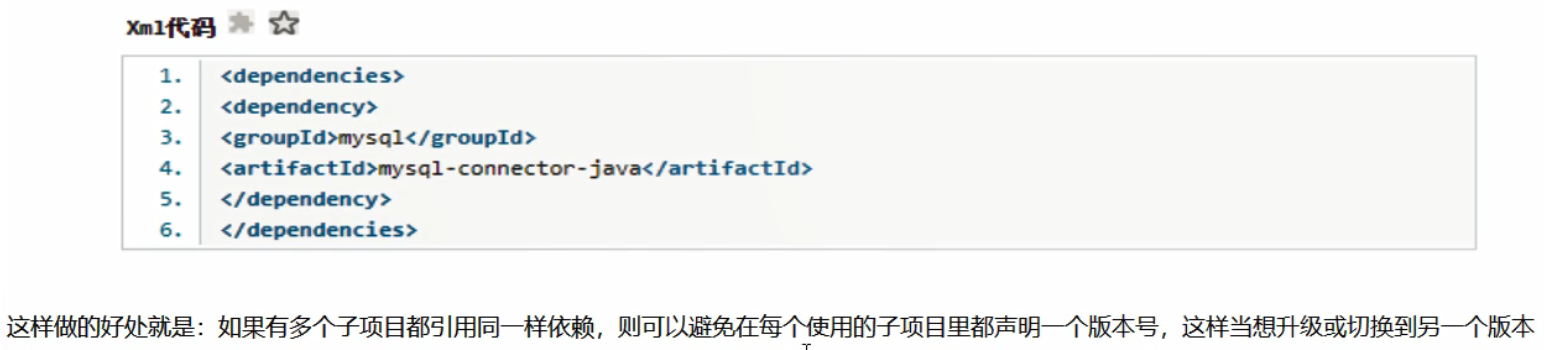
聚合版本依赖,dependencyManagement 只声明依赖,并不实现引入,所以子项目还需要写要引入的依赖。


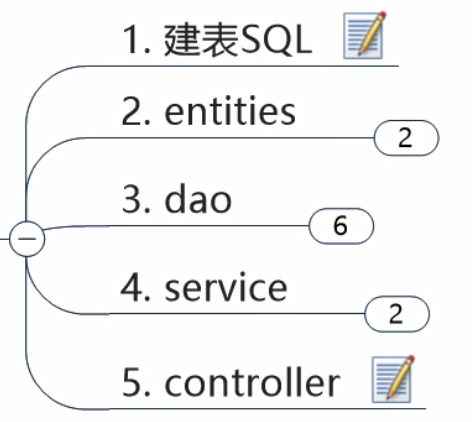
第一个微服务架构
- 建模块 module
- 改 pom
- 写yml
- 主启动
- 业务类
提供者
cloud-provider-payment8001 子工程的pom文件:
1 |
|
这里面的 lombok 这个包,引入以后,实体类不用再写set 和 get
可以如下写实体类:
2
3
4
5
6
7
8
9
10
11
12
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
public class Payment implements Serializable {
private Integer id;
private String serial;
}
cloud-provider-payment8001 子工程的yml文件:
1 | server: |
cloud-provider-payment8001 子工程的主启动类:
1 | package com.dkf.springcloud; |
下面的常规操作:
mybatis的mapper文件和service层代码不写了,下面记录一个特殊的Entity类和Controller
CommonResult:
1 | package com.dkf.springcloud.entities; |
Controller:
1 | package com.dkf.springcloud.controller; |
不但编译有个别地方会报错,启动也会报错,但是测试两个接口都是没问题的,推测启动报错是因为引入了下面才会引入的jar包,目前不影响。
热部署配置
- 具体模块里添加Jar包到工程中,上面的pom文件已经添加上了
1 | <dependency> |
- 添加plus到父工程的pom文件中:上面也已经添加好了
1 | <build> |
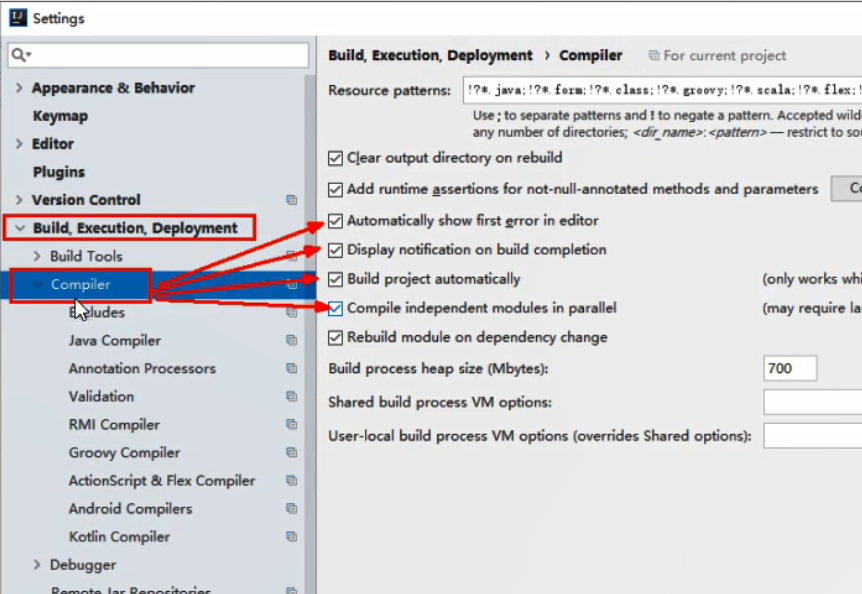
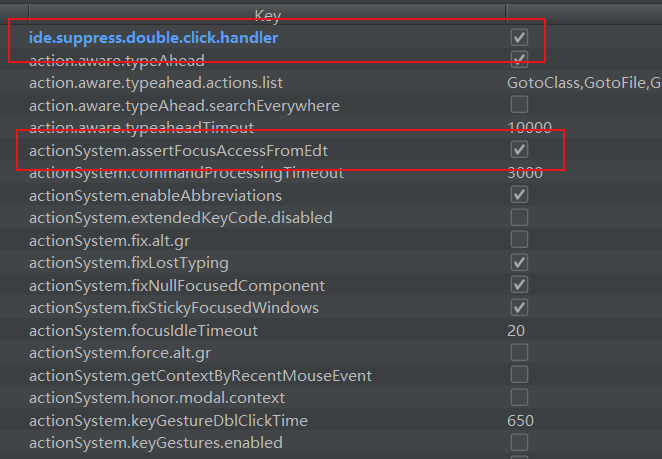
shift + ctrl + alt + / 四个按键一块按,选择Reg项,打开如下选项:
注:开发阶段才能使用热部署,上线了需要将热部署关闭
消费者
消费者现在只模拟调用提供者的Controller方法,没有持久层配置,只有Controller和实体类
当然也要配置主启动类和启动端口
pom文件:
1 |
|
把CommonResult 和 Payment 两个 实体类也创建出来
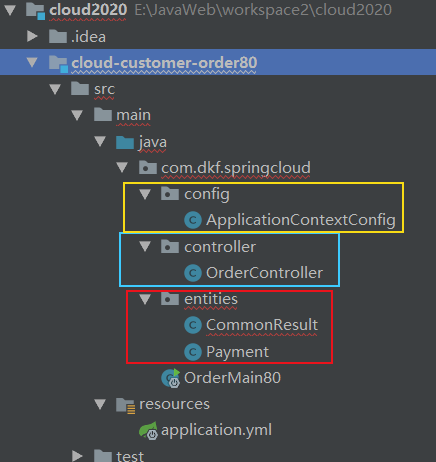
ApplicationContextConfig 内容:
1 | package com.dkf.springcloud.config; |
Controller :
1 | package com.dkf.springcloud.controller; |
如果 runDashboard 控制台没有出来,右上角搜索 即可
工程重构
上面 两个子项目,有多次重复的 导入 jar,和重复的 Entity 实体类。可以把 多余的部分,加入到一个独立的模块中,将这个模块打包,并提供给需要使用的 module
- 新建一个 cloud-dkf-commons 子模块
- 将 entities 包里面的实体类放到这个子模块中,也将 pom 文件中,重复导入的 jar包放到这个新建的 模块的 pom 文件中。如下:
1 |
|
将此项目打包 install 到 maven仓库。
- 将 提供者 和 消费者 两个项目中的 entities 包删除,并删除掉加入到 cloud-api-commons 模块的 依赖配置。
- 将 打包到 maven 仓库的 cloud-api-commons 模块,引入到 提供者 和 消费者的 pom 文件中,如下所示
1 | <dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity --> |
完成!
服务注册中心
如果是上面只有两个微服务,通过 RestTemplate ,是可以相互调用的,但是当微服务项目的数量增大,就需要服务注册中心。目前没有学习服务调用相关技术,使用 SpringCloud 自带的 RestTemplate 来实现RPC
Eureka
官方停更不停用,以后可能用的越来越少。
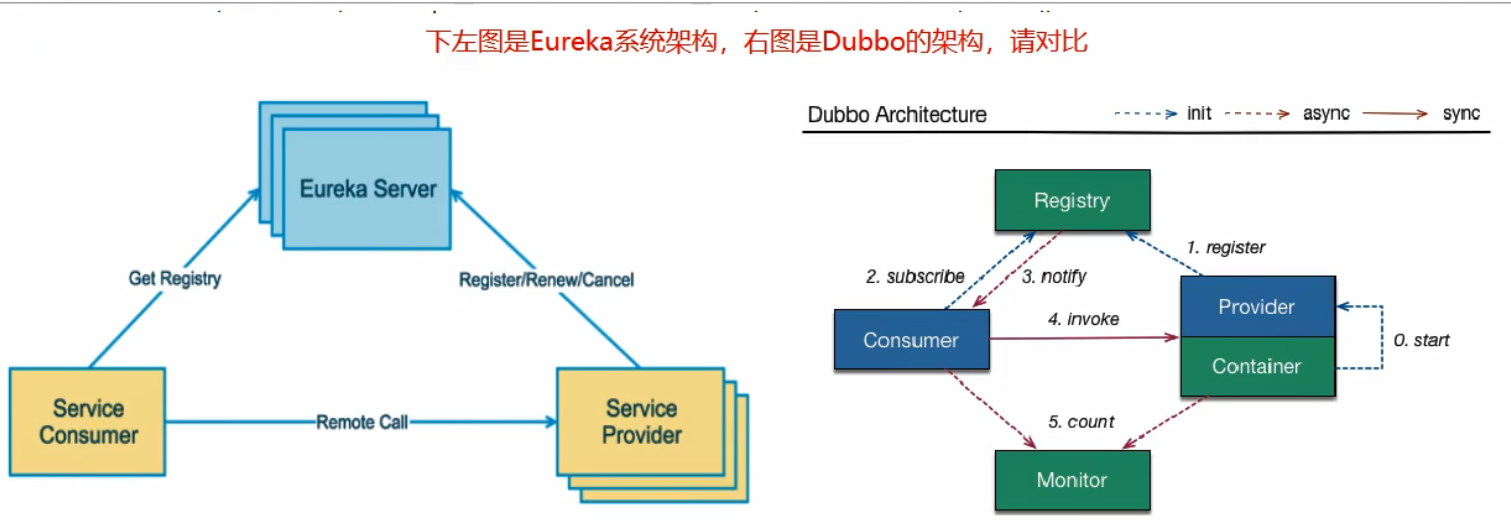
概念和理论
它是用来服务治理,以及服务注册和发现,服务注册如下图:


版本说明:
Server模块
server 模块使用 7001端口,下面是pom文件需要的依赖:
1 | <artifactId>cloud-eureka-server7001</artifactId> |
下面配置 yml 文件:
1 | server: |
最后写主启动类,如果启动报错,说没有配置 DataSource ,就在 主启动类的注解加上 这样的配置:
1 | // exclude :启动时不启用 DataSource的自动配置检查 |
启动测试,访问 7001 端口
提供者
这里的提供者,还是使用 上面的 cloud-provider-payment8001 模块,做如下修改:
- 在 pom 文件的基础上引入 eureka 的client包,pom 的全部依赖如下所示:
1 | <artifactId>cloud-provider-payment8001</artifactId> |
- 主启动类 加上注解 : @EnableEurekaClient
- yml 文件添加关于 Eureka 的配置:
1 | eureka: |
应用名称:
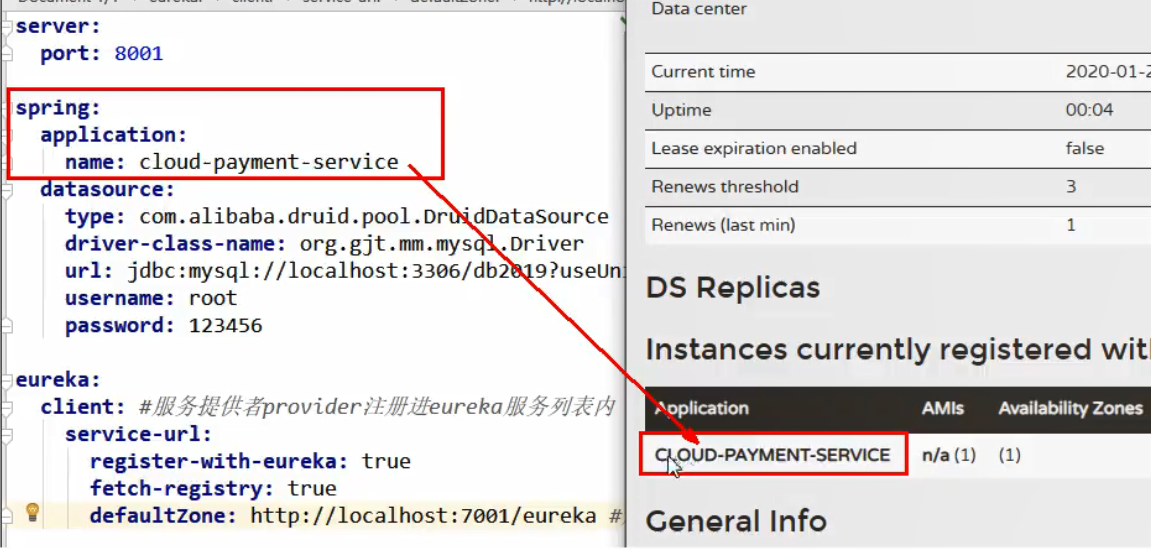
消费者
这里的消费者 也是上面 的 cloud-customer-order80 模块
- 修改 pom 文件,加入Eureka 的有关依赖, 全部 pom 依赖如下:
1 | <artifactId>cloud-customer-order80</artifactId> |
- 主启动类 加上注解 : @EnableEurekaClient
- yml 文件必须添加的内容:
1 | eureka: |
Eureka 集群
Eureka 集群的原理,就是 相互注册,互相守望
模拟多个 Eureka Server 在不同机器上 : 进入C:\Windows\System32\drivers\etc\hosts 添加如下:
127.0.0.1 eureka7001.com
127.0.0.1 eureka 7002.com
现在创建 cloud-eureka-server7002 ,也就是第二个 Eureka 服务注册中心,pom 文件和 主启动类,与第一个Server一致。
现在修改这两个 Server 的 yml 配置:
7001 端口的Server yml文件:
1 | server: |
7002 端口的Server yml文件:
1 | server: |
eureka.instance.hostname 才是启动以后 本 Server 的注册地址,而 service-url 是 map 类型,只要保证 key:value 格式就行,它代表 本Server 指向了那些 其它Server 。利用这个,就可以实现Eureka Server 相互之间的注册,从而实现集群的搭建。
将 提供者 和 消费者 注册进两个Eureka Server 中,下面是 消费者和提供者的 yml 文件关于Eureka的配置:
1 | eureka: |
从这里可以看出,也可以使用列表形式进行Server之间的关联注册。
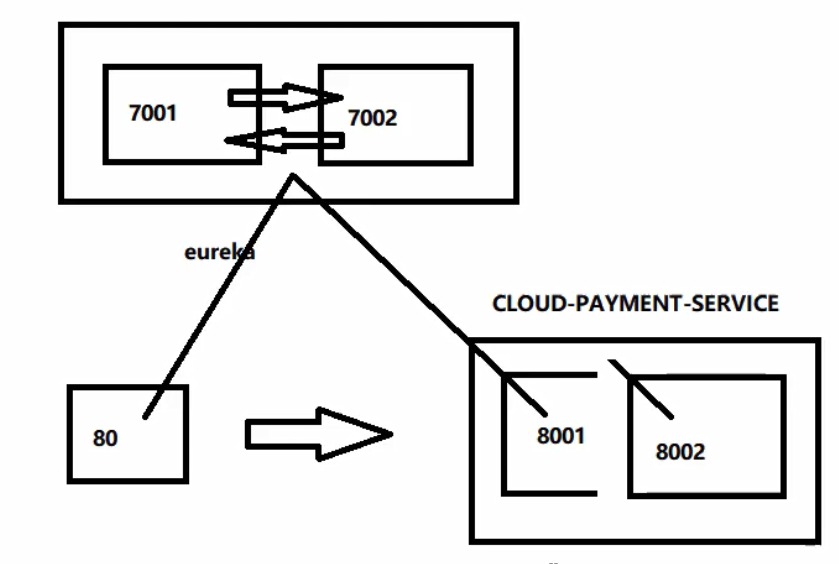
提供者集群
为提供者,即 cloud-provider-payment8001 模块创建集群,新建模块为 cloud-provider-payment8002
最终实现:
注意在 Controller 返回不同的消息,从而区分者两个提供者的工作状态。
其余配置都一致,需要配置集群的配置如下:
配置区别:只要保证消费者项目对服务注册中心提供的名称一致,即完成集群。
1 | server: |
消费者的配置:就是消费者如何访问 由这两个提供者组成的集群
Eureka Server 上的提供者的服务名称如下:
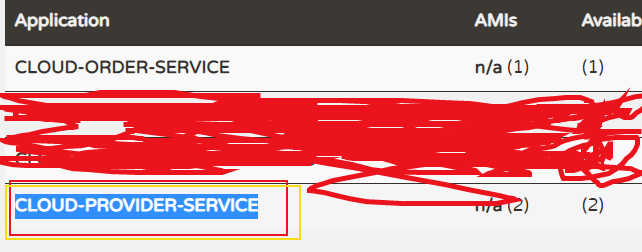
1 |
|
还有,消费者里面对RestTemplate配置的config文件,需要更改成如下:(就是加一个注解 @LoadBalanced)
1 | package com.dkf.springcloud.config; |
测试,完成!
actuator信息配置
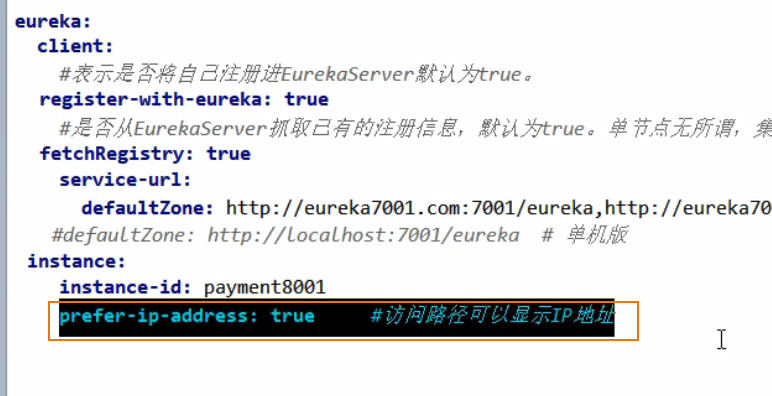
修改 在Eureka 注册中心显示的 主机名:
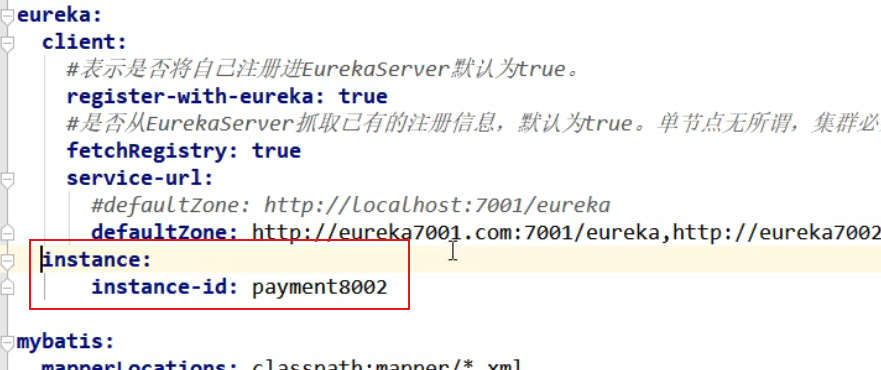

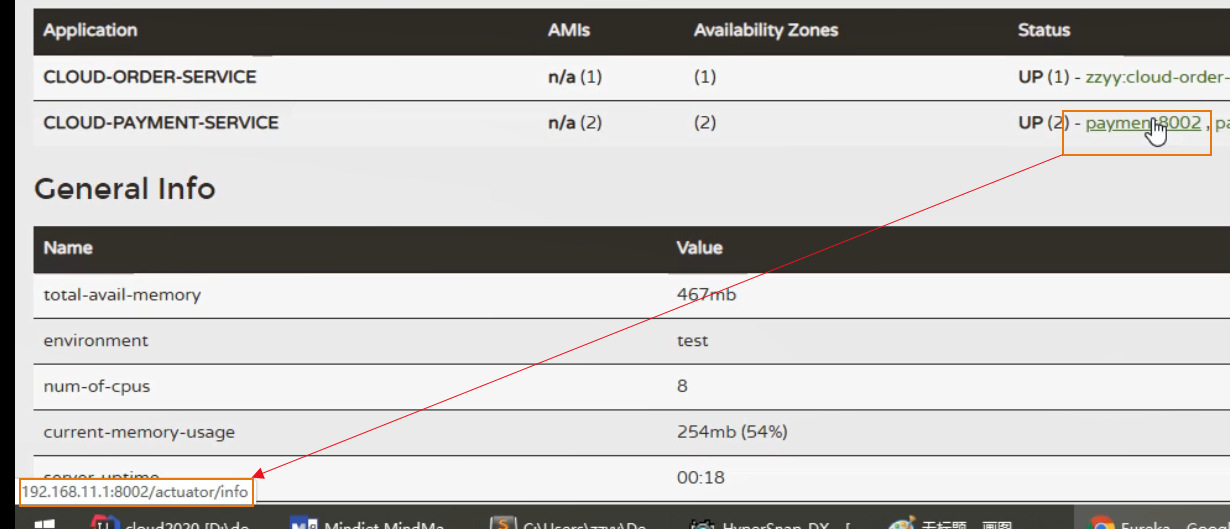
显示微服务所在 的主机地址:
服务发现Discovery
对于注册进eureka里面的微服务,可以通过服务发现来获得该服务的信息
- 在主启动类上添加注解:@EnableDiscoveryClient
- 在 Controller 里面打印信息:
1 |
|
Eureka 自我保护机制


