
EverydayOneCat
🎃万圣节快乐👻

注:由于猫眼电影网站的网页结构会发生变化,导致代码运行错误,所以下列代码仅供参考静态网页爬取流程。
1.爬取猫眼TOP100榜电影
猫眼电影库榜单网页如下所示,URL为:https://maoyan.com/board/4?offset=0
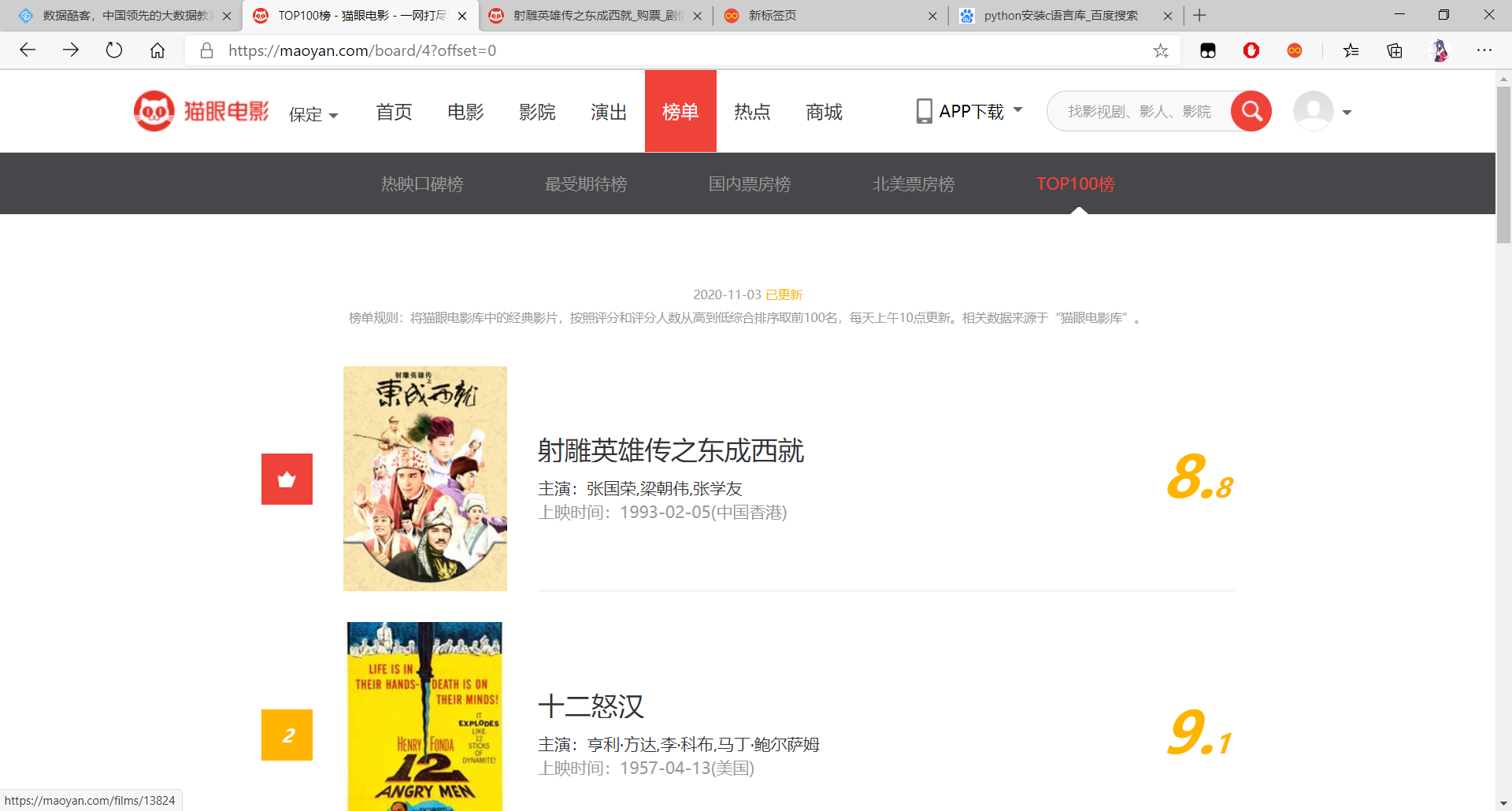
当我们选择下一页时,可以发现页面的URL变成了http://maoyan.com/board/4?offset=10 ,参数offset变为10,再点击下一页,URL变成了http://maoyan.com/board/4?offset=20 ,参数offset变成了20。
因此,我们可以总结出规律,offset代表偏移量值,由于每页仅显示10部电影,所以获取TOP100电影只需要分开请求10次,而10次的offset参数分别设置为0、10、20…90即可。
首先我们导入需要使用的库:
注:由于我们这里用的BeautifulSoup解析器为lxml,他需要安装C语言库,所以我们这边需要引入
1 | import requests |
2.提取相关信息
接下来,我们提取每部影片的相关信息,包含基本信息(片名、主演、上映时间)与热评的URL。
1 | ''' |
这里我们检查一下每个电影的模块,以此来编写获得我们想要的数据的规则
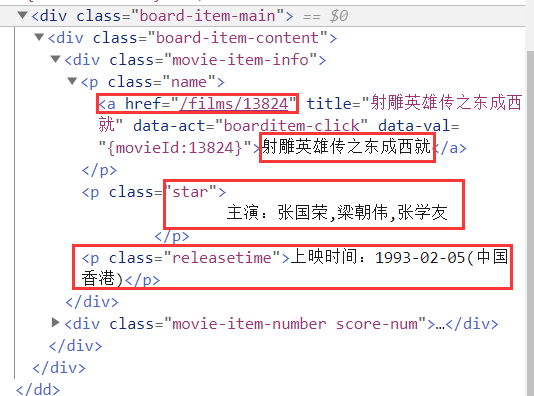
1 | # 提取热评URL |
3.爬取电影详情热评
下面我们将爬取每部影片的热评网页。接着提取每部影片的相关热评,每部影片包含10条热评。
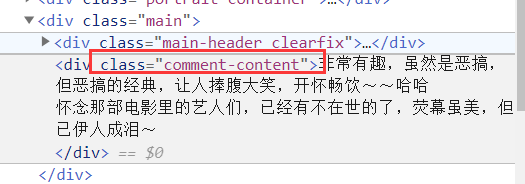
1 | ''' |
4.pandas库
pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
Pandas中常见的数据结构有两种:
| Series | DateFrame |
|---|---|
| 类似一维数组的对象 | 类似多维数组/表格数组;每列数据可以是不同的类型;索引包括列索引和行索引 |
创建数据
通过字典创建DataFrame
1 | dic_data =[{'a':1,'b':5}, |
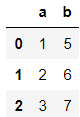
示例数据
下面使用seaborn自带的数据进行演示,Seaborn是Python的一个作图工具,示例数据名为小费数据集,该数据集包含某一酒店顾客消费金额、以及付小费的情况,还包括付账人的性别、是否吸烟,消费星期等等,具体如下:
| 特征名称 | 含义 |
|---|---|
| total_bill | 账单总额 |
| tip | 小费 |
| sex | 性别 |
| smoker | 是否抽烟 |
| day | 消费星期 |
| time | 聚餐时间段 |
| size | 聚餐人数 |
在seaborn使用load_dataset导入数据
1 | import seaborn as sns |
查看前5行
1 | data.head() |
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
value_counts()
使用value_counts()查看某一列的取值分布,例如查看消费星期的分布。
1 | data['day'].value_counts() |