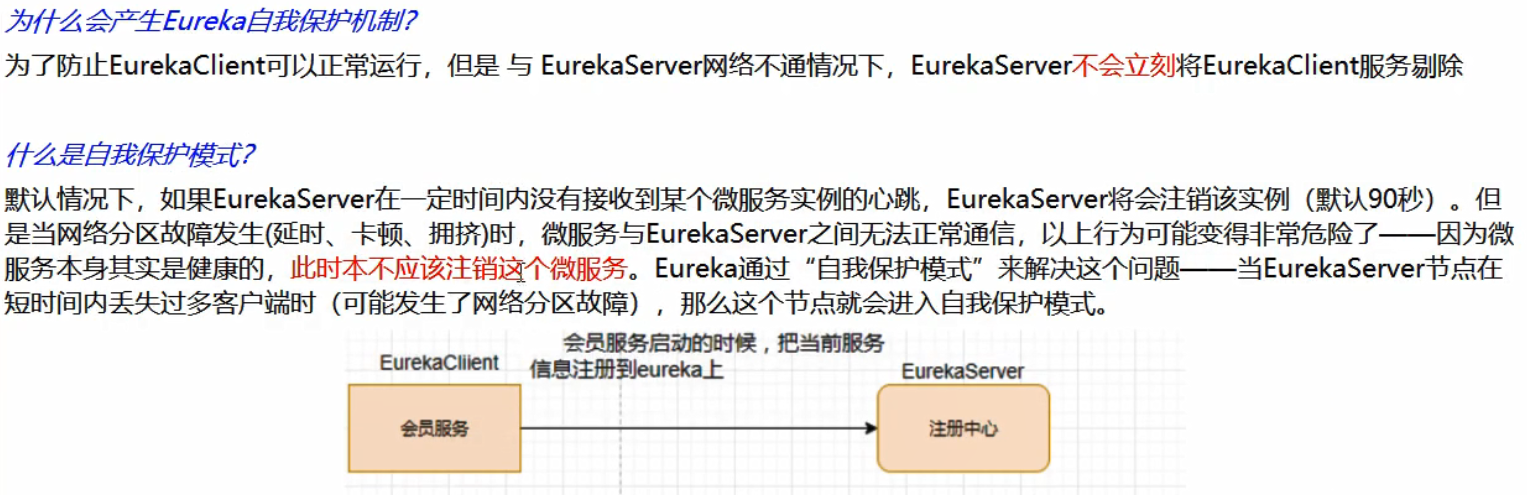
禁止自我保护:
在 Eureka Server 的模块中的 yml 文件进行配置:
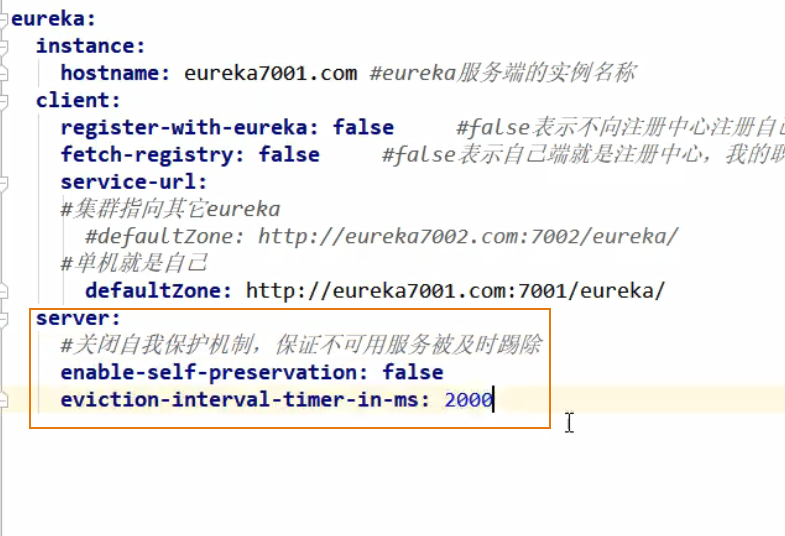
修改 Eureka Client 模块的 心跳间隔时间:

Zookeeper
springCloud 整合 zookeeper
提供者
创建一个提供者,和之前的一样即可,使用 8004端口
pom文件如下:
1 | <artifactId>cloud-provider-payment8004</artifactId> |
主启动类:
1 | import org.springframework.boot.SpringApplication; |
Controller 打印信息:
1 |
|
如果 zookeeper 的版本和导入的jar包版本不一致,启动就会报错,由jar包冲突的问题。
解决这种冲突,需要在 pom 文件中,排除掉引起冲突的jar包,添加和服务器zookeeper版本一致的 jar 包,
但是新导入的 zookeeper jar包 又有 slf4j 冲突问题,于是再次排除引起冲突的jar包
1 | <!--springcloud 整合 zookeeper 组件--> |
yml文件:
1 | server: |
启动测试:

消费者
创建测试zookeeper作为服务注册中心的 消费者 模块 cloud-customerzk-order80
主启动类、pom文件、yml文件和提供者的类似
config类,注入 RestTemplate
1 |
|
controller层也是和之前类似:
1 |
|
关于 zookeeper 的集群搭建,目前使用较少,而且在 yml 文件中的配置也是类似,以列表形式写入 zookeeper 的多个地址即可,而且zookeeper 集群,在 hadoop的笔记中也有记录。总而言之,只要配合zookeeper集群,以及yml文件的配置就能完成集群搭建
Consul
consul也是服务注册中心的一个实现,是由go语言写的。官网地址: https://www.consul.io/intro
中文地址: https://www.springcloud.cc/spring-cloud-consul.html
功能:

安装并运行
下载地址:https://www.consul.io/downloads.html
打开下载的压缩包,只有一个exe文件,实际上是不用安装的,在exe文件所在目录打开dos窗口使用即可。
使用开发模式启动:consul agent -dev
访问8500端口,即可访问首页
提供者
新建提供者模块:cloud-providerconsul-service8006
pom 文件:
1 | <artifactId>cloud-providerconsul-service8006</artifactId> |
yml 文件:
1 | server: |
主启动类:
1 |
|
controller也是简单的写一下就行。
消费者
新建 一个 在82端口的 消费者模块。pom和yml和提供者的类似,主启动类不用说,记得注入RestTemplate
controller层:
1 |
|
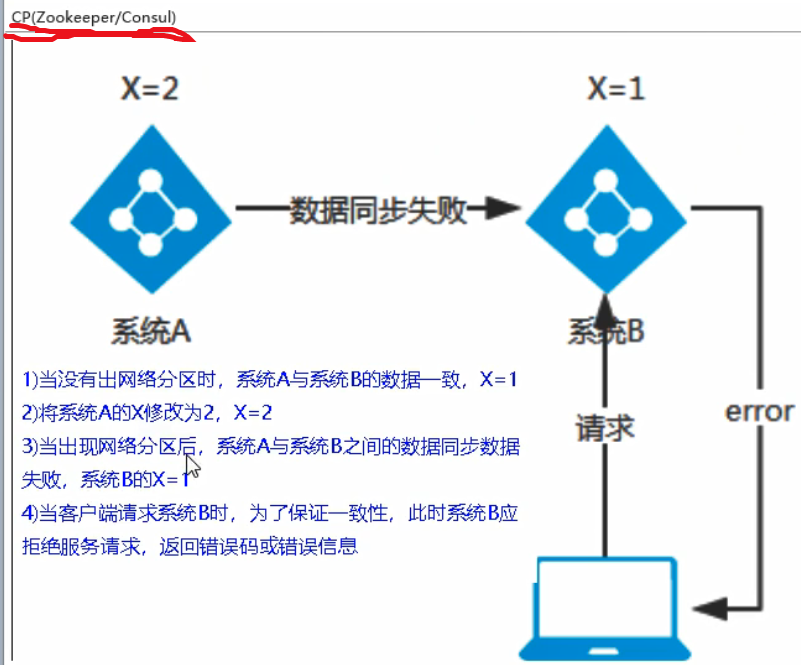
三个注册中心异同点
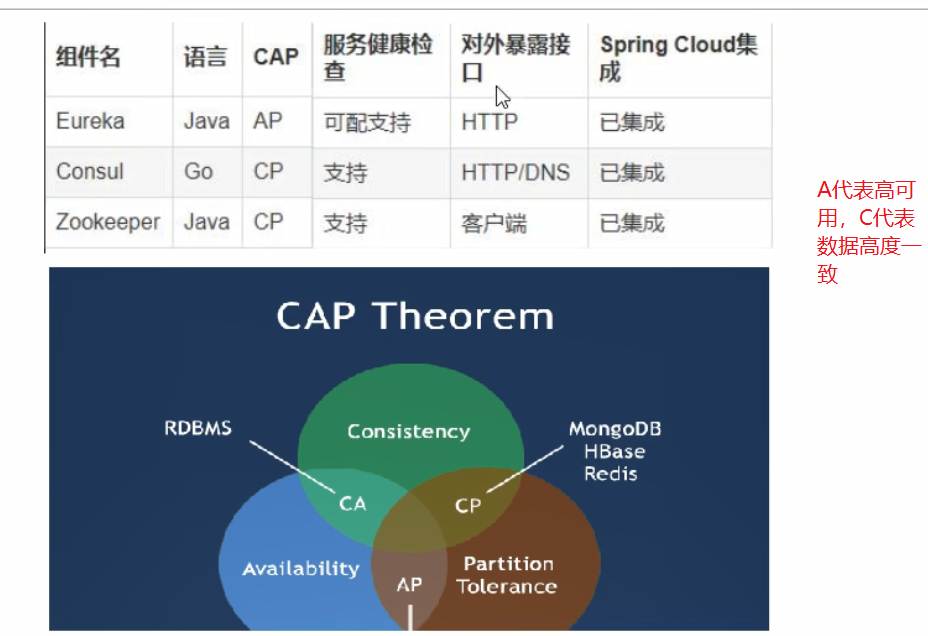


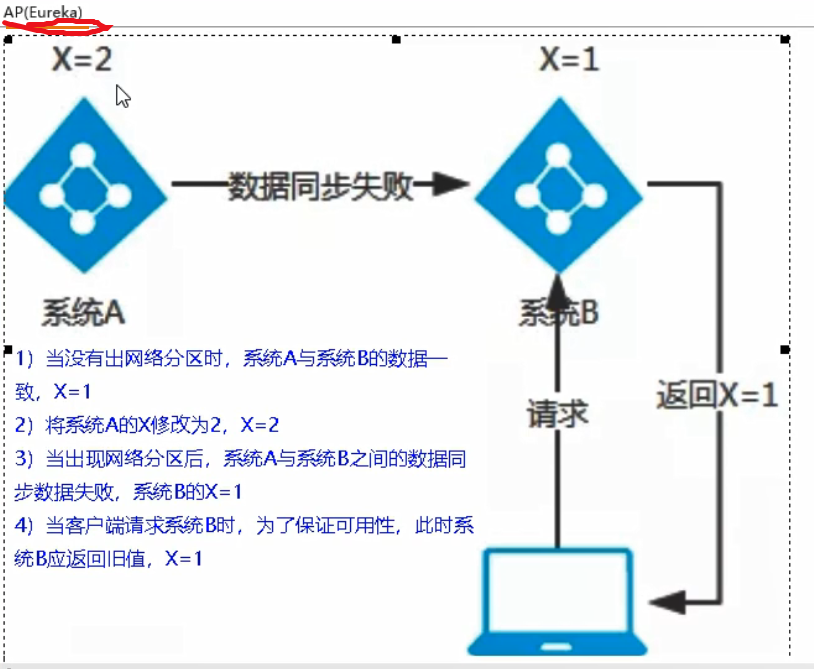
AP强调高可用:
CP强调一致性:
服务调用
都是使用在 client端,即有 ”消费者“ 需求的模块中。
Ribbon
我们这里提前启动好之前在搭建的 eureka Server 集群(5个模块)
简介


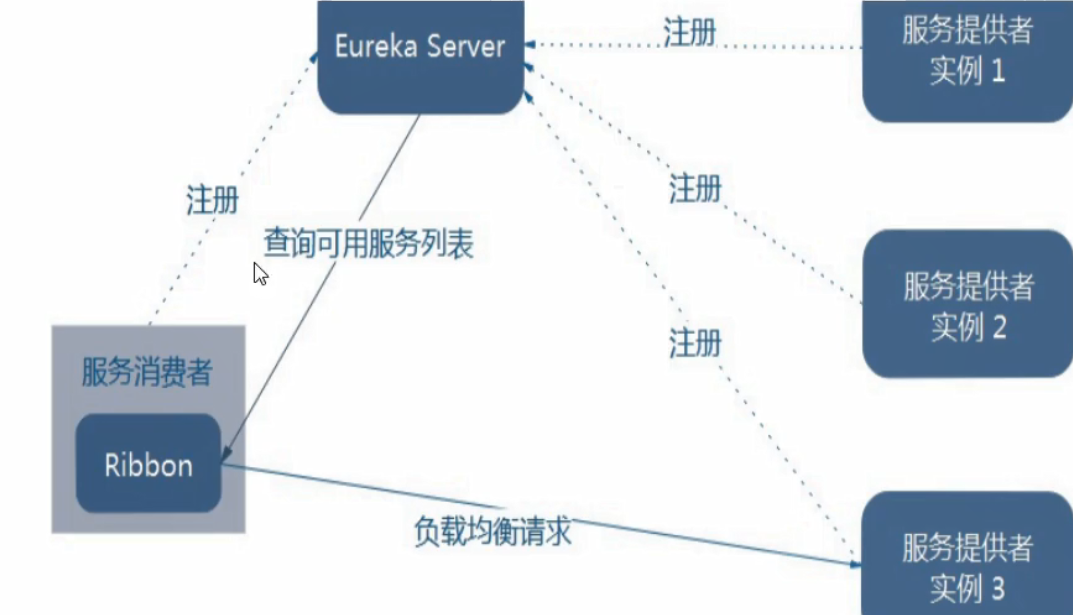

上面在eureka时,确实实现了负载均衡机制,那是因为 eureka-client包里面自带着ribbon:
一句话,Ribbon 就是 负载均衡 + RestTemplate 调用。实际上不止eureka的jar包有,zookeeper的jar包,还有consul的jar包都包含了他,就是上面使用的服务调用。
如果自己添加,在 模块的 pom 文件中引入:
1 | <dependency> |
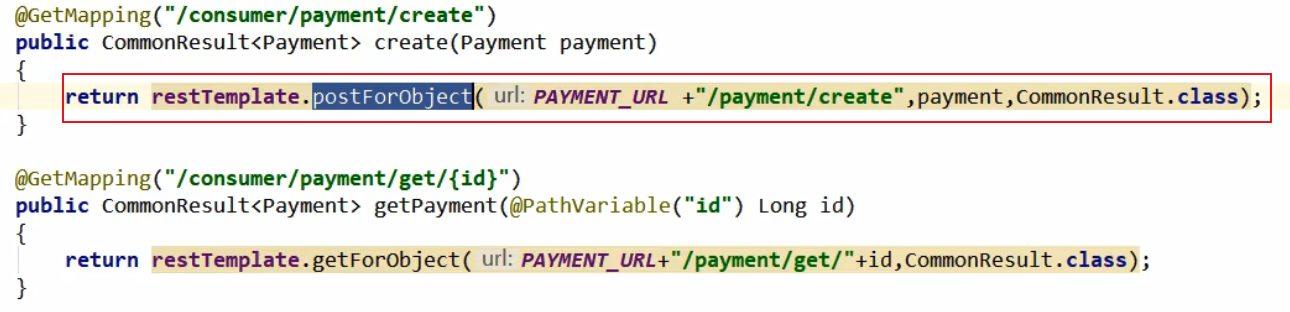
对于RestTemplate 的一些说明:
有两种请求方式:post和get ,还有两种返回类型:object 和 Entity
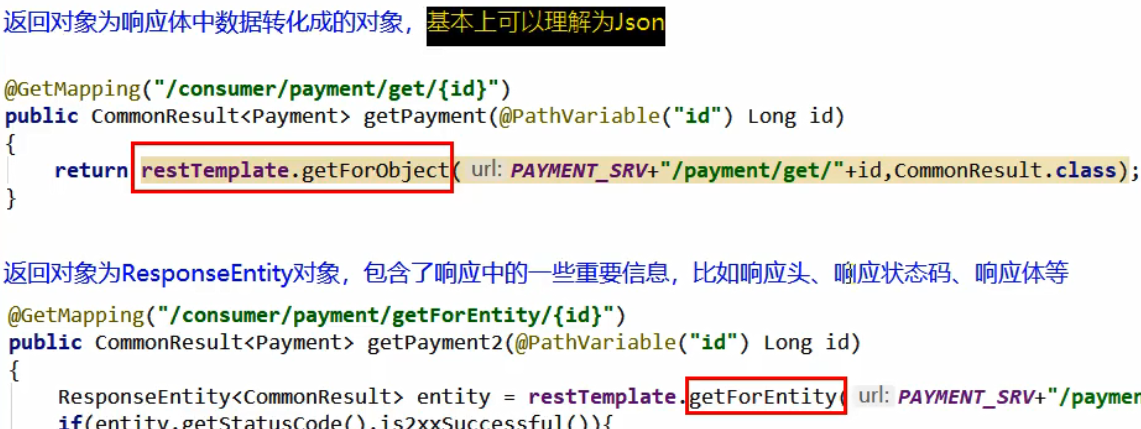
RestTemplate 的 ForEntity 相比 ForObject特殊的地方:

就是 如果使用 ForObject 得到的就是提供者返回的对象,而如果要使用 ForEntity 得到时 ResponstEntity对象,使用getBody()才能得到提供者返回的数据。
1 | //使用forEnriry示例: |
负载均衡
Ribbon 负载均衡规则类型:

配置负载均衡规则:

注意上面说的,而Springboot主启动类上的 @SpringBootApplication 注解,相当于加了@ComponentScan注解,会自动扫描当前包及子包,所以注意不要放在SpringBoot主启动类的包内。
创建包Myrule,在这个包下新建 MySelfRule类:
1 | package com.dkf.myrule; |
然后在主启动类上添加如下注解 @RibbonClient:
1 | package com.dkf.springcloud; |
轮询算法原理
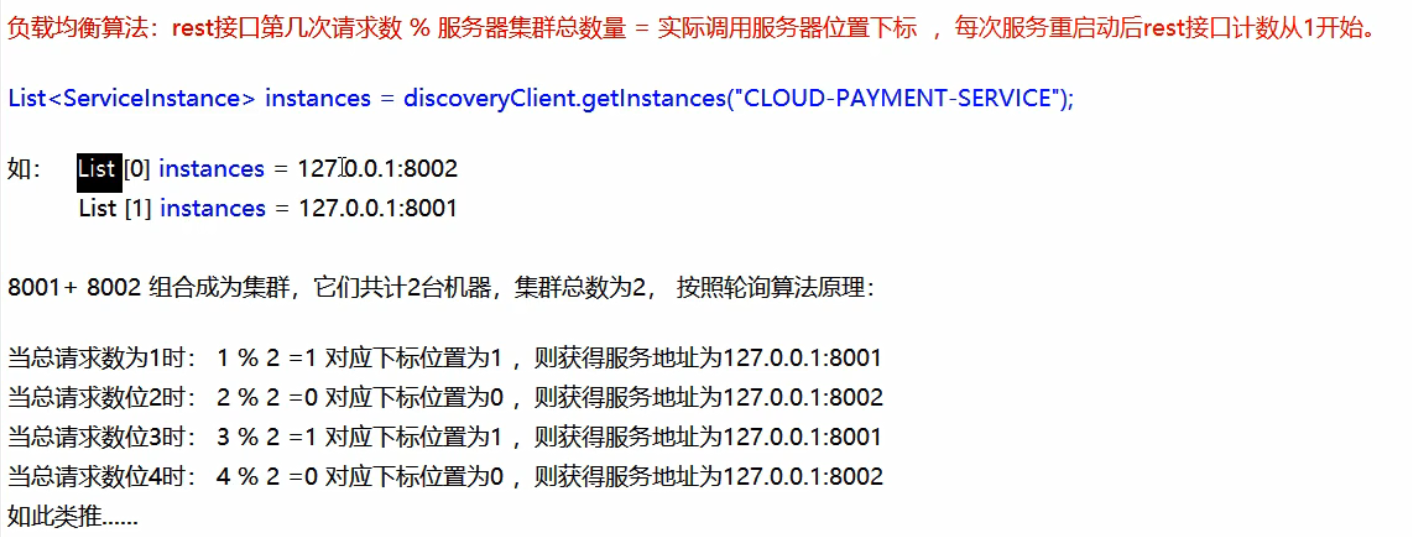
手写RoundRobinRule
根据RoundRobinRule源码手写一个类似的轮换算法。
思路:根据discoveryClient服务发现得到存活的服务,接着编写接口来实现根据自己写的算法得到特定的服务。
创建LoadBalancer接口:
1 | /** |
创建实现类:(运用到JUC的CAS和自旋锁)
1 | /** |
接着编写COntroller测试:
1 |
|
OpenFeign
概述
这里和之前学的dubbo很像,例如消费者的controller 可以调用提供者的 service层方法,但是不一样,它貌似只能调用提供者的 controller,即写一个提供者项目的controller的接口,消费者来调用这个接口方法,就还是相当于是调用提供者的 controller ,和RestTemplate 没有本质区别


使用
新建一个消费者募模块。feign自带负载均衡配置,所以不用手动配置
pom :
1 | <dependencies> |
主启动类:
1 |
|
新建一个service
这个service还是 customer 模块的接口,和提供者没有任何关系,不需要包类名一致。它使用起来就相当于是普通的service。
推测大致原理,对于这个service 接口,读取它某个方法的注解(GET或者POST注解不写报错),知道了请求方式和请求地址,而抽象方法,只是对于我们来讲,调用该方法时,可以进行传参等。
1 |
|
Controller层:
1 | //使用起来就相当于是普通的service。 |
超时控制
Openfeign默认超时等待为一秒,在消费者里面配置超时时间
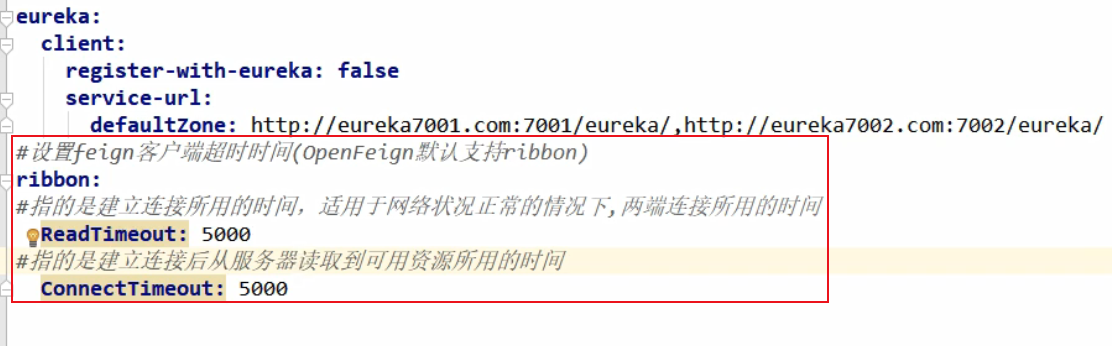
开启日志打印
首先写一个config配置类:

然后在yml文件中开启日志打印配置:

中级部分
主要是服务降级、服务熔断、服务限流的开发思想和框架实现
Hystrix 断路器
概述


服务降级:
服务器忙碌或者网络拥堵时,不让客户端等待并立刻返回一个友好提示,fallback
发生的情况:

服务熔断:

服务限流:

可见,上面的技术不论是消费者还是提供者,根据真实环境都是可以加入配置的。
案例
首先构建一个eureka作为服务中心的单机版微服务架构 ,这里使用之前eureka Server 7001模块,作为服务中心
新建 提供者 cloud-provider-hystrix-payment8001 模块:
pom 文件:
1 | <dependencies> |
下面主启动类、service、和controller代码都很简单普通。
主启动类:
1 |
|
service层:
1 |
|
controller层:
1 |
|
模拟高并发
这里使用一个新东西 JMeter 压力测试器
下载压缩包,解压,双击 /bin/ 下的 jmeter.bat 即可启动
ctrl + S 保存。
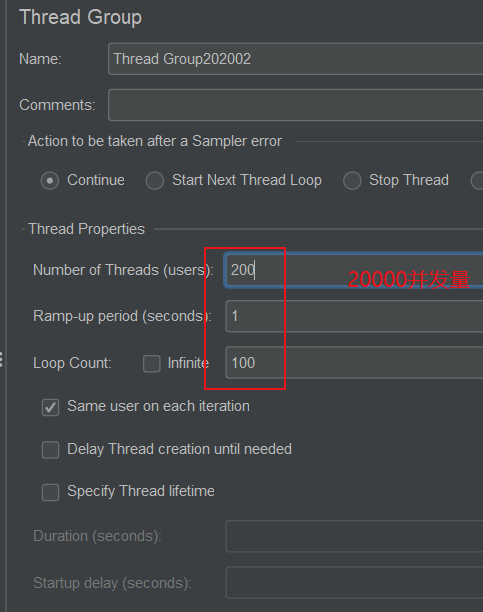
从测试可以看出,当模拟的超长请求被高并发以后,访问普通的小请求速率也会被拉低。
新建消费者 cloud-customer-feign-hystrix-order80 模块:以feign为服务调用,eureka为服务中心的模块,yml、pom等文件不再赘写。
测试可见,当启动高并发测试时,消费者访问也会变得很慢,甚至出现超时报错。
解决思路:

服务降级
一般服务降级放在客户端,即 消费者端 ,但是提供者端一样能使用。
首先提供者,即8001 先从自身找问题,设置自身调用超时的峰值,峰值内正常运行,超出峰值需要有兜底的方法处理,作服务降级fallback
首先 对 8001 的service进行配置(对容易超时的方法进行配置) :
1 |
|
主启动类添加注解: @EnableCircuitBreaker
然后对 80 进行服务降级:很明显 service 层是接口,所以我们对消费者,在它的 controller 层进行降级
1 |
|
主启动类添加注解: @EnableCircuitBreaker
完成测试! 注意,消费者降级设置的超时时间和提供者的没有任何关系,就算提供者峰值是 5 秒,而消费者峰值是 3秒,那么消费者依然报错。就是每个模块在服务降级上,都是独立的。
全局服务降级
上面的降级策略,很明显造成了代码的杂乱,提升了耦合度,而且按照这样,每个方法都需要配置一个兜底方法,很繁琐。现在将降级处理方法(兜底方法)做一个全局的配置,设置共有的兜底方法和独享的兜底方法。
问题-每个方法配置一个,解决:
1 |
|
问题-跟业务逻辑混合,解决(解耦):
在这种方式一般是在客户端,即消费者端,首先上面再controller中添加的 @HystrixCommand 和 @DefaultProperties 两个注解去掉。就是保持原来的controller
- yml文件配置
1 | server: |
- 修改service 接口:
1 | // 这里是重点 |
- fallback 指向的类:
1 | package com.dkf.springcloud.service; |
新问题,这样配置如何设置超时时间?
首先要知道 下面两个 yml 配置项:
2
3
4
5
6
7
## 为false则超时控制有ribbon控制,为true则hystrix超时和ribbon超时都是用,但是谁小谁生效,默认为true
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=1000 ## 默认值
## 熔断器的超时时长默认1秒,最常修改的参数看懂以后,所以:
只需要在yml配置里面配置 Ribbon 的 超时时长即可。注意:hystrix 默认自带 ribbon包。
2
3
ReadTimeout: xxxx
ConnectTimeout: xxx
服务熔断
实际上服务熔断 和 服务降级 没有任何关系,就像 java 和 javaScript


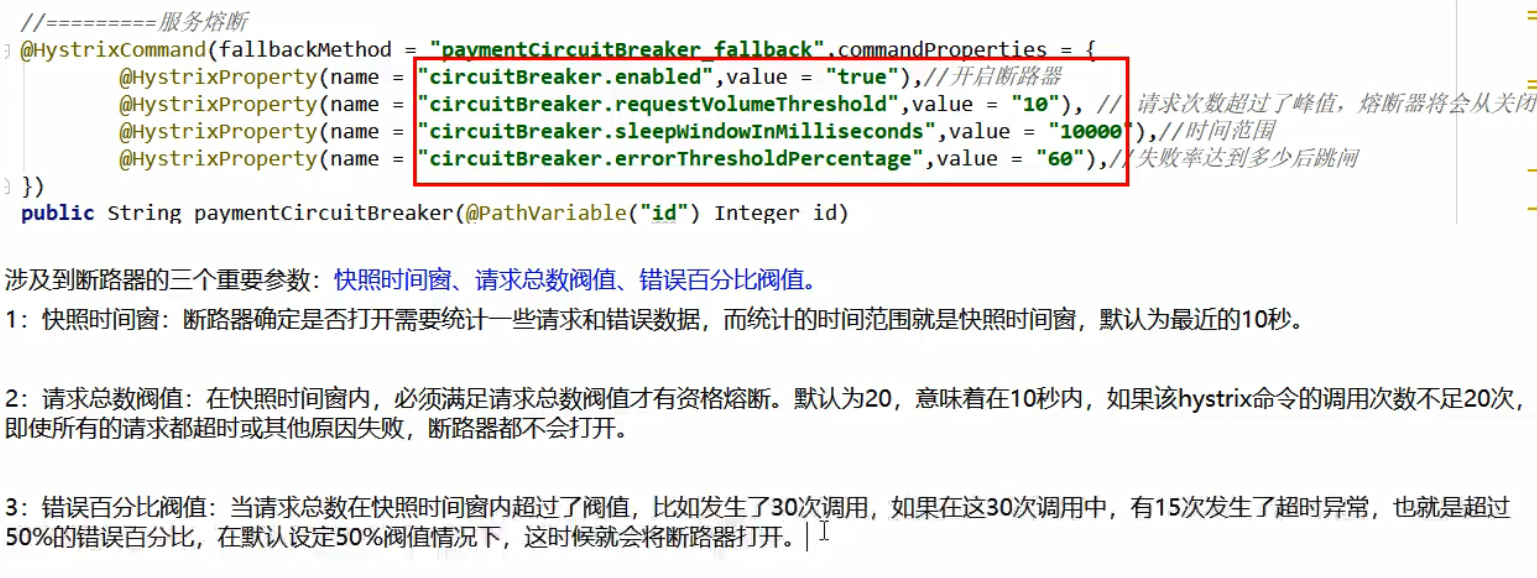
以 8001 项目为示例:
service层的方法设置服务熔断:
1 | //=====服务熔断 |
controller:
1 | //====服务熔断 |
关于解耦以后的全局配置说明:
例如上面提到的全局服务降级,并且是feign+hystrix整合,即 service 实现类的方式,如何做全局配置?
上面有 做全局配置时,设置超时时间的方式,我们可以从中获得灵感,即在yml文件中 进行熔断配置:
2
3
4
5
6
7
8
command:
default:
circuitBreaker:
enabled: true
requestVolumeThreshold: 10
sleepWindowInMilliseconds: 10000
errorThresholdPercentage: 60
Hystrix DashBoard

新建模块 cloud-hystrix-dashboard9001 :
pom 文件:
1 | <dependencies> |
yml文件只需要配置端口号,主启动类加上这样注解:@EnableHystrixDashboard
启动测试:访问 http://ocalhost:9001/hystrix
监控实战
下面使用上面 9001 Hystrix Dashboard 项目,来监控 8001 项目 Hystrix 的实时情况:
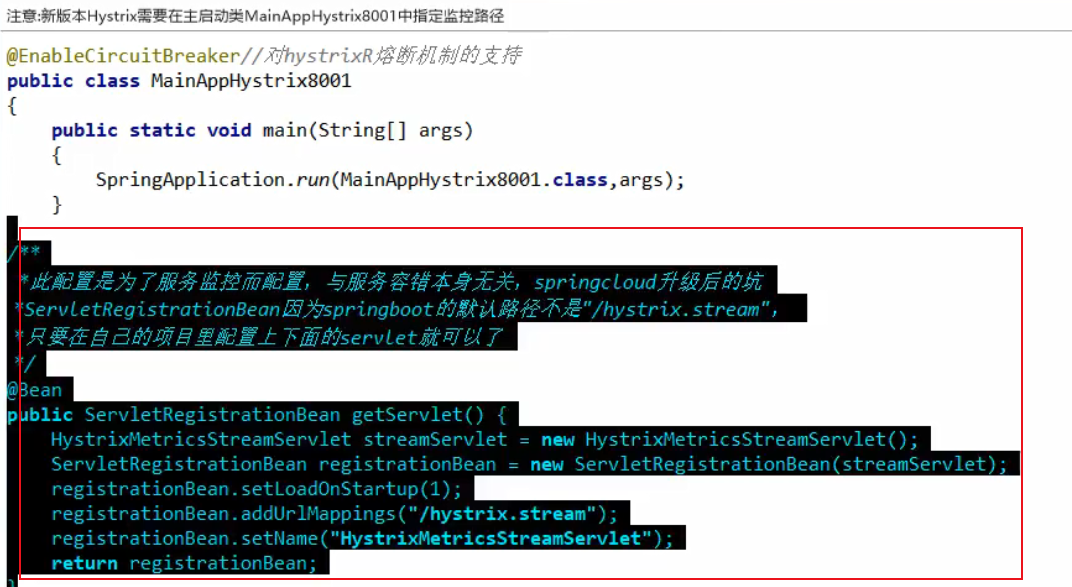
1 |
|


服务网关
Gateway
开发可参考 https://docs.spring.io/ 官网文档
简介



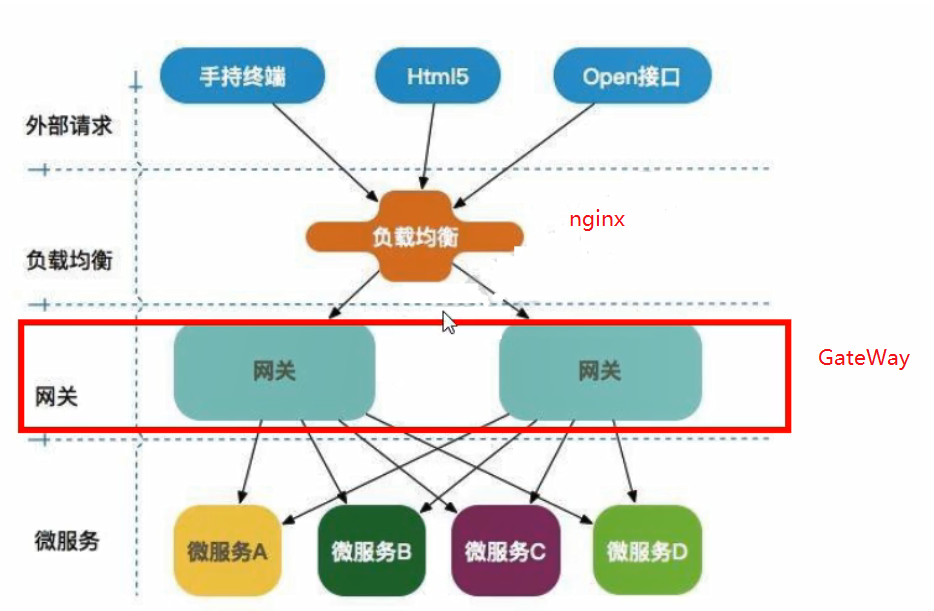
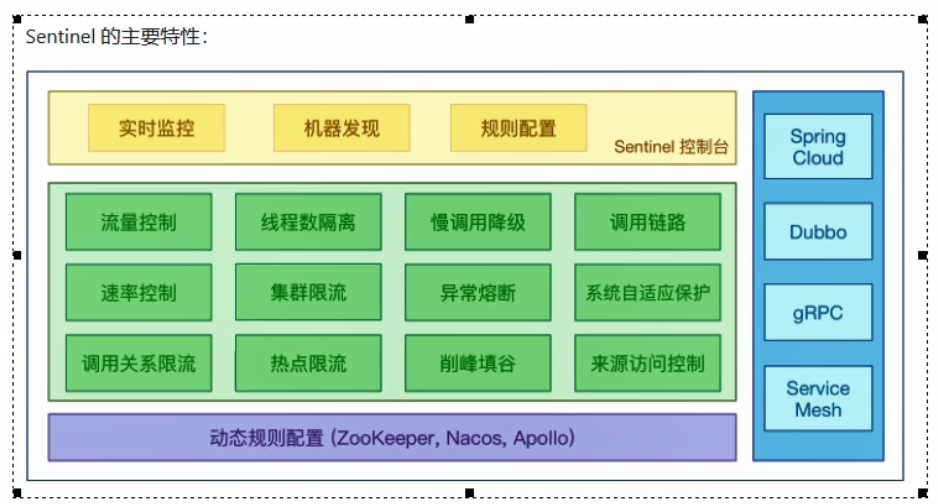
Gateway特性:

三大核心概念:

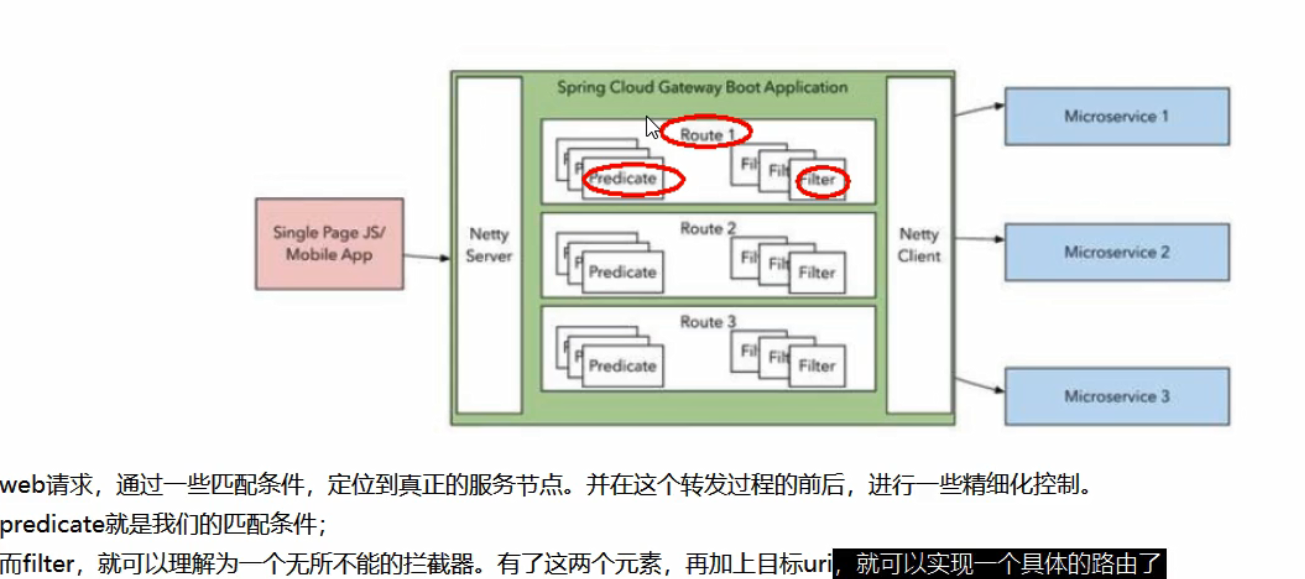
入门配置
新建模块 cloud-gateway-gateway9527
现在实现,通过Gateway (网关) 来访问其它项目,这里选择之前8001项目,要求注册进Eureka Server 。其它没要求。
pom文件:
1 | <dependencies> |
yml文件:
1 | server: |
主启动类,很普通,没有特殊的配置:
1 |
|
访问测试:1 启动eureka Server,2 启动 8001 项目,3 启动9527(Gateway项目)
可见,当我们访问 http://localhost:9527/payment/get/1 时,即访问网关地址时,会给我们转发到 8001 项目的请求地址,以此作出响应。
上面是以 yml 文件配置的路由,也有使用config类配置的方式:
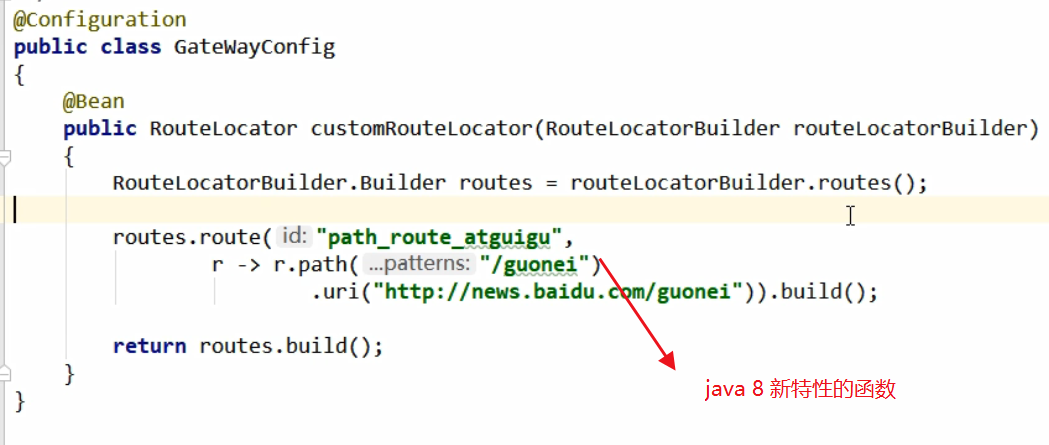
动态配置
这里所谓的动态配置就是利用服务注册中心,来实现 负载均衡 的调用 多个微服务。注意,这是GateWay 的负载均衡
对yml进行配置:
1 | spring: |
下面可以开启 8002 模块,并将它与8001同微服务名,注册到 Eureka Server 进行测试。
Predicate
注意到上面yml配置中,有个predicates 属性值。
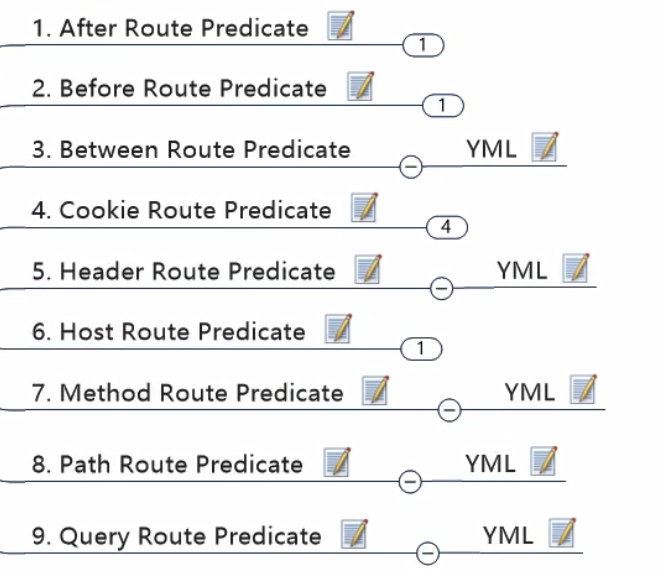
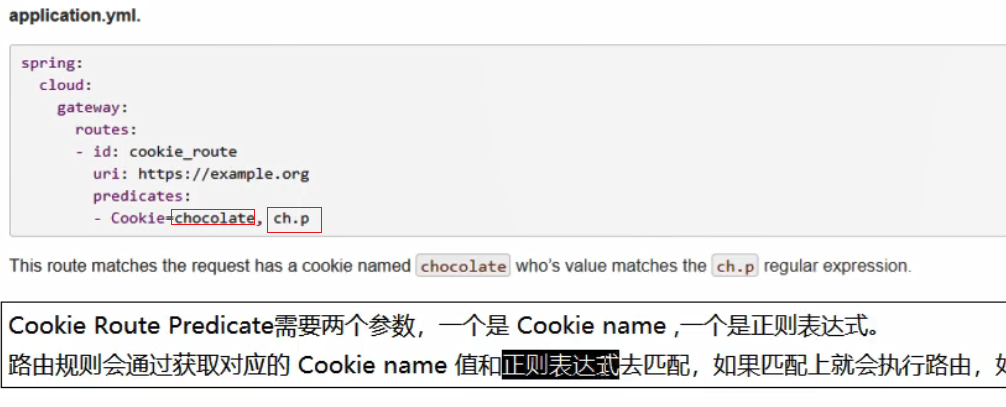
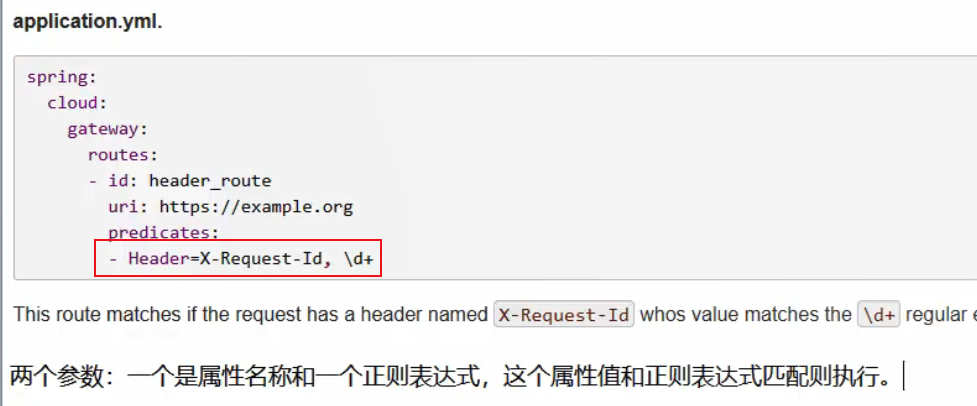
具体使用:

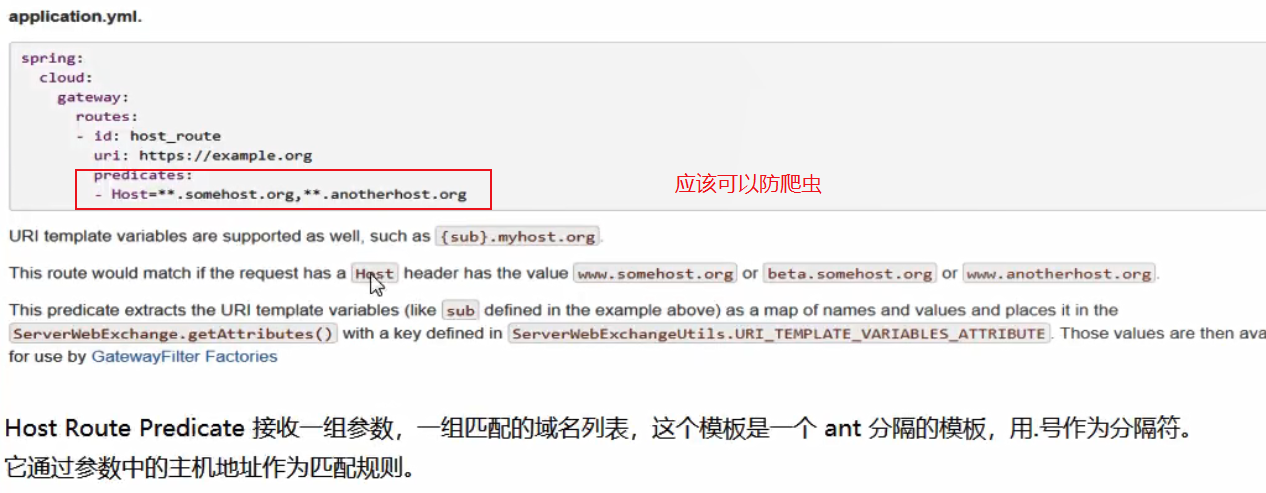
放爬虫思路,前后端分离的话,只限定前端项目主机访问,这样可以屏蔽大量爬虫。
例如我加上: - Host=localhost: 代表允许任何端口
就只能是主机来访
配置错误页面:
注意,springboot默认/static/error/ 下错误代码命名的页面为错误页面,即 404.html
而且不需要导入额外的包,Gateway 里面都有。
Filter
主要是配置全局自定义过滤器,其它的小配置具体看官网吧
自定义全局过滤器配置类:(主要实现GlobalFilter, Ordered两个接口)
1 |
|
服务配置
Config
SpringCloud Config 分布式配置中心
概述




服务端配置
首先在github上新建一个仓库 springcloud-config
然后使用git命令克隆到本地,命令:git clone 仓库地址
注意上面的操作不是必须的,只要github上有就可以,克隆到本地只是修改文件。
具体git及GitHub知识参照《Git&GitHub最强入门》
新建 cloud-config-center3344 模块:
pom文件:
1 | <dependencies> |
yml 配置:
1 | server: |
主启动类:
1 |
|
这里还有个点需要注意,idea(或者eclipse)编译工具需提前绑定GIthub账号
添加模拟映射:【C:\Windows\System32\drivers\etc\hosts】文件中添加: 127.0.0.1 config-3344.com
启动微服务3344,访问http://config-3344.com:3344/master/config-dev.yml 文件(注意,要提前在git上弄一个这文件)
文件命名和访问的规则:
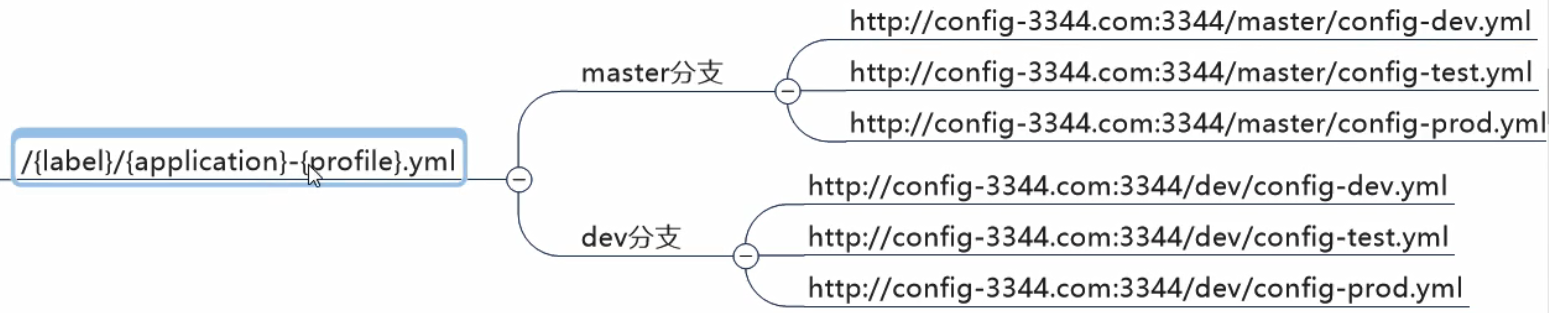
不加分支名默认是master:
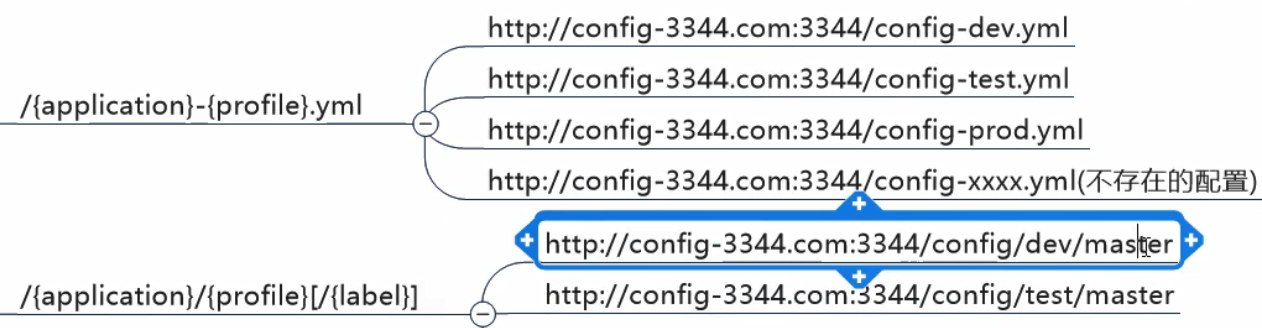
客户端配置
这里的客户端指的是,使用 Config Server 统一配置文件的项目。既有之前说的消费者,又有提供者
新建 cloud-config-client-3355 模块:
pom文件:
1 | <dependencies> |
bootstrap.yml文件说明

创建bootstrap.yml并添加以下内容:
1 | server: |
主启动类记得添加注解:
1 |
|
controller层,测试读取配置信息
1 | package com.dkf.springcloud.controller; |
启动测试完成!如果报错,注意github上的 yml 格式有没有写错!
动态刷新
问题:

就是github上面配置更新了,config Server 项目上是动态更新的,但是,client端的项目中的配置,目前还是之前的,它不能动态更新,必须重启才行。
解决:
client端一定要有如下依赖:
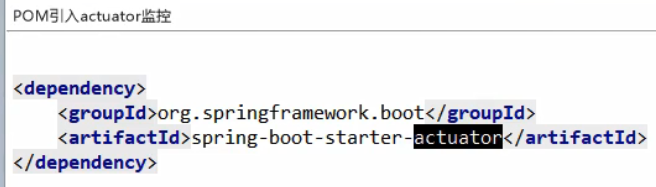
client 端增加 yml 配置如下,即在 bootstrap.yml 文件中:
1 | # 暴露监控端点 |
在controller 上添加如下注解:
到此为止,配置已经完成,但是测试仍然不能动态刷新,需要下一步。
向 client 端发送一个 POST 请求
如 curl -X POST “http://localhost:3355/actuator/refresh“
两个必须:1.必须是 POST 请求,2.请求地址:http://localhost:3355/actuator/refresh
成功!
但是又有一个问题,就是要向每个微服务发送一次POST请求,当微服务数量庞大,又是一个新的问题:可否广播,一次通知,处处生效?
于是针对这些问题就有下面的消息总线!
消息总线
Bus
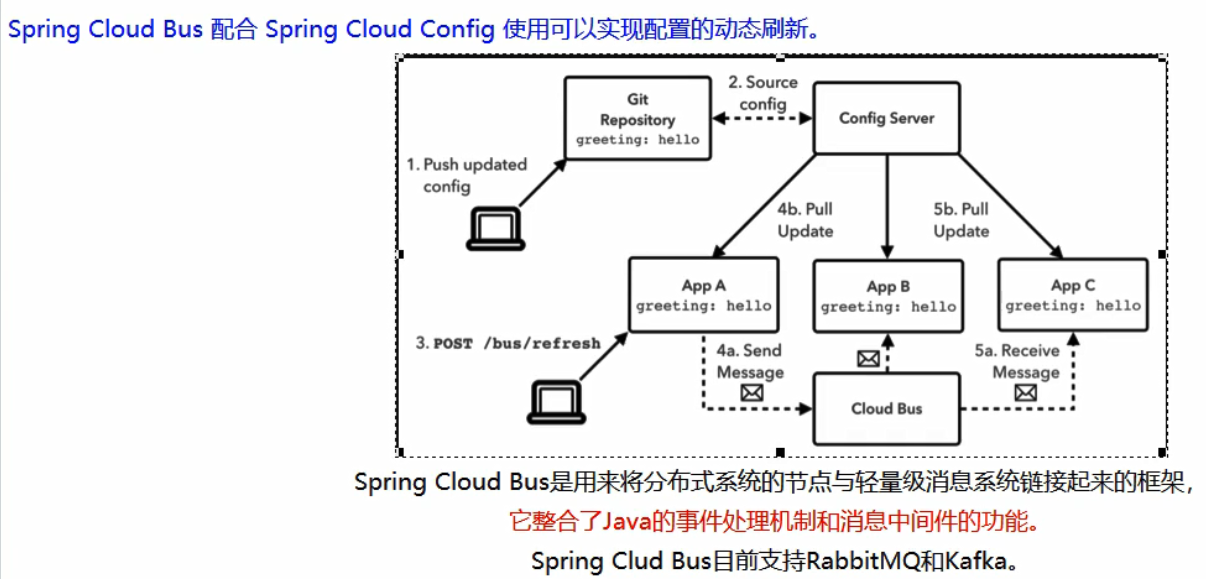

安装RabbitMQ
具体步骤参照之前的博文《RabbitMQ入门》
设计思想及选型
两个设计思想:
1) 利用消息总线触发一个客户端/bus/refresh,而刷新所有客户端的配置
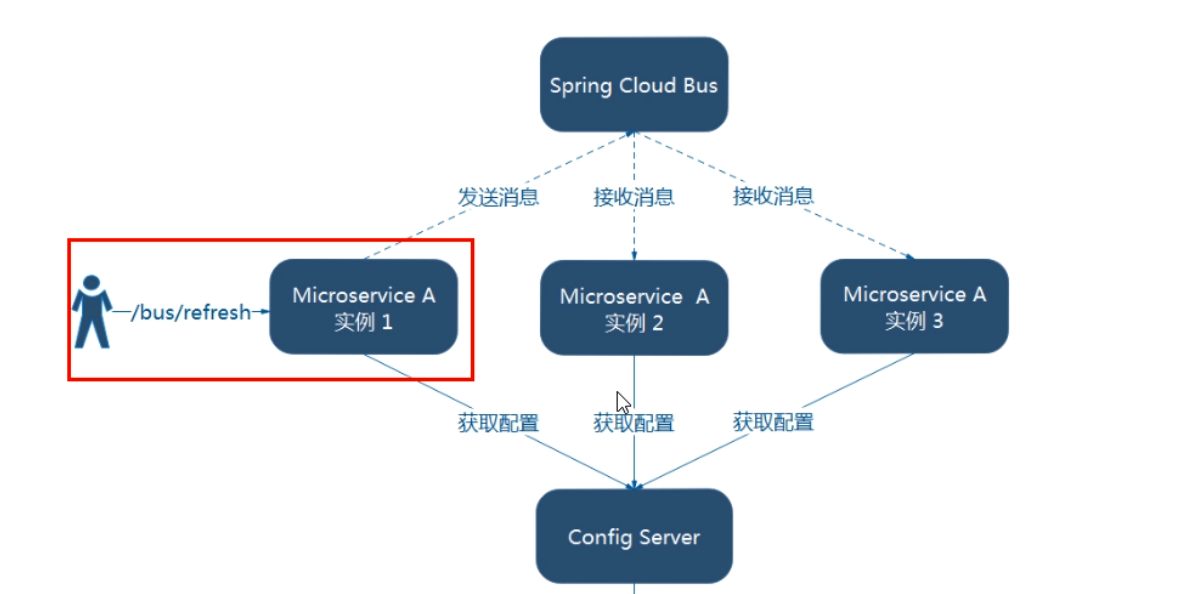
2) 利用消息总线触发一个服务端ConfigServer的/bus/refresh端点,而刷新所有客户端的配置(更加推荐)
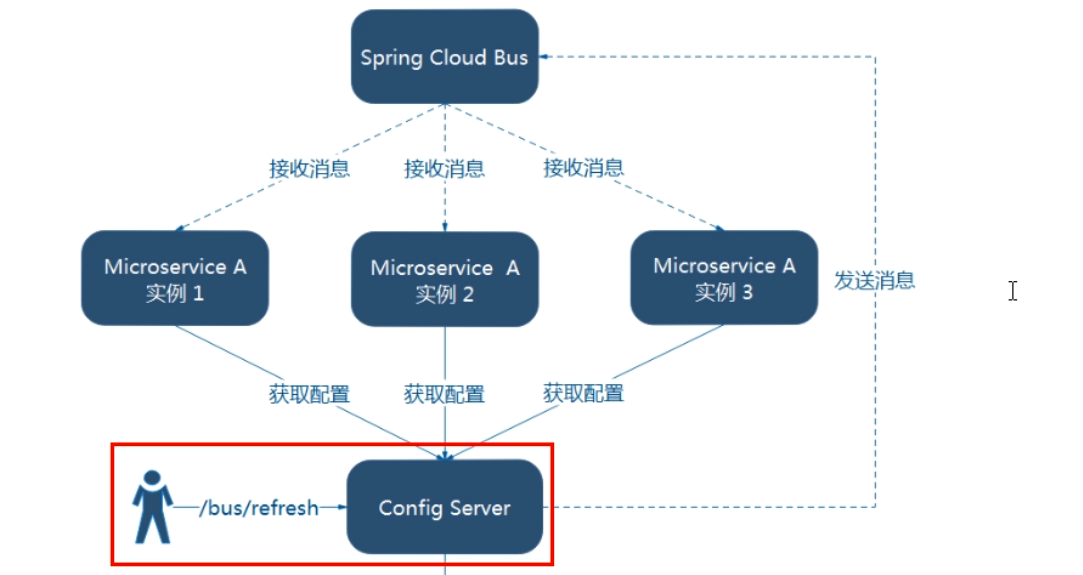
第二种架构更加合适,第一种不适合的原因如下:
- 打破了微服务的职责单一性,因为微服务本身是业务模块,它本不应该承担配置刷新职责
- 破坏了微服务各节点的对等性
- 有一定的局限性。例如,微服务在迁移时,它的网络地址常常会发生变化,此时如果想要做到自动刷新,那就会增加更多的修改
广播式刷新配置

还是按照之前的 3344(config Server)和 3355(config client)两个项目来增进。
首先给 config Server 和 config client 都添加如下依赖:
1 | <!-- 添加rabbitMQ的消息总线支持包 --> |
config Server 的yml文件增加如下配置:
1 | # rabbitMq的相关配置 |
config Client 的yml文件修改成如下配置:(注意对齐方式,和config Server不一样)
1 | spring: |
可在github上修改yml文件进行测试,修改完文件,向 config server 发送 请求:
【curl -X POST “http://localhost:3344/actuator/bus-refresh"】
注意,之前是向config client 一个个发送请求,但是这次是向 config Server 发送请求,而所有的config client 的配置也都全部更新。
定点通知


消息驱动
Stream
概述
官网:https://cloud.spring.io/spring-cloud-static/spring-cloud-stream/3.0.1.RELEASE/reference/html/
Spring Cloud Stream中文指导手册:https://m.wang1314.com/doc/webapp/topic/20971999.html
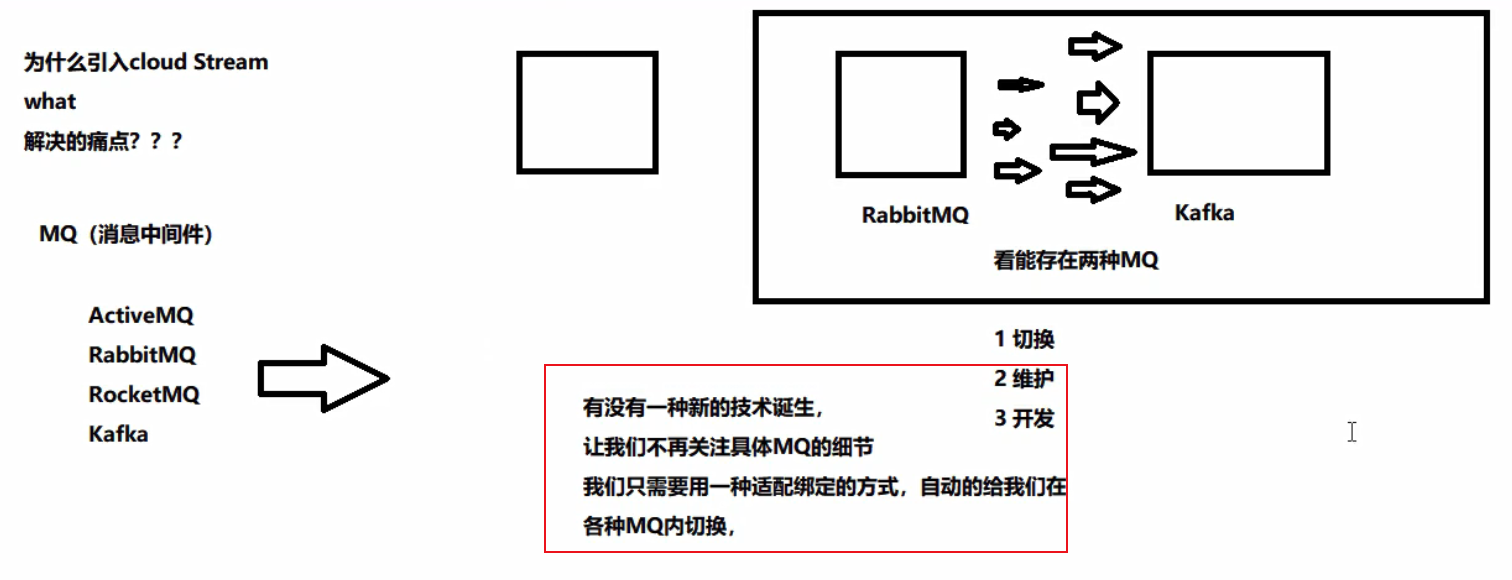

就像 JDBC 形成一种规范,统一不同数据库的接口

编码API和常用注解:

Spring Cloud Stream标准流程套路:
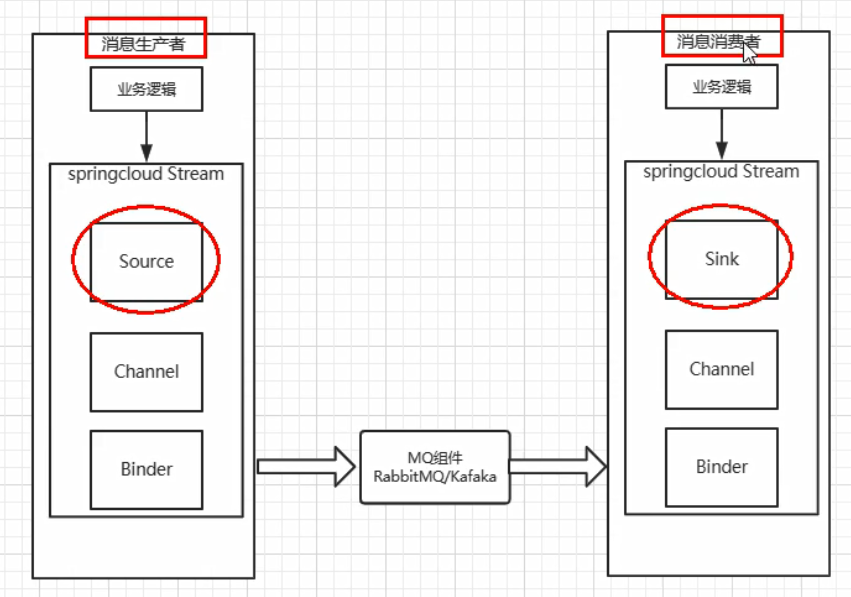
消息生产者
新建模块 cloud-stream-rabbitmq-provider8801
pom依赖:
1 | <!-- stream-rabbit --> |
yml 配置:
1 | server: |
主启动类没什么特殊的注解。
业务类:(此业务类不是以前的service,而实负责推送消息的服务类)
1 | package com.dkf.springcloud.service; |
controller:
1 |
|
启动Eureka Server 7001,再启动8801,进行测试,看是否rabbitMQ中有我们发送的消息。
消息消费者
新建模块 cloud-stream-rabbitmq-consumer8802
pom依赖和生产者一样。
yml配置: 在 stream的配置上,和生产者只有一处不同的地方,output 改成 input
1 | server: |
接收消息的业务类:
1 | import org.springframework.beans.factory.annotation.Value; |
配置分组消费
新建 cloud-stream-rabbitmq-consumer8802 模块:
8803 就是 8802 clone出来的。
当运行时,会有两个问题。
第一个问题,两个消费者都接收到了消息,这属于重复消费。例如,消费者进行订单创建,这样就创建了两份订单,会造成系统错误。

Stream默认不同的微服务是不同的组
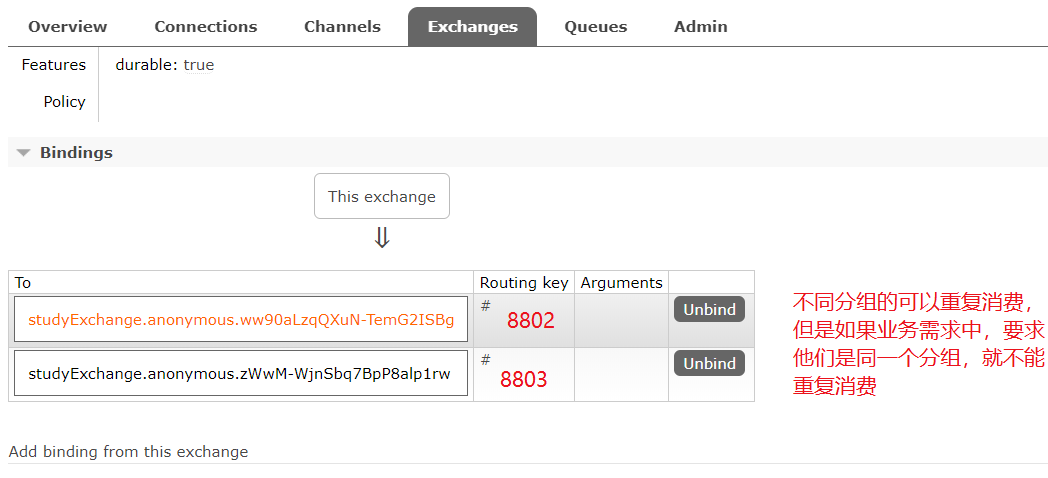
对于重复消费这种问题,导致的原因是默认每个微服务是不同的group,组流水号不一样,所以被认为是不同组,两个都可以消费。
解决的办法就是自定义配置分组:
消费者 yml 文件配置:
1 | # 8802 的消费者 |
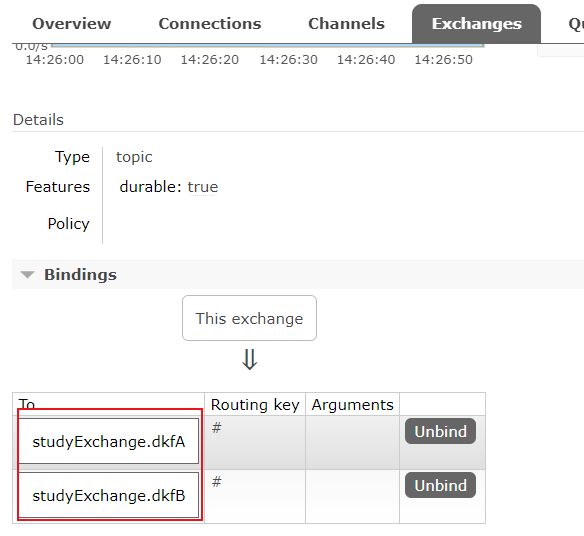
当两个消费者配置的 group 都为 dkfA 时,就属于同一组,就不会被重复消费。