1 | Sat 87 |
如上所示,day这一列中,Sat(周六)有87个样本,说明数据中有87人在周六消费。
groupby
groupby实现对数据分组统计,如下所示:
不同性别的tip(小费金额)的总和。
In [148]:
1 | data.groupby(['sex'])['total_bill'].sum() |
Out[148]:
1 | sex |
不同性别的tip(小费金额)的均值。
In [149]:
1 | data.groupby(['sex'])['total_bill'].mean() |
Out[149]:
1 | sex |
还可以按照两个变量进行分组,再求tip(小费金额)的总和。
In [150]:
1 | data.groupby(['sex','day'])['tip'].sum() |
Out[150]:
1 | sex day |
在上一步基础上,添加unstack()方法转换为DataFrame
In [151]:
1 | data.groupby(['sex','day'])['total_bill'].sum().unstack() |
Out[151]:
| day | Thur | Fri | Sat | Sun |
|---|---|---|---|---|
| sex | ||||
| Male | 561.44 | 198.57 | 1227.35 | 1269.46 |
| Female | 534.89 | 127.31 | 551.05 | 357.70 |
空值处理
检测每一列均值使用isnull().sum()
1 | data.isnull().sum() |
Out[152]:
1 | total_bill 0 |
如上所示,每一列空值数量为0,说明没有空值
如果数据中有空值可以采取如下方法:
- 删除行:删除某一列,带有空值的行,如下:删除
size这一列为空的行
In [153]:
1 | data.dropna(subset=['size'],inplace=True) |
- 删除列:
In [154]:
1 | data.drop(['size'],inplace=True) |
- 按列填充:例如将
size这一列的空值填充为未知
In [155]:
1 | data['size'].fillna('未知',inplace=True) |
替换
对于size这一列,用50替换2。
In [156]:
1 | # 替换前数据 |
Out[156]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
In [157]:
1 | data['size'] = data['size'].replace(2, 50) |
In [158]:
1 | # 替换后数据 |
Out[158]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 50 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 50 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
填充多列数据中的空值
首先填充某一列数据的空值方法如下,例如将size这一列的空值填充为未知:
data[‘size’].fillna(‘未知’,inplace=True)
如果对很多列进行填充如何实现?