消息持久化
理解消息持久化:
停止8802/8803并去除掉8802的分组group:atguiguA
8801先发送4条信息到rabbitmq
先启动8802,无分组属性配置,后台没有打出来消息
先启动8803,有分组属性配置,后台打出来了MQ上的消息
结论:加上group配置,就已经实现了消息的持久化。
Sleuth
分布式请求链路跟踪,超大型系统。需要在微服务模块极其多的情况下,比如80调用8001的,8001调用8002的,这样就形成了一个链路,如果链路中某环节出现了故障,我们可以使用Sleuth进行链路跟踪,从而找到出现故障的环节。
概述
sleuth 负责跟踪,而zipkin负责展示。
zipkin 下载地址: http://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/2.12.9/zipkin-server-2.12.9-exec.jar
使用 【java -jar】 命令运行下载的jar包:java -jar zipkin-server-2.12.9-exec.jar
访问地址:【 http://localhost:9411/zipkin/ 】
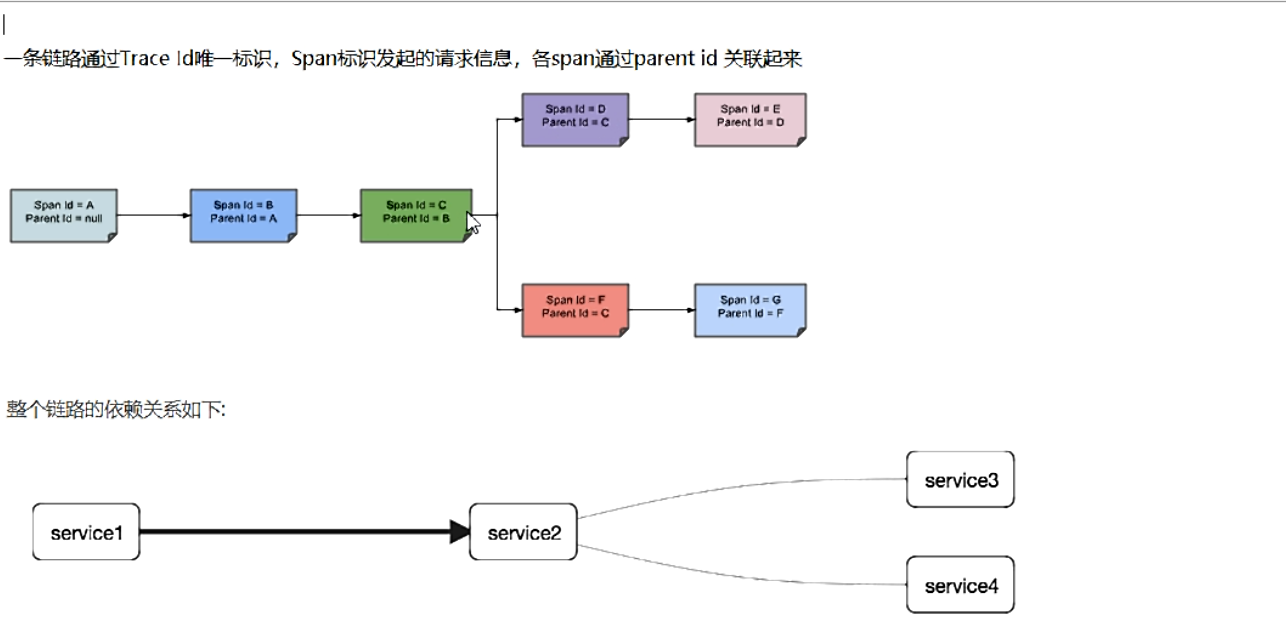
调用链路:
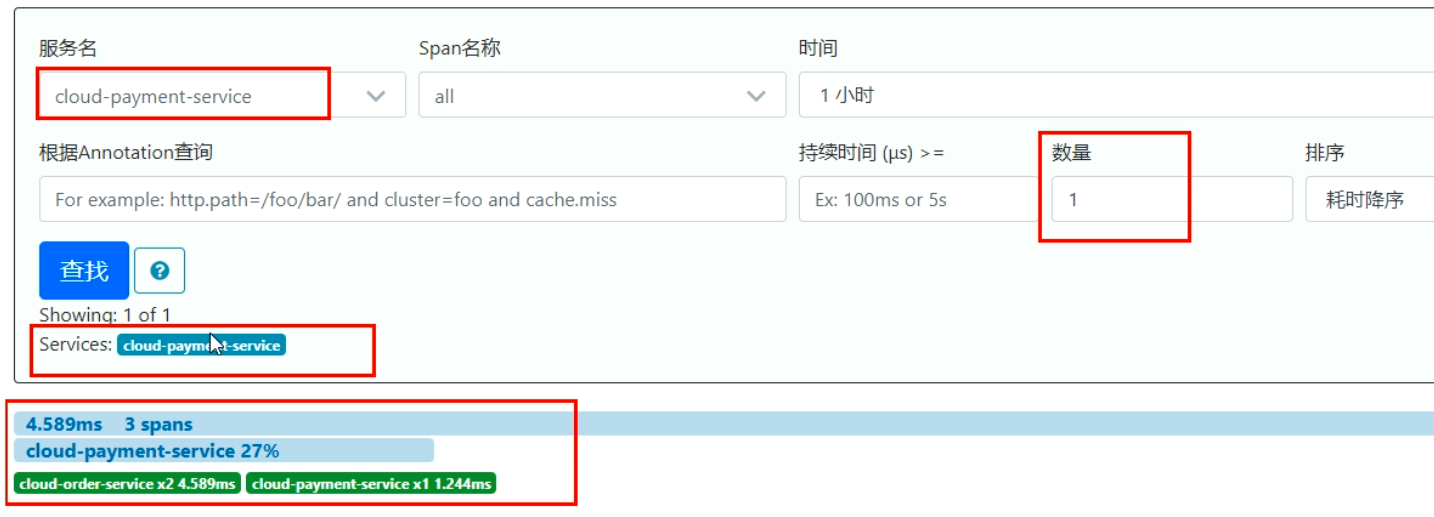
案例
使用之前的 提供者8001 和 消费者80
分别给他们引入依赖:
1 | <!-- 引入sleuth + zipkin --> |
yml增加配置:
1 | spring: |
接着进入zipkin可视化界面查看两个服务的引用运行细节。
高级部分
SpringCloud Alibaba
大简介

学习资料官网:
- https://spring-cloud-alibaba-group.github.io/github-pages/greenwich/spring-cloud-alibaba.html
- https://github.com/alibaba/spring-cloud-alibaba/blob/master/README-zh.md
Nacos
概述:Nacos = Eureka + Config + Bus
github地址: https://github.com/alibaba/Nacos
Nacos 官网: https://nacos.io/zh-cn/
nacos可以切换 AP 和 CP ,可使用如下命令切换成CP模式:

下载
下载地址: https://github.com/alibaba/nacos/releases/tag/1.1.4
直接下载网址: https://github.com/alibaba/nacos/releases/download/1.1.4/nacos-server-1.1.4.zip
下载压缩包以后解压,进入bin目录,打开dos窗口,执行startup命令启动它。
可访问 : 【 http://192.168.101.105:8848/nacos/index.html】地址,默认账号密码都是nacos
服务中心
提供者
新建模块 cloudalibaba-provider-payment9001
pom依赖:
1 | <dependencies> |
yml 配置:
1 | server: |
主启动类没有特殊的注解。
Nacos 自带负载均衡机制,下面创建第二个提供者。
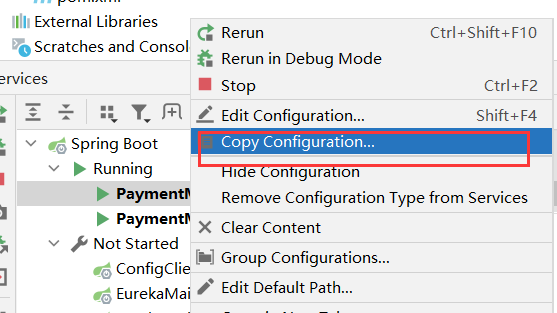
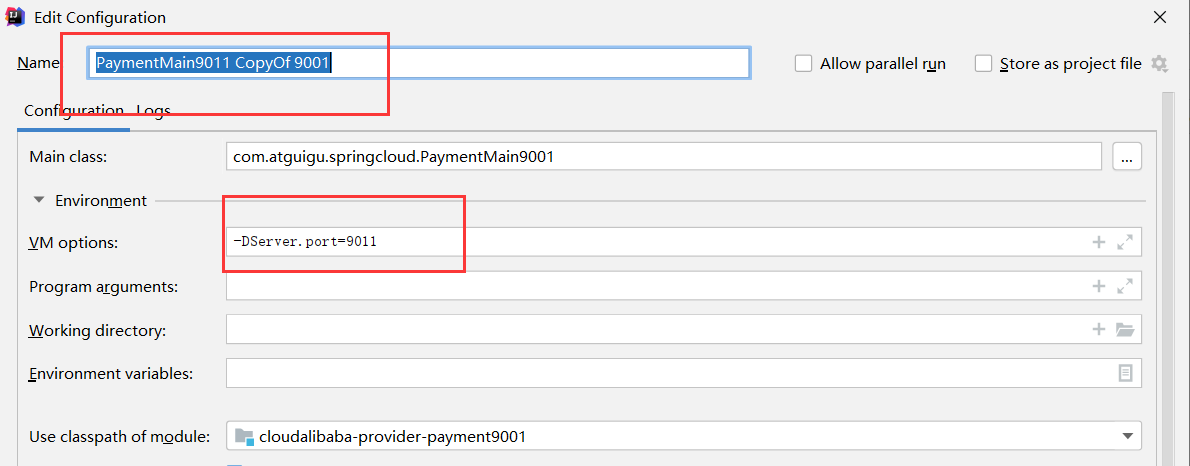
新建 cloudalibaba-provider-payment9003 提供者模块,clone 9001 就可以
这里提供一个简单的copy方法,直接拷贝虚拟端口映射:
消费者
新建消费者 模块: cloudalibaba-customer-order80
pom依赖和主启动类没有好说的,和提供者一致,yml依赖也是类似配置,作为消费者注册进nacos服务中心。
nacos底层也是ribbon,注入ReatTemplate
1 |
|
controller :
1 |
|
测试地址:http://localhost:83/consumer/payment/nacos/13
发现Nacos自带负载均衡,因为它整合了Ribbon
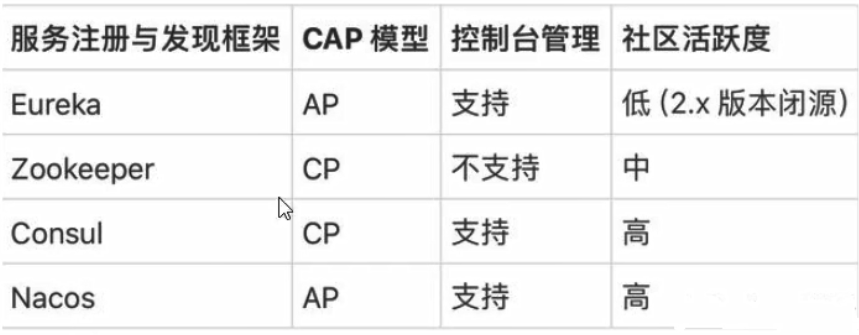
服务注册中心对比
Nacos全景图所示:
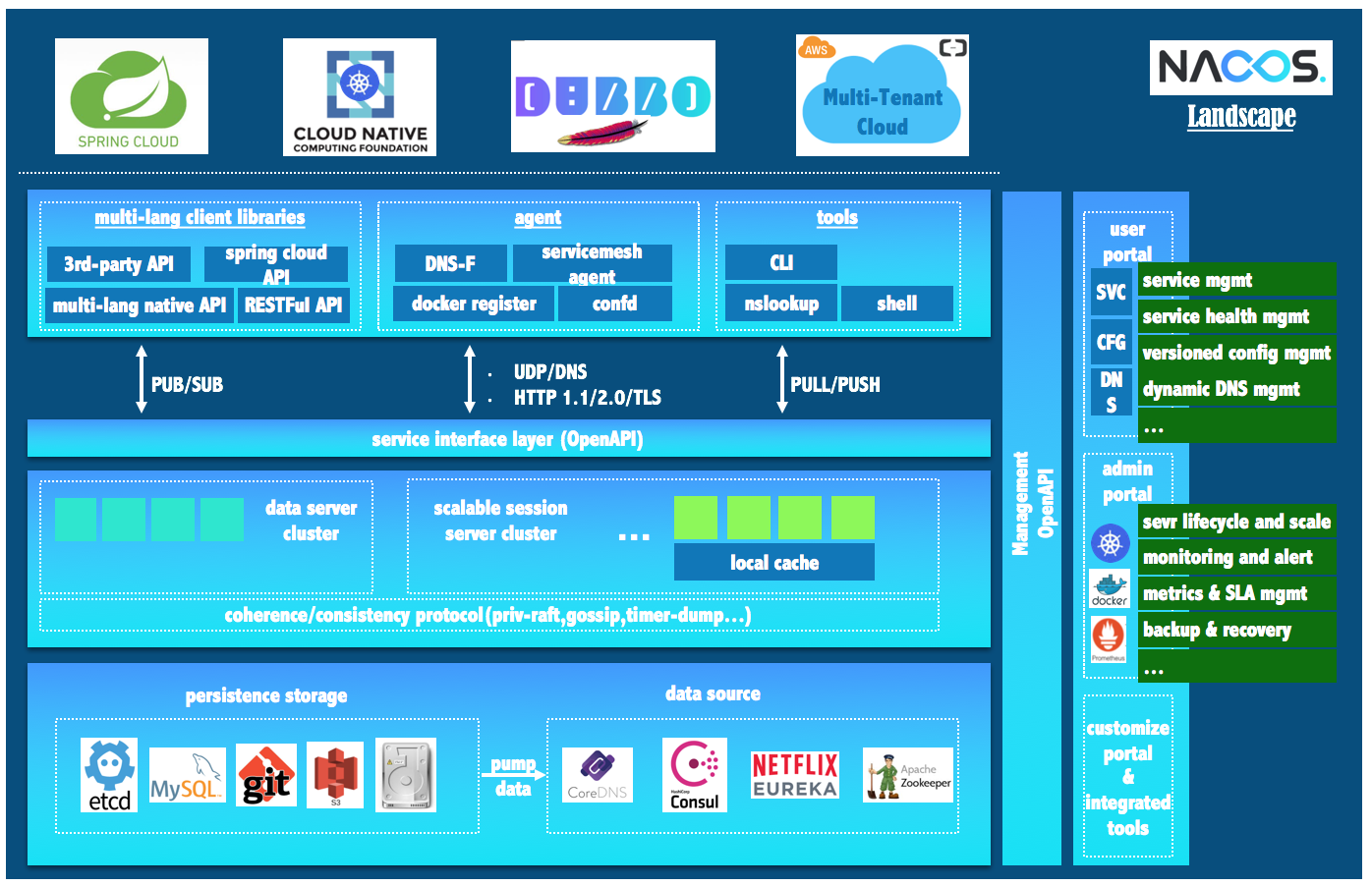
注:Nacos支持AP和CP模式的切换

配置中心
nacos 还可以作为服务配置中心,下面是案例,创建一个模块,从nacos上读取配置信息。
nacos 作为配置中心,不需要像springcloud config 一样做一个Server端模块。
基础配置
新建模块 cloudalibaba-nacos-config3377
pom依赖:
1 | <dependencies> |
主启动类也是极其普通:
1 |
|

bootstrap.yml 配置:
1 | server: |
controller 层进行读取配置测试:(需要@RefreshScope实现配置自动更新)
1 |
|
下面在 Nacos 中添加配置文件,需要遵循如下规则:

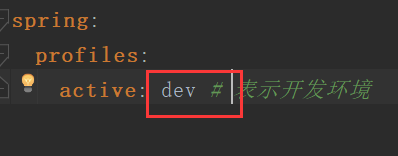
从上面可以看到重要的一点,配置文件的名称第二项,spring.profiles.active 是依据当前环境的profile属性值的,也就是这个值如果是 dev,即开发环境,它就会读取 dev 的配置信息,如果是test,测试环境,它就会读取test的配置信息,就是从 spring.profile.active 值获取当前应该读取哪个环境下的配置信息。
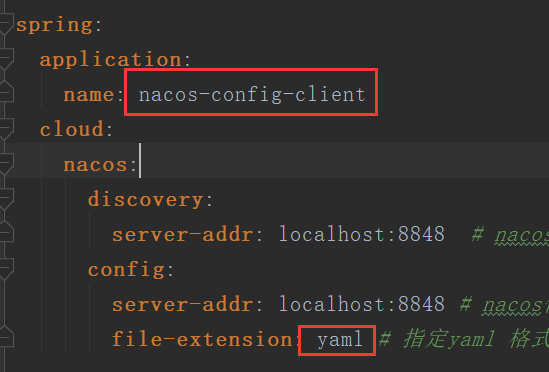
所以要配置spring.profiles.active,新建application.yml文件,添加如下配置:
1 | spring: |

综合以上说明,和下面的截图,Nacos 的dataid(类似文件名)应为: nacos-config-client-dev.yaml (必须是yaml)
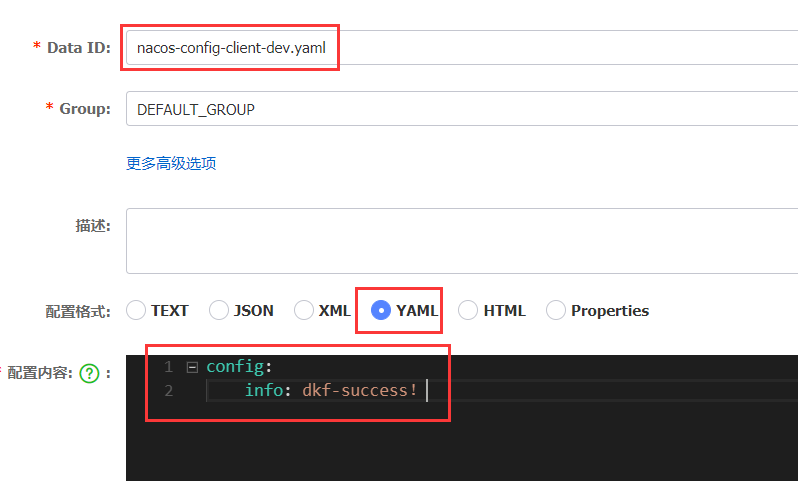
当修改配置值,会发现 3377 上也已经修改,Nacos自带自动刷新功能!
分类配置
Nacos 的 Group ,默认创建的配置文件,都是在DEFAULT_GROUP中,可以在创建配置文件时,给文件指定分组。
yml 配置如下,当修改开发环境时,只会从同一group中进行切换。
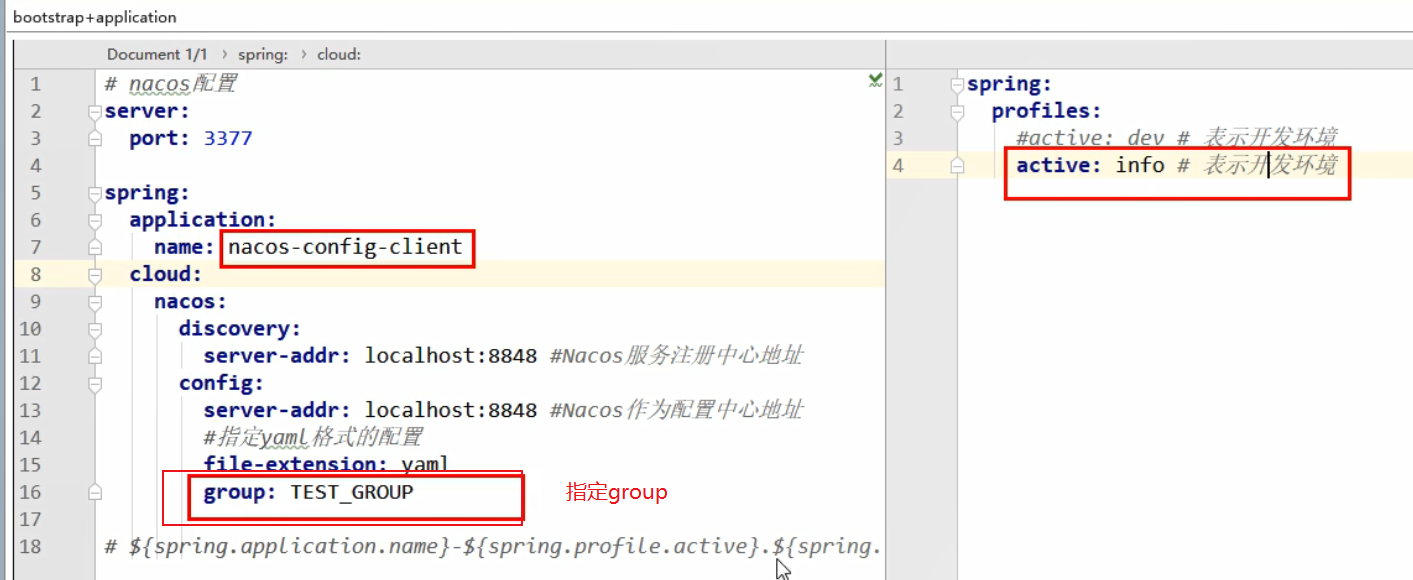
Nacos 的namespace ,默认的命名空间是public ,这个是不允许删除的,可以创建一个新的命名空间,会自动给创建的命名空间一个流水号。
在yml配置中,指定命名空间:
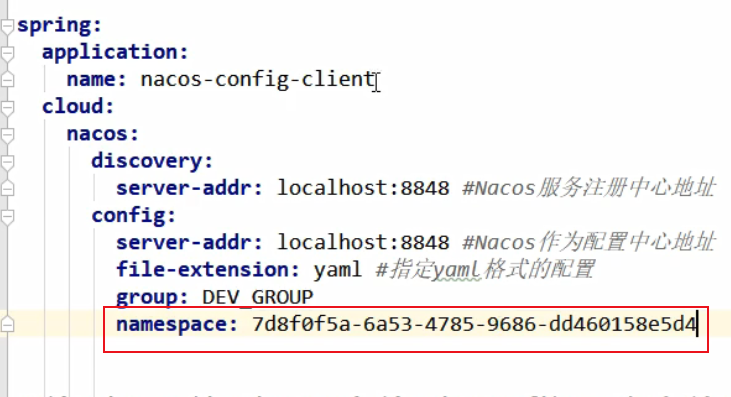
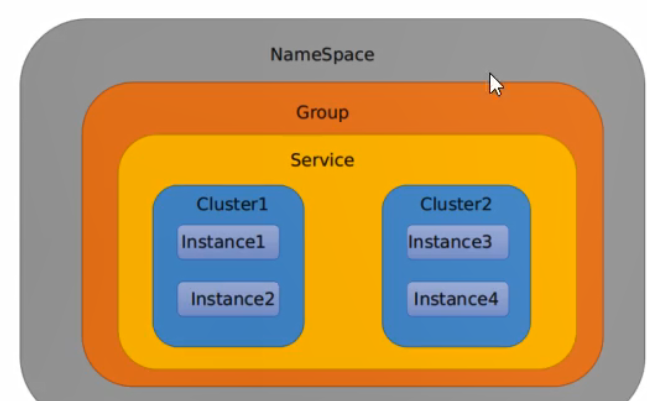
最后,dataid、group、namespace 三者关系如下:(不同的dataid,是相互独立的,不同的group是相互隔离的,不同的namespace也是相互独立的)
Nacos持久化
上面只是小打小闹,下面才是真正的高级操作。
Nacos默认使用它自带的嵌入式数据库derby:
所以搭建集群必须持久化,不然多台机器上的nacos的配置信息不同,造成系统错乱。它不同于单个springcloud config,没有集群一说,而且数据保存在github上,也不同于eureka,配置集群就完事了,没有需要保存的配置信息。
Nacos持久化配置:
在 nacos的 conf目录下,有个nacos-mysql.sql 的sql文件,创建一个名为【nacos_config】的数据库,执行里面内容,在nacos_config数据库里面创建数据表。
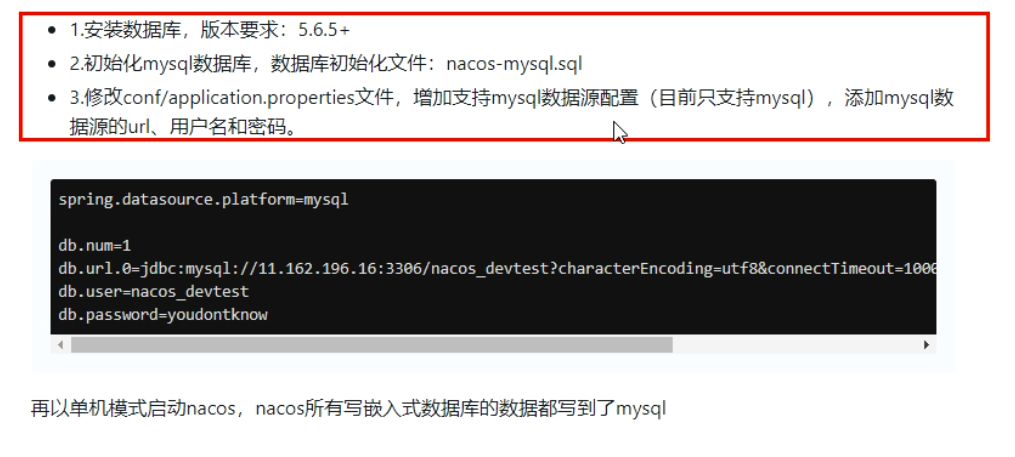
找到conf/application.properties 文件,尾部追加如下内容:
2
3
4
5
6
db.num=1
db.url.0=jdbc:mysql://localhost:3306/nacos_config?characterEncoding=utf-8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=root
db.password=123456重启nacos,即完成持久化配置。可以看到是个全新的空记录界面,以前是记录进derby
集群架构
官网架构图:
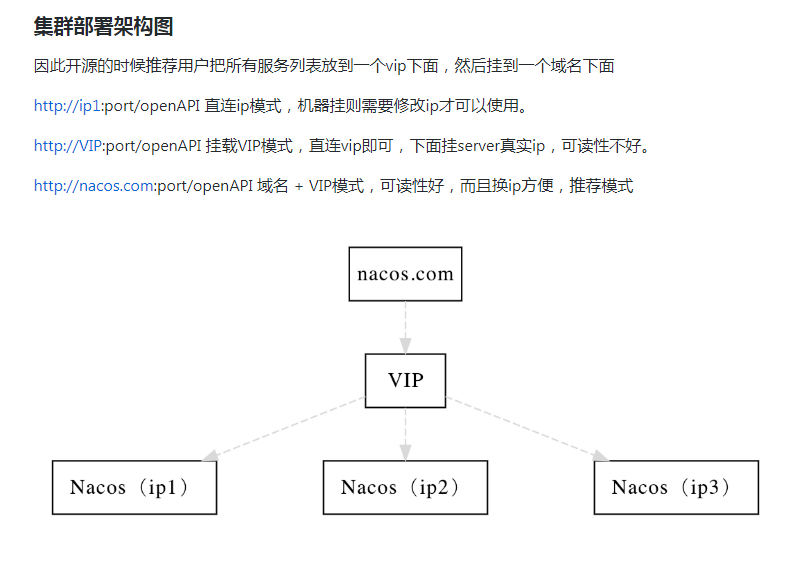
对官网架构图的翻译:
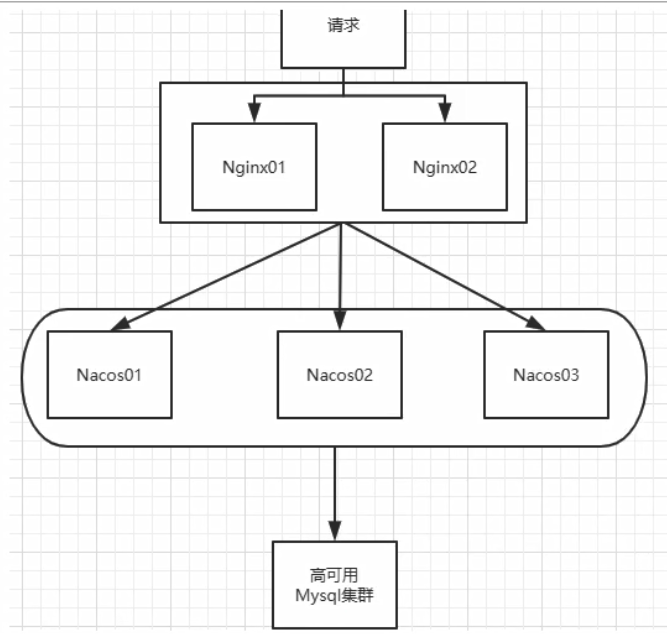
现在进行企业中真正需要的nacos集群配置,而不是上面的单机模式,需要准备如下:
一台linux虚拟机:nginx服务器,3个nacos服务,一个mysql数据库。
nginx的安装参考之前学,使用 ContOs7 至少需要安装gcc库,不然无法编译安装【yum install gcc】
nacos下载linux版本的 tar.gz 包:https://github.com/alibaba/nacos/releases/download/1.1.4/nacos-server-1.1.4.tar.gz
mysql root用户密码为 Dkf!!2020
Nacos集群配置
首先对 nacos 进行持久化操作,操作如上面一致。
修改 nacos/conf 下的cluster文件,最好先复制一份,添加如下内容:
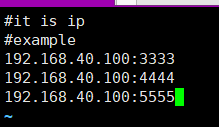
模拟三台nacos服务,编辑nacos的startup启动脚本,使他能够支持不同的端口启动多次。



nginx配置负载均衡:

测试完成!
使用 9003 模块注册进Nacos Server 并获取它上面配置文件的信息,进行测试。
Sentinel
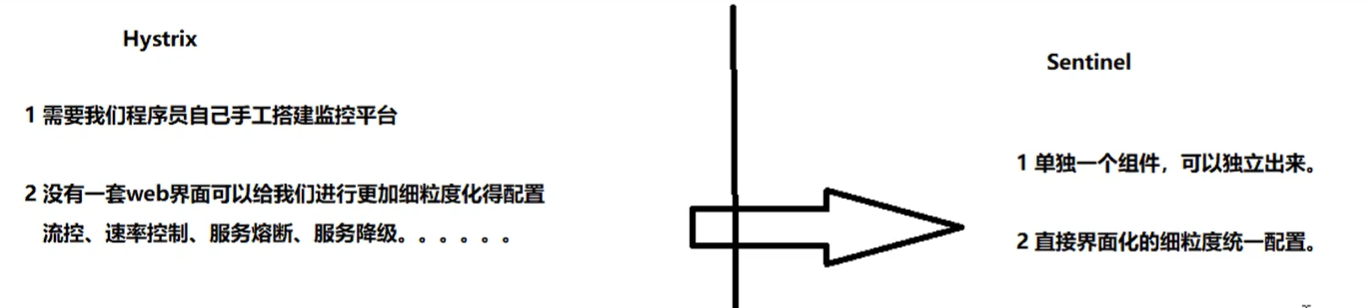
是什么:一句话解释,之前我们讲解过的Hystrix
sentinel在 springcloud Alibaba 中的作用是实现熔断和限流
下载
下载地址: https://github.com/alibaba/Sentinel/releases/download/1.7.1/sentinel-dashboard-1.7.1.jar
下载jar包以后,使用【java -jar】命令启动即可。
它使用 8080 端口,用户名和密码都为 : sentinel
Demo
新建模块 cloudalibaba-sentinel-service8401 ,使用nacos作为服务注册中心,来测试Sentinel的功能。
pom依赖:
1 | <dependencies> |
yml 配置:
1 | server: |
写一个简单的主启动类,再写一个简单的controller测试sentinel的监控。
注:Sentinel采用的懒加载说明——需要执行一次访问即可启动Sentinel对该服务的监控
流控规则
基本介绍

流控模式—直接
QPS直接失败:
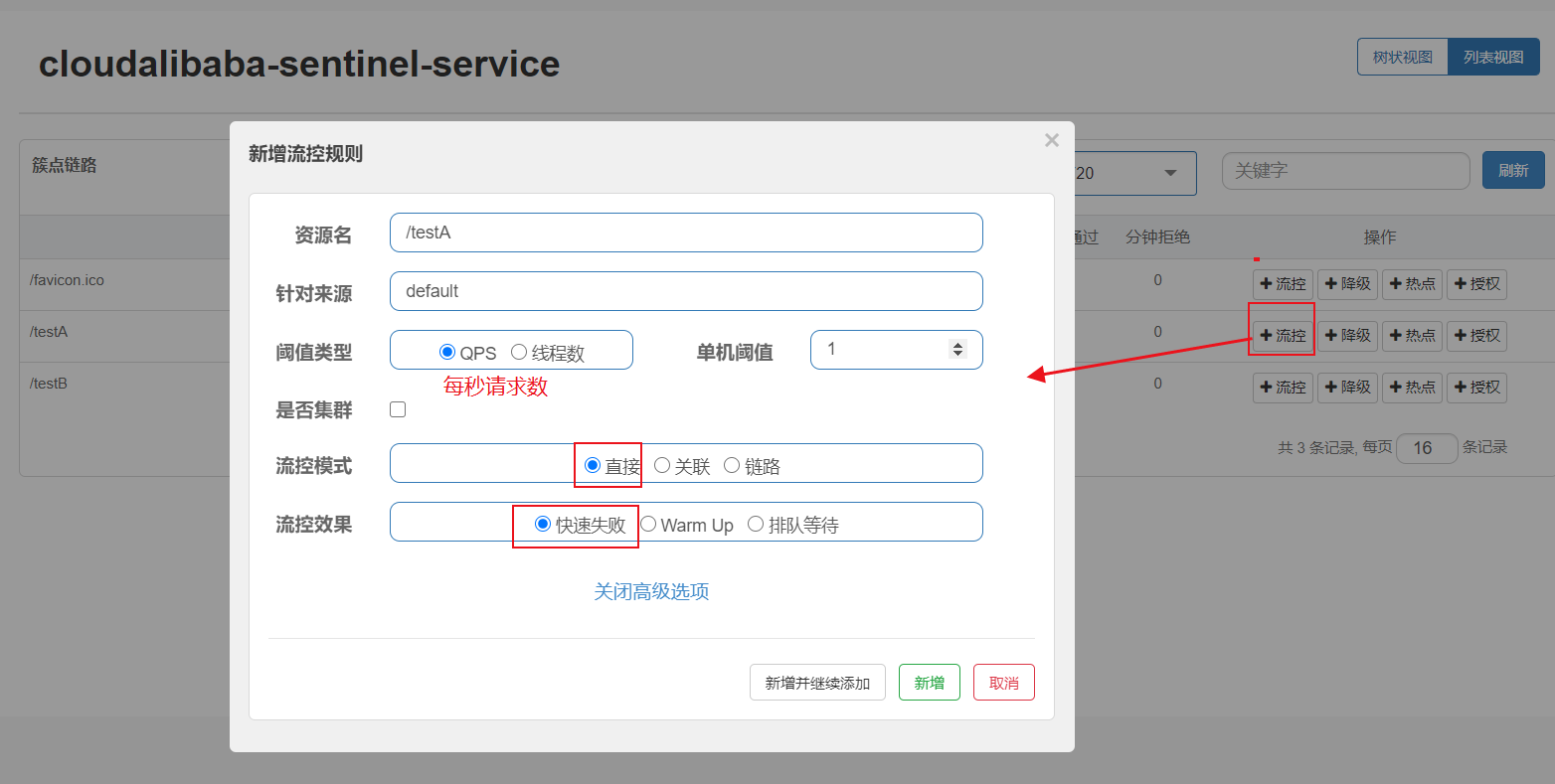
限流表现:当每秒请求数超过阀值,就会被降级。
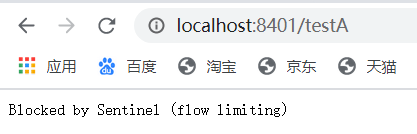
线程数直接失败:

线程数可以类比于工作人员,一个工作人员同时只能接受一方的请求,其他方的需要排队,否则也会返回默认报错信息。
流控模式—关联

生活应用:支付系统挂了,我们得让订单系统也随着挂。
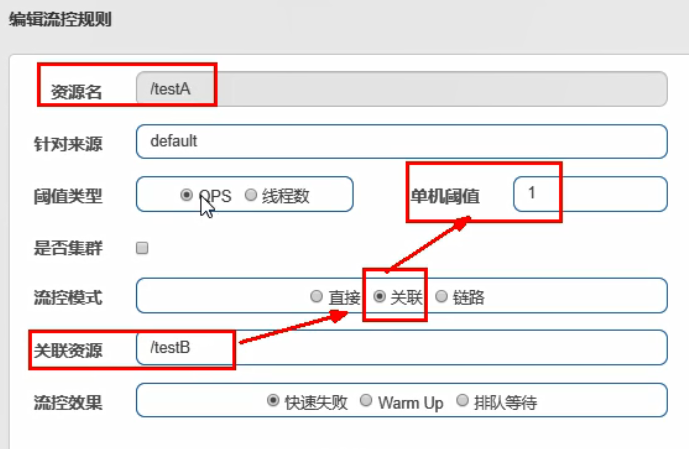
使用postman模拟并发密集访问testB:
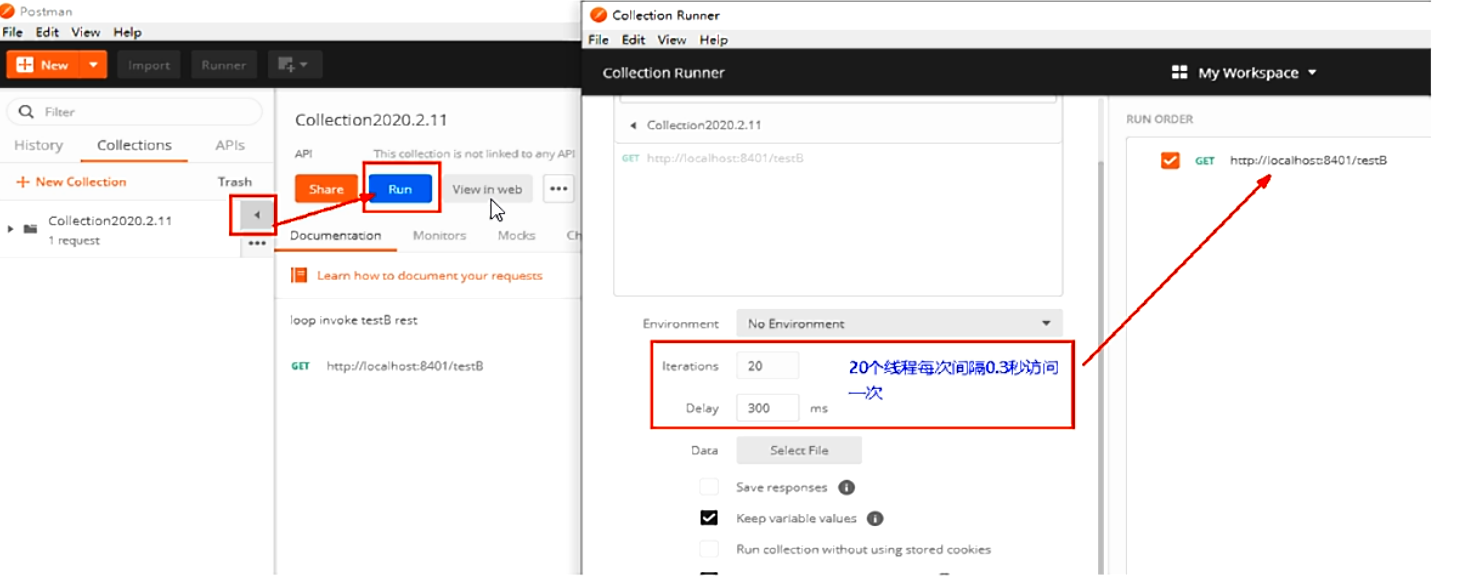

可以看到,大批量线程高并发访问B,导致A失效了。
流控效果—预热
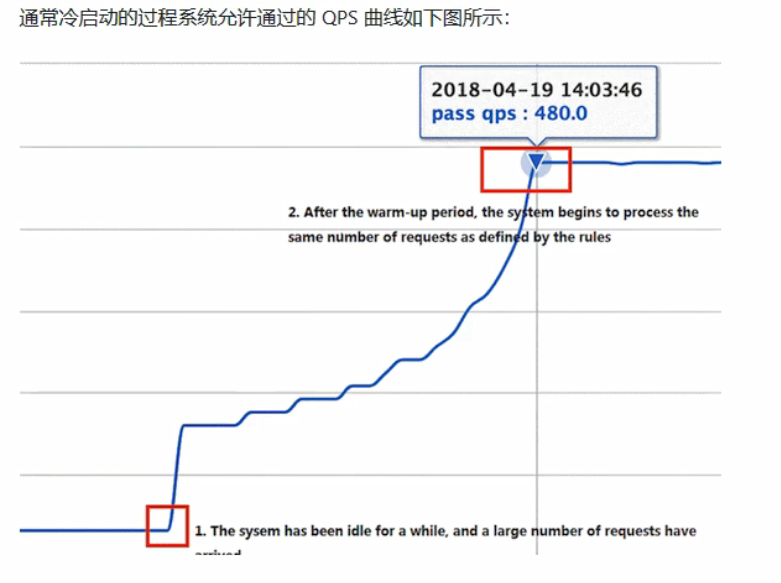
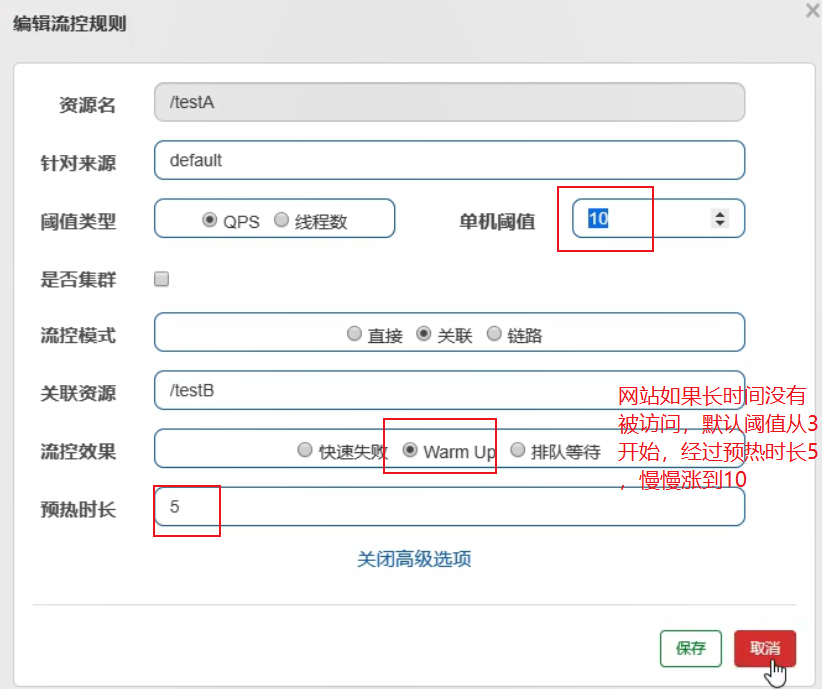

流控效果—排队等待

熔断降级
Sentinel的断路器是没有半开状态的,它会在出错后给定的时间窗口自动把熔断器给关闭。
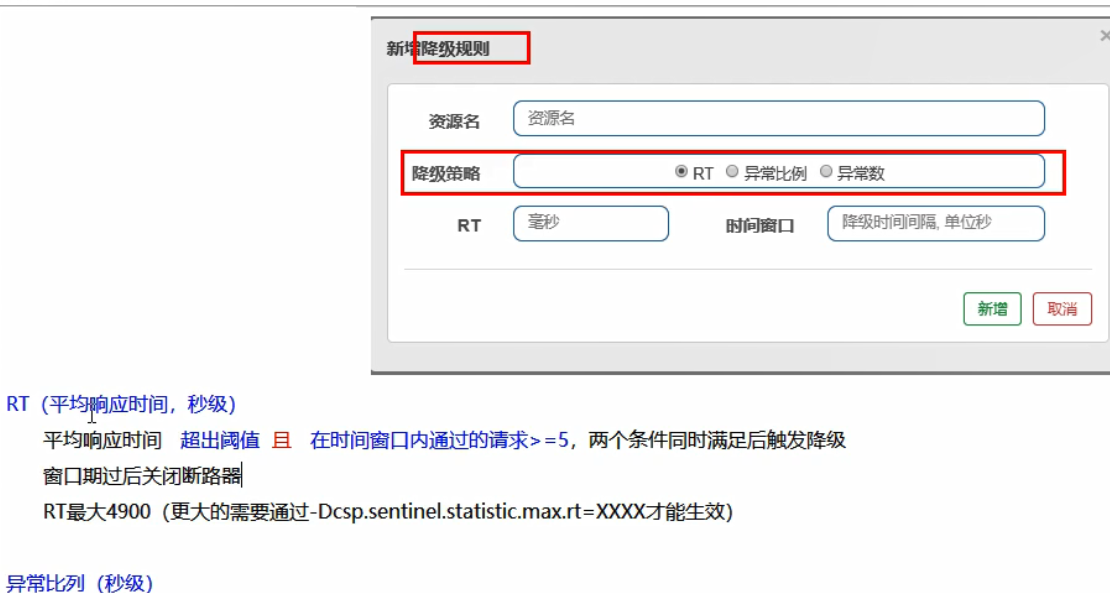


降级策略—RT
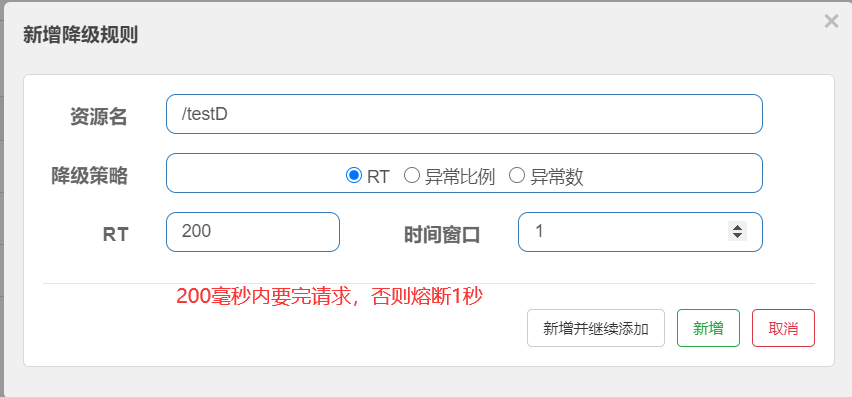
使用jmeter压测,发现Sentinel会自动熔断
降级策略—异常比例

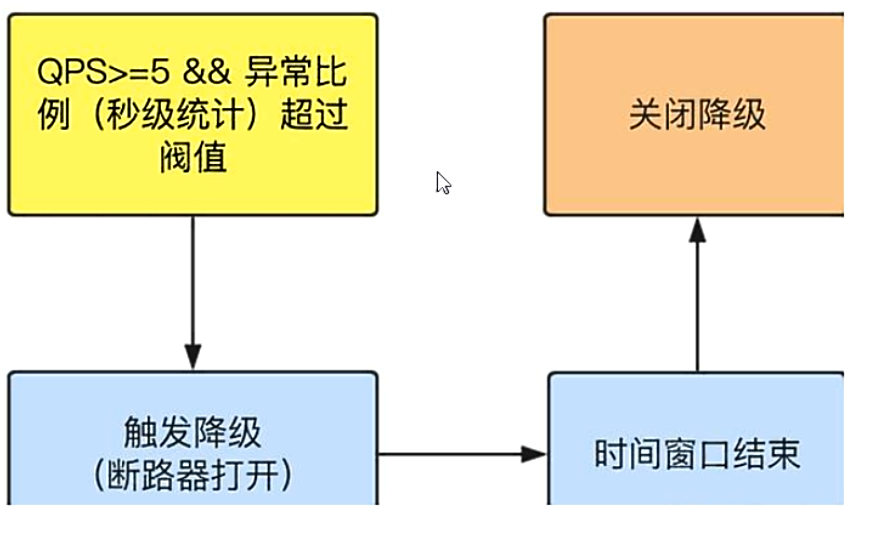
注意这里的两个条件:一个是每秒请求数量,另一个是异常比例超过阈值。

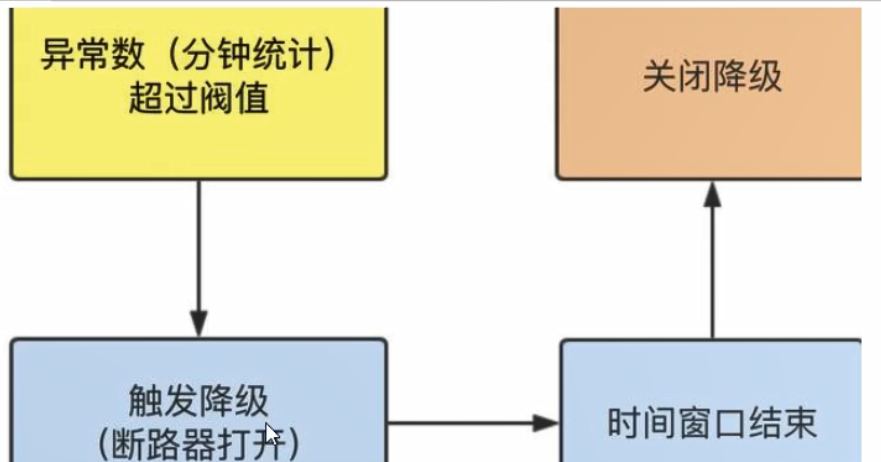
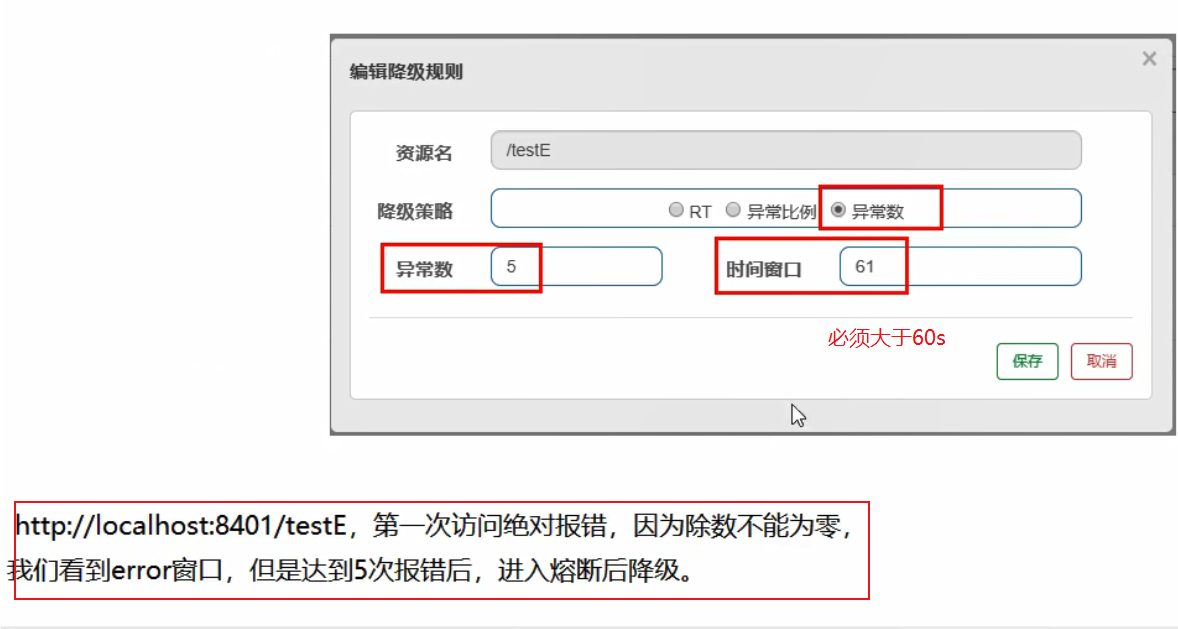
降级测录—异常数

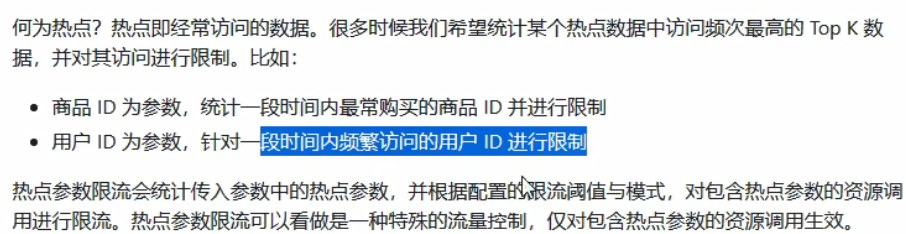
热点Key限流

controller层写一个demo:
1 |
|
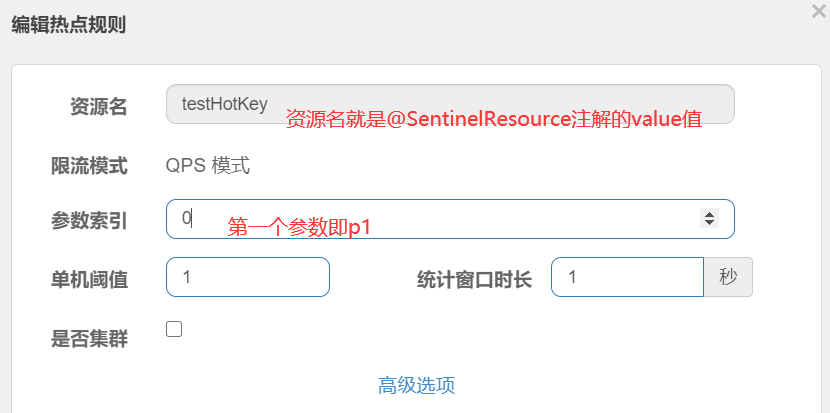
这样子设置的内容翻译一下就是:方法testHostKey里面第一个参数只要QPS超过每秒1次,马上降级处理。
参数例外项:(我们期望p1参数当它是某个特殊值时,它的限流值和平时不一样)
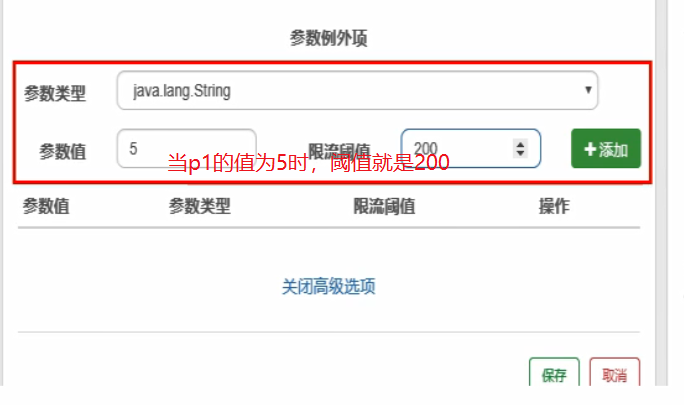
这里需要注意一下:

系统规则
一般配置在网关或者入口应用中,但是这个东西有点危险,不但值不合适,就相当于系统瘫痪。

@SentinelResource配置
@SentinelResource 注解,主要是指定资源名(也可以用请求路径作为资源名),和指定降级处理方法的。
例如:
1 | package com.dkf.springcloud.controller; |
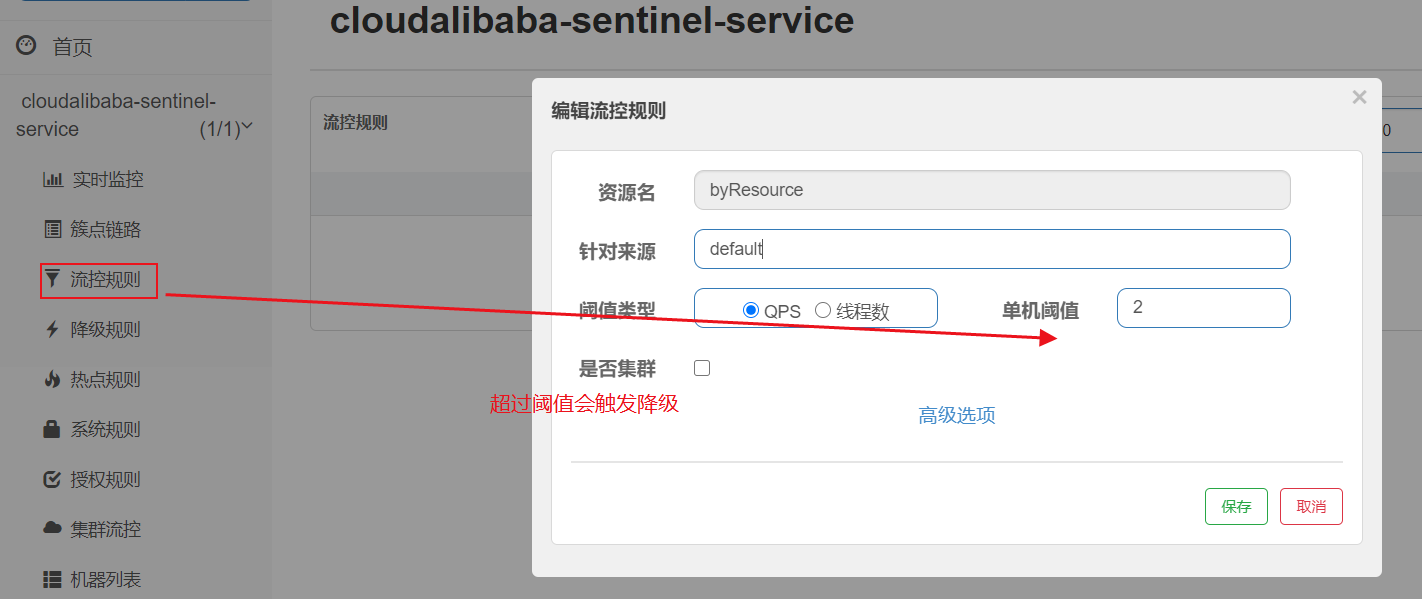
很明显,上面虽然自定义了兜底方法,但是耦合度太高,跟Hystrix一样,我们下面要解决这个问题。
客户自定义限流处理类
写一个 CustomerBlockHandler 自定义限流处理类:
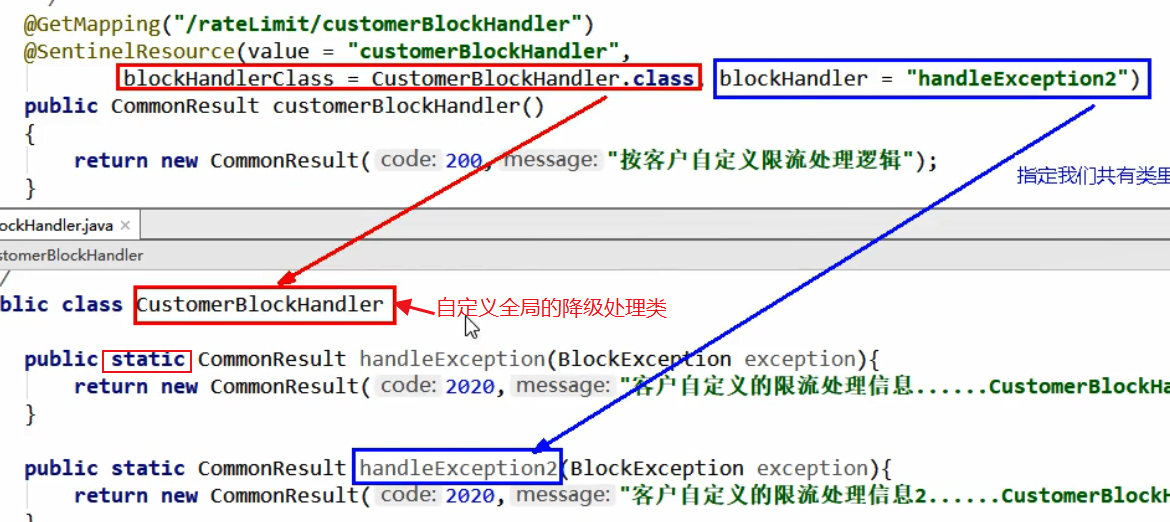
服务熔断功能
我们需要实现sentinel整合ribbon+openFeign+fallback
Ribbon系列
上面使用sentinel有一个很明显的问题,就是sentinel,对程序内部异常(各种异常,包括超时)这种捕捉,显得很乏力,它主要是针对流量控制,系统吞吐量,或者是异常比例这种,会发生降级或熔断,但是当程序内部发生异常,直接返回给用户错误页面。所以我们需要用到@SentinelResource中的另一个属性fallback.

新建三个模块,两个提供者 9004、9005,和一个消费者 84
—————————————————————————————-两个提供者模块一致,如下:
pom依赖:
1 | <dependencies> |
yml配置:
1 | server: |
主启动类只是启动,没有其它注解。
controller(模拟数据库读取数据) :
1 | package com.dkf.sprIngcloud.controller; |
————————————————————————————————————————-消费者:
pom依赖:
1 | <dependencies> |
yml配置:
1 | server: |
主启动类需要添加开启Discovery和Ferign注解。
config类里面注入 RestTemplate:
1 |
|
controller 层:
1 |
|
上面只实现了 以nacos 作为服务注册中心,消费者使用ribbon 实现负载均衡调用提供者的效果。
fallback和blockHandler
只配置 fallback:
1 |
|
业务异常会被 fallback 处理,返回我们自定义的提示信息,而如果给它加上流控,并触发阈值,只能返回sentinel默认的提示信息。
只配置blockHandler:
1 | //@SentinelResource(value = "fallback", fallback = "handleFallback") //fallback只处理业务异常 |
这时候的效果就是,运行异常直接报错错误页面。在sentinel上添加一个降级规则,设置2s内触发异常2次,触发阈值以后,返回的是我们自定义的 blockhanlder 方法返回的内容。
两者都配置:
1 | //@SentinelResource(value = "fallback", fallback = "handleFallback") //fallback只处理业务异常 |

fallback 和 blockHandler 肤浅的区别:
F : 不需要指定规则,程序内部异常均可触发(超时异常需要配置超时时间)
B : 配上也没用,必须去 Sentinel 上指定规则才会被触发。
异常忽略:
这是 @SentinelResource 注解的一个值:

该注解的意思为IllegalArgumentException这个异常没有兜底方法,会直接报错
Feign系列
上面是单个进行 fallback 和 blockhandler 的测试,下面是整合 openfeign 实现把降级方法解耦。和Hystrix 几乎一摸一样!
还是使用上面 84 这个消费者做测试:
- 先添加open-feign依赖:
1 | <dependency> |
- yml 追加如下配置:
1 | # 激活Sentinel对Feign的支持 |
- 主启动类添加注解 : @EnableFeignClients 激活open-feign
- service :
1 |
|
- service 实现类:
1 |
|
- controller 层代码没什么特殊的,和普通调用service 一样即可。
- 测试84调用9003,此时故意关闭9003微服务提供者,看84消费侧自动降级,不会被耗死。
- 总结: 这种全局熔断,是针对 “访问提供者” 这个过程的,只有访问提供者过程中发生异常才会触发降级,也就是这些降级,是给service接口上这些提供者的方法加的,以保证在远程调用时能顺利进行。而且这明显是 fallback ,而不是 blockHandler,注意区分。
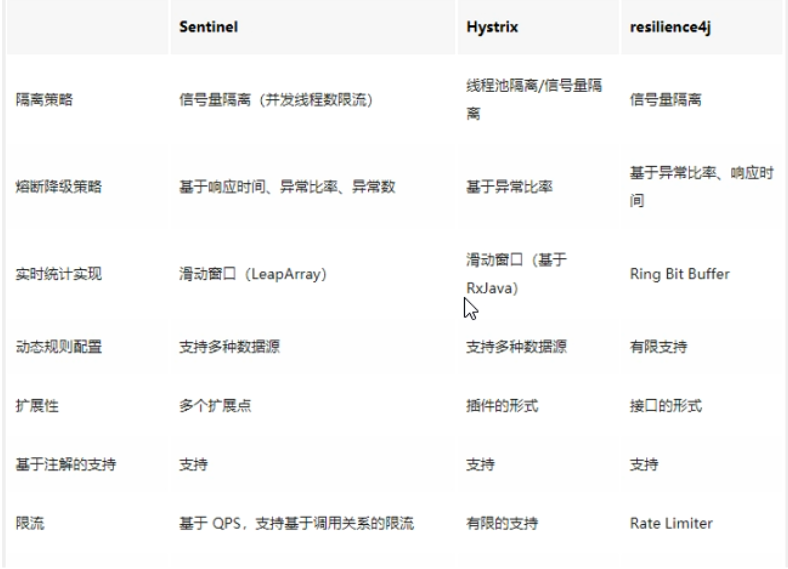
熔断框架比较

持久化
目前的sentinel 当重启以后,数据都会丢失,和 nacos 类似原理。需要持久化。它可以被持久化到 nacos 的数据库中。
将限流配置规则持久化进Nacos保存,只要刷新8401某个rest地址,sentinel控制台的流控规则就能看到,只要Nacos里面的配置不删除,针对8401上Sentinel上的流控规则持续有效
- pom依赖:
1 | <dependency> |
- yml配置:
1 | spring: |
- 去nacos上创建一个配置 ,dataid和yml配置的一致,json格式,内容如下:
1 | [ |

- 启动应用,发现存在 关于 /testA 请求路径的流控规则。
- 总结: 就是在 sentinel 启动的时候,去 nacos 上读取相关规则配置信息,实际上它规则的持久化,就是第三步,粘贴到nacos上保存下来,就算以后在 sentinel 上面修改了,重启应用以后也是无效的。
Seata
Seate 处理分布式事务。
微服务模块,连接多个数据库,多个数据源,而数据库之间的数据一致性需要被保证。
Seata简介
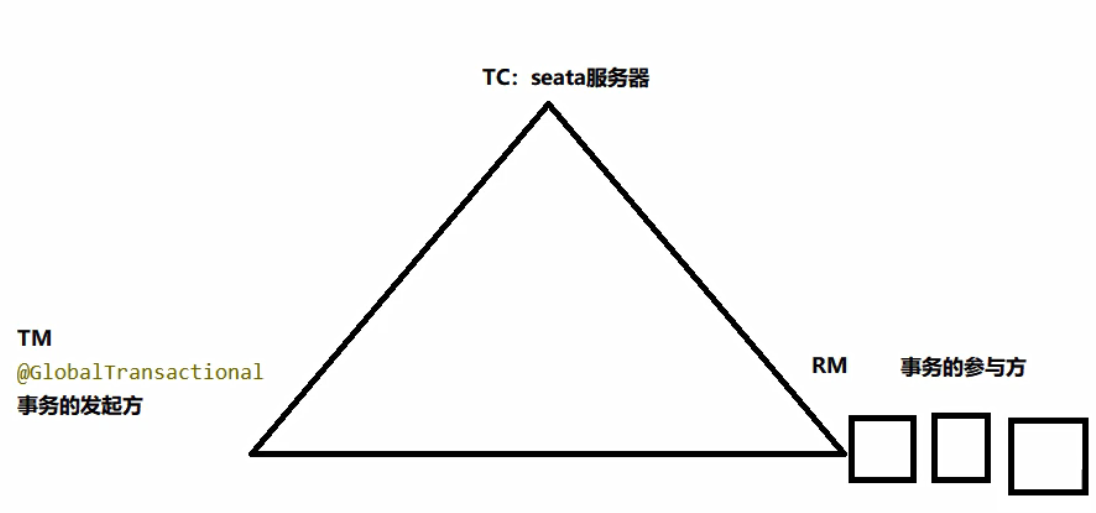
Seata术语: 一 + 三


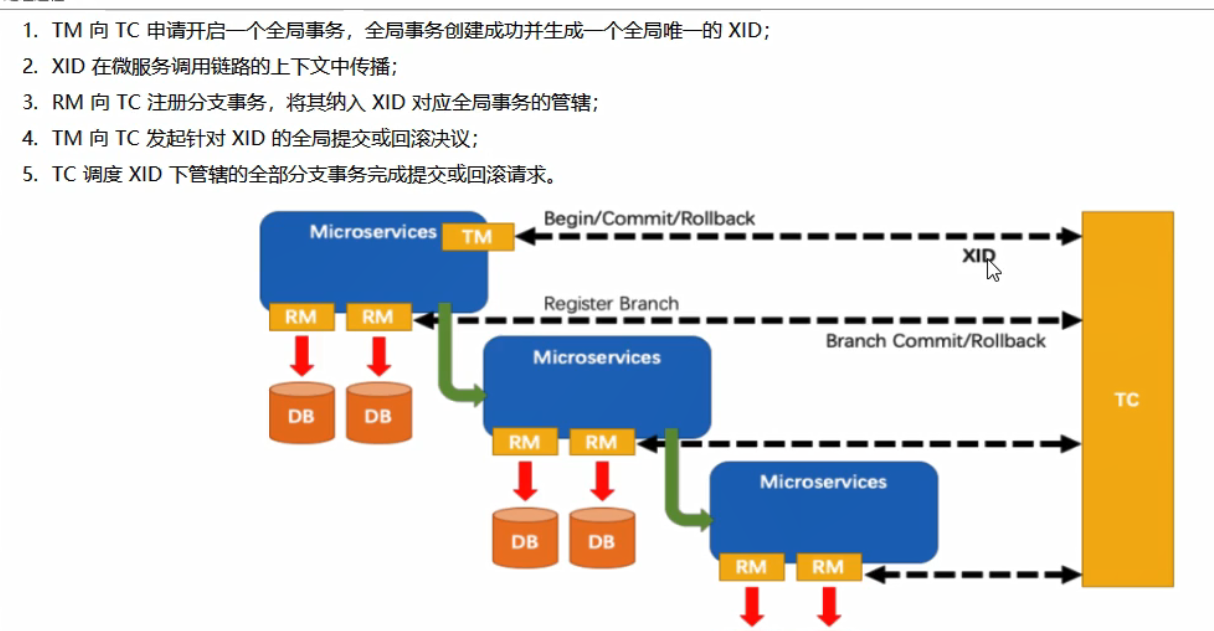
这里可以类比来更加容易的理解:(自己浅薄的理解,错了轻喷)
我们可以把TC看作年级主任,TM看作每个班的班主任,而RM看作每个班独立的学生。
- 年级主任(TC)跟班主任(TM)说开课了(全局事务),就有一个课程ID(XID)
- 学生们中间需要传播课程ID(XID)
- 同学们说我准备好了可以上课,让班主任把他们名字加入课程中
- 班主任像年级主任反应已经全部准备好了
- 年级主任掌管全局
下载安装
下载地址 : https://github.com/seata/seata/releases/download/v1.0.0/seata-server-1.0.0.zip

初始化操作
- 修改conf目录下的file.conf配置文件:
主要修改自定义事务组名称 + 事务日志存储模式为db + 数据库连接信息
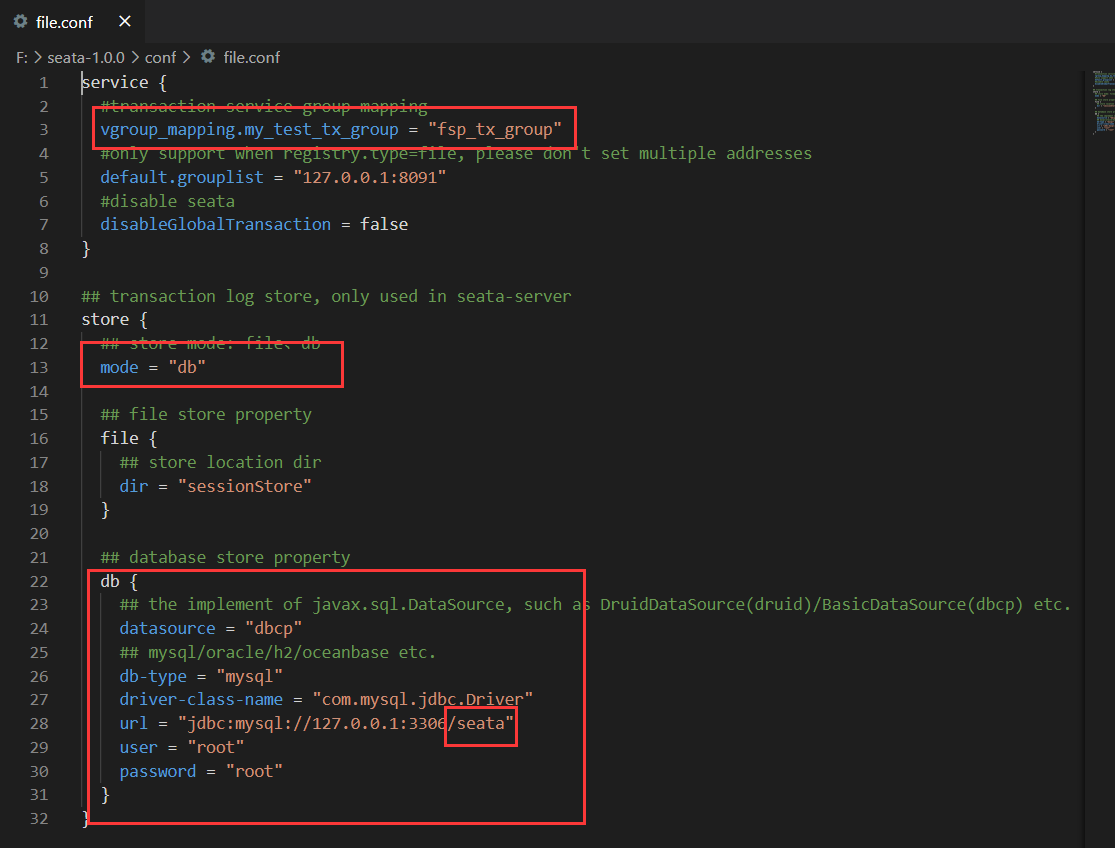
创建名和 file.conf 指定一致的数据库。
在新建的数据库里面创建数据表,db_store.sql文件在 conf 目录下(1.0.0有坑,没有sql文件,下载0.9.0的,使用它的sql文件即可)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52-- the table to store GlobalSession data
drop table if exists `global_table`;
create table `global_table` (
`xid` varchar(128) not null,
`transaction_id` bigint,
`status` tinyint not null,
`application_id` varchar(32),
`transaction_service_group` varchar(32),
`transaction_name` varchar(128),
`timeout` int,
`begin_time` bigint,
`application_data` varchar(2000),
`gmt_create` datetime,
`gmt_modified` datetime,
primary key (`xid`),
key `idx_gmt_modified_status` (`gmt_modified`, `status`),
key `idx_transaction_id` (`transaction_id`)
);
-- the table to store BranchSession data
drop table if exists `branch_table`;
create table `branch_table` (
`branch_id` bigint not null,
`xid` varchar(128) not null,
`transaction_id` bigint ,
`resource_group_id` varchar(32),
`resource_id` varchar(256) ,
`lock_key` varchar(128) ,
`branch_type` varchar(8) ,
`status` tinyint,
`client_id` varchar(64),
`application_data` varchar(2000),
`gmt_create` datetime,
`gmt_modified` datetime,
primary key (`branch_id`),
key `idx_xid` (`xid`)
);
-- the table to store lock data
drop table if exists `lock_table`;
create table `lock_table` (
`row_key` varchar(128) not null,
`xid` varchar(96),
`transaction_id` long ,
`branch_id` long,
`resource_id` varchar(256) ,
`table_name` varchar(32) ,
`pk` varchar(36) ,
`gmt_create` datetime ,
`gmt_modified` datetime,
primary key(`row_key`)
);修改 conf/registry.conf 文件内容:
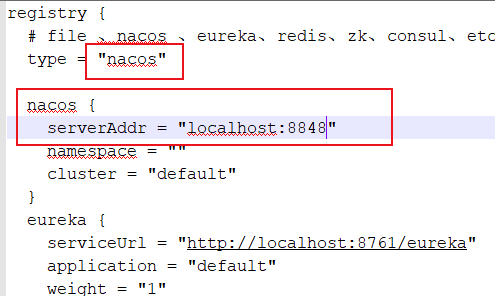
先启动 nacos Server 服务,再启动seata Server 。
启动 Seata Server 报错,在bin目录创建 /logs/seata_gc.log 文件。再次双击 bat文件启动。
案例
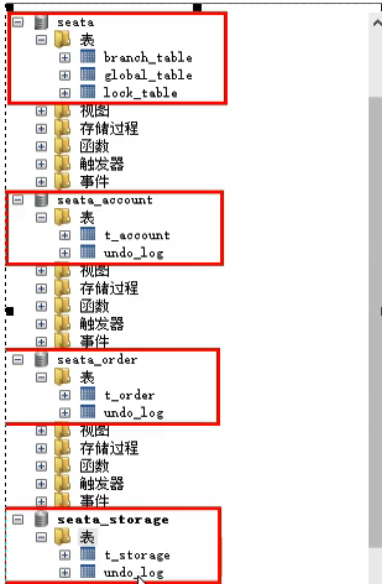
数据库准备

创建三个数据库: 
每个数据库创建数据表:
order 库:
1 | CREATE TABLE t_order( |
account 库:
1 | CREATE TABLE t_account( |
storage 库:
1 | CREATE TABLE t_storage( |
三个数据库都创建一个回滚日志表,seata/conf/ 有相应的sql文件(1.0.0没有,依然使用0.9.0中的)。
1 | CREATE TABLE `undo_log` ( |
最终效果:
开发
实现 下订单-> 减库存 -> 扣余额 -> 改(订单)状态
需要注意的是,下面做了 seata 与 mybatis 的整合,所以注意一下,和以往的mybatis的使用不太一样。
新建模块 cloudalibaba-seata-order2001 :
pom依赖:
1 | <dependencies> |
yml配置:
1 | server: |
将 seata/conf/ 下的 file.conf 和 registry.cong 两个文件拷贝到 resource 目录下。
创建 domain 实体类 : Order 和 CommonResult
dao :
1 | package com.dkf.springcloud.dao; |
Mapper文件:
1 |
|
创建service : (其中AccountService和StorageService需要用Feign知识远程服务调用)
AccountService:
1 |
|
StorageService:
1 |
|
OrderServiceImpl :
1 |
|
config (特殊点):
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
public class MybatisConfig {
}
//这个是配置使用 seata 管理数据源,所以必须配置
package com.dkf.springcloud.config;
import com.alibaba.druid.pool.DruidDataSource;
import io.seata.rm.datasource.DataSourceProxy;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.transaction.SpringManagedTransactionFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import javax.sql.DataSource;
public class DataSourceProxyConfig {
private String mapperLocations;
public DataSource druidDataSource(){
return new DruidDataSource();
}
public DataSourceProxy dataSourceProxy(DataSource dataSource){
return new DataSourceProxy(dataSource);
}
public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(mapperLocations));
sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());
return sqlSessionFactoryBean.getObject();
}
}
主启动类:
1 | //这里必须排除数据源自动配置,因为写了配置类,让 seata 管理数据源 |
controller 层调用 orderService 方法即可。
先启动 nacos —》 再启动 seata —> 再启动此order服务,测试,可以启动。
仿照上面 创建 cloudalibaba-seata-storage2002 和 cloudalibaba-seata-account2003 两个模块,唯一大的区别就是这两个不需要导入 open-feign 远程调用其它模块。
测试
我们按照—下订单->减库存->扣余额->改(订单)状态—这个过程来测试调用
http://localhost:2001/order/create?userid=1&producrid=1&counr=10&money=100
发现每个数据库都正常被操作:
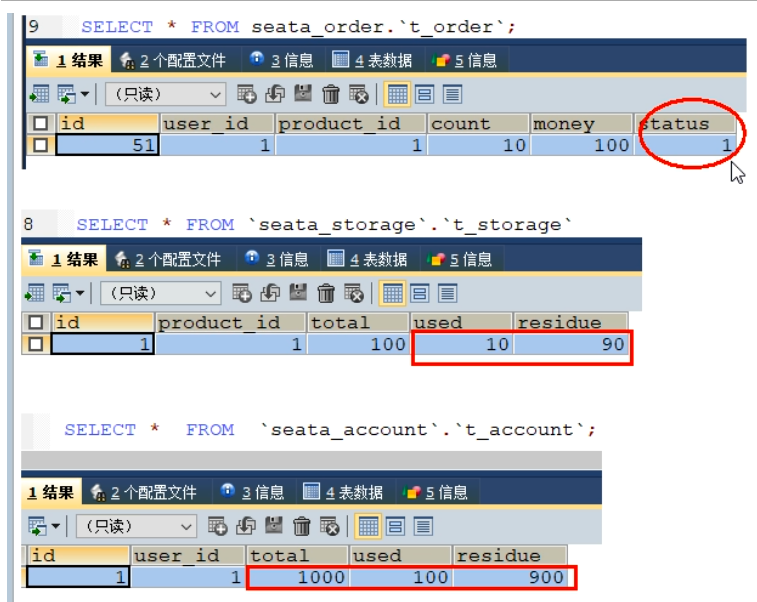
接着我们故意在AccountServiceImpl中新增超时异常,再次调用,发现如下问题:
当库存和账户余额扣减后,订单状态并没有设置为已经完成,没有从零改为1
而且由于feign的重试机制,账户余额还有可能被多次扣减
@GlobalTransactional
为了解决上述问题,我们需要用到Seata的@GlobalTransactional注解
1 |
|
再次调用有问题的方法,发现下单后数据库数据并没有任何改变,记录都添加不进来。因为他回退了
Seata原理
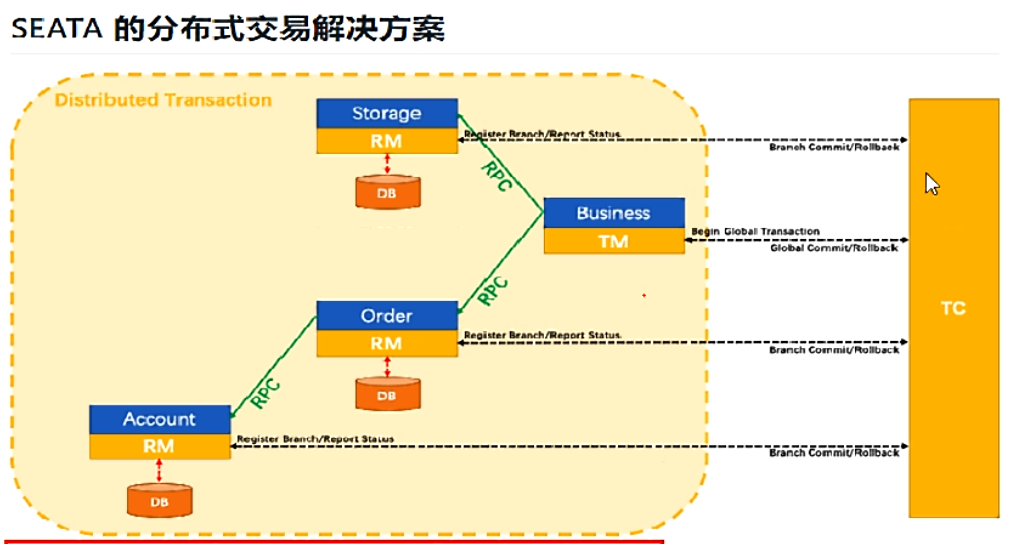
分布式事务的执行流程:
- TM开启分布式事务(TM向TC注册全局事务记录)
- 换业务场景,编排数据库,服务等事务内资源(RM向TC汇报资源准备状态)
- TM结束分布式事务,事务一阶段结束(TM通知TC提交/回滚分布式事务)
- TC汇总事务信息,决定分布式事务是提交还是回滚
- TC通知所有RM提交/回滚资源,事务二阶段结束。
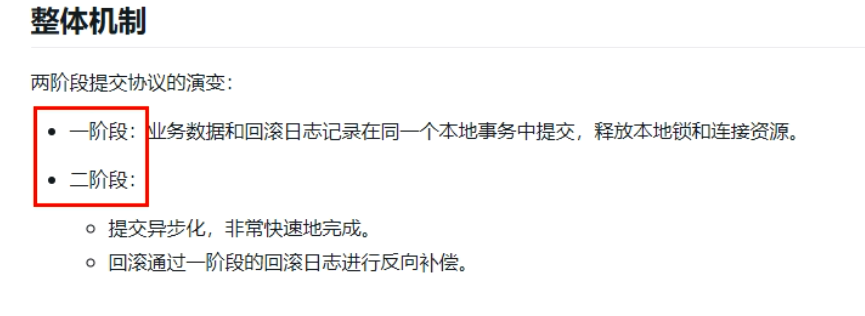
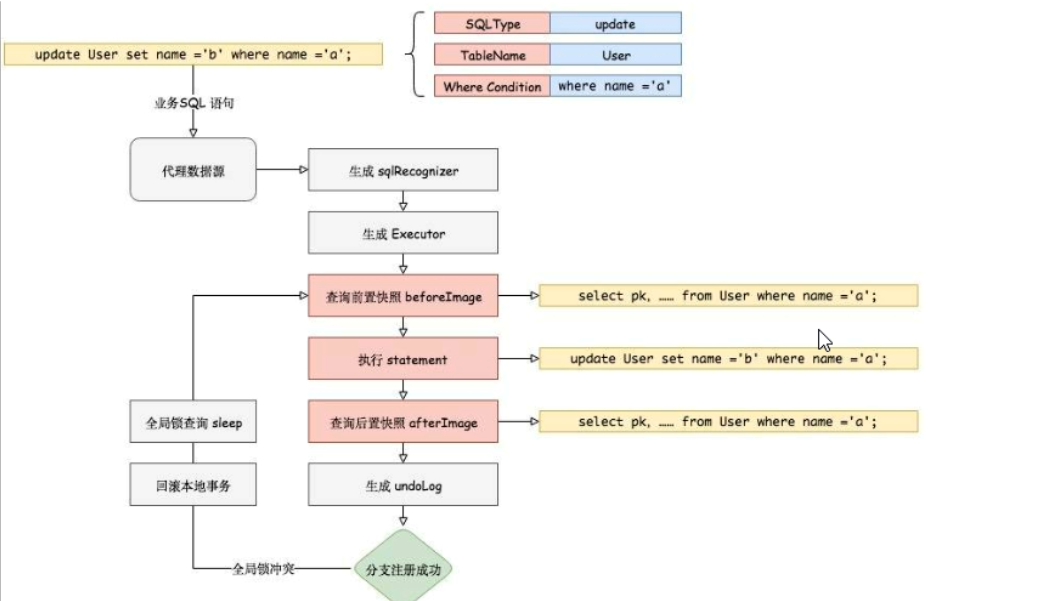
原理三个阶段:

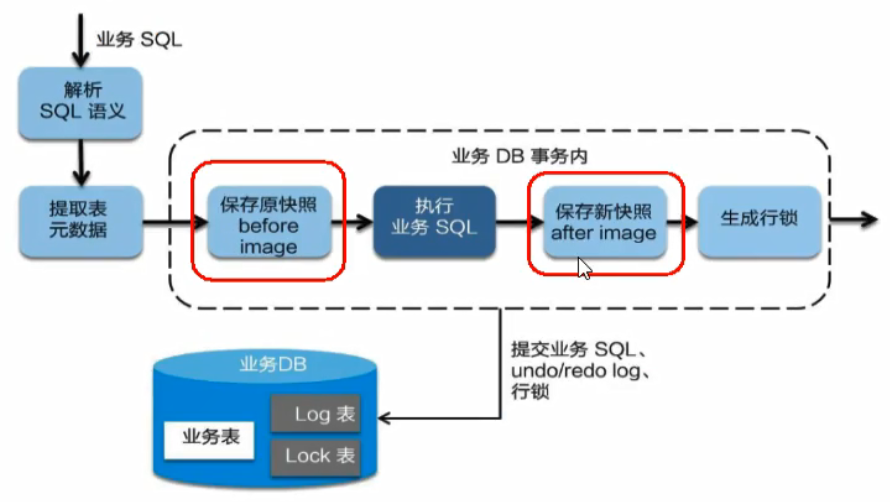
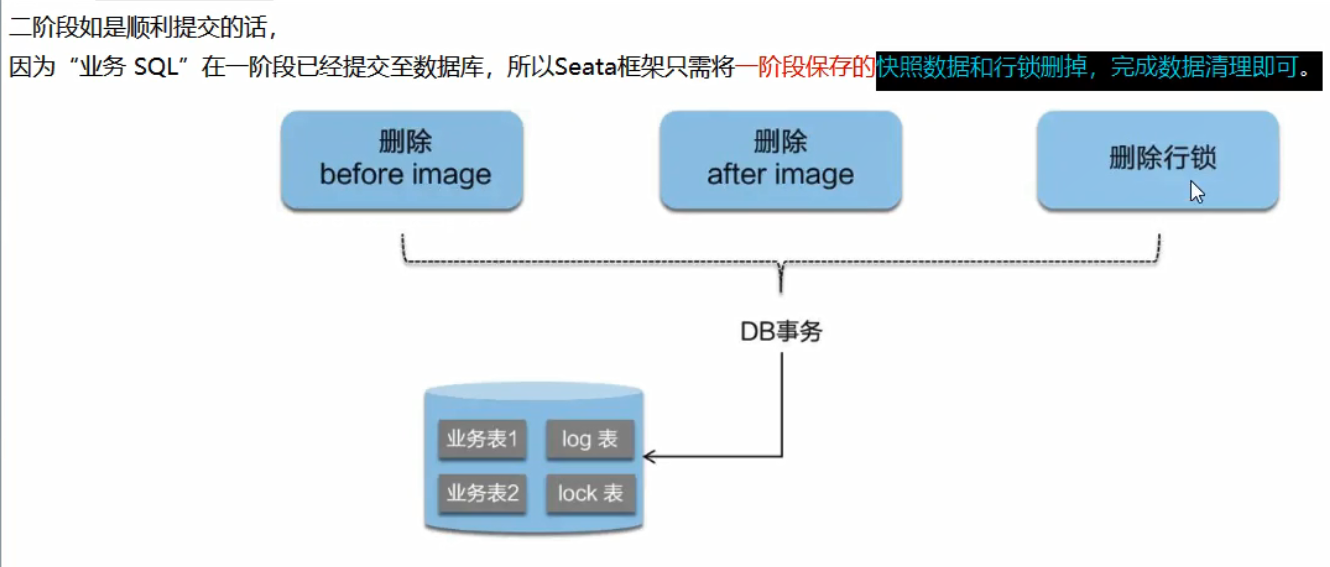


总结:
结语
断断续续差不多十天终于看完了,希望不会太早忘记吧🙃