在Python中简单的for循环如下:
In [98]:
1 | list_a = ['total_bill','tip'] |
对很多列进行填充,可借助for循环:
In [99]:
1 | columns = ['total_bill','tip'] |
针对某一列操作
In [100]:
1 | # 选取tip这一列存入变量s中 |
s 成为一个series对象,即一列数据
In [101]:
1 | # 提取s大于5的数据 |
Out[101]:
1 | 23 7.58 |
In [102]:
1 | # 在上一步基础上升序排列 |
Out[102]:
1 | 183 6.50 |
In [103]:
1 | # 降序排列 |
Out[103]:
1 | 170 10.00 |
提取数据:loc方法
data.loc[行名,列名]
In [104]:
1 | # 提取某一个值 |
Out[104]:
1 | 'Sun' |
In [105]:
1 | # 提取某一列 |
1 | # 提取某一行 |
Out[106]:
1 | total_bill 16.99 |
按条件提取数据
比如:提取size这一列大于5的数据
In [107]:
1 | data.loc[data['size']>5] |
Out[107]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 125 | 29.80 | 4.2 | Female | No | Thur | Lunch | 6 |
| 141 | 34.30 | 6.7 | Male | No | Thur | Lunch | 6 |
| 143 | 27.05 | 5.0 | Female | No | Thur | Lunch | 6 |
| 156 | 48.17 | 5.0 | Male | No | Sun | Dinner | 6 |
提取size这一列大于5,tip这一列
In [108]:
1 | data.loc[data['size']>5,'tip'] |
Out[108]:
1 | 125 4.2 |
修改数据
修改数据的步骤是先提取出数据,然后重新赋值即可,如下:size等于6的数据中,tip这一列设置为0
In [109]:
1 | # 修改前 |
Out[109]:
1 | 125 4.2 |
In [110]:
1 | # 修改数据 |
In [111]:
1 | # 修改后 |
Out[111]:
1 | 125 0.0 |
提取数据:不使用loc方法
In [112]:
1 | # 提取tip、size两列 |
Out[112]:
| tip | size | |
|---|---|---|
| 0 | 1.01 | 2 |
| 1 | 1.66 | 3 |
| 2 | 3.50 | 3 |
| 3 | 3.31 | 2 |
| 4 | 3.61 | 4 |
提取size取值大于5的数据
In [113]:
1 | data['size'] > 5 |
In [114]:
1 | data[data['size'] > 5] |
Out[114]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 125 | 29.80 | 0.0 | Female | No | Thur | Lunch | 6 |
| 141 | 34.30 | 0.0 | Male | No | Thur | Lunch | 6 |
| 143 | 27.05 | 0.0 | Female | No | Thur | Lunch | 6 |
| 156 | 48.17 | 0.0 | Male | No | Sun | Dinner | 6 |
In [115]:
1 | data[data['size'] > 5][['tip','total_bill','size']] |
Out[115]:
| tip | total_bill | size | |
|---|---|---|---|
| 125 | 0.0 | 29.80 | 6 |
| 141 | 0.0 | 34.30 | 6 |
| 143 | 0.0 | 27.05 | 6 |
| 156 | 0.0 | 48.17 | 6 |
计算某一列最大值、最小值、均值
In [116]:
1 | # 最大值 |
Out[116]:
1 | 10.0 |
In [117]:
1 | # 最小值 |
Out[117]:
1 | 0.0 |
In [118]:
1 | # 均值 |
Out[118]:
1 | 2.912622950819673 |
5.格式化存储
5.1zip()函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
1 | a = [1,2,3,4] |
4.2代码
1 | ''' |
项目源码
1 | #-*- codeing = utf-8 -*- |
结语
不知从什么时候起,马老师变得越来越捞了,他也渐渐的从一个技术主播变成了一个娱乐主播,有时也会忘记自己的黑切丢在哪里,曾经的大象也丢了。
师母带他去检查,发现因为长期的头铁和直播导致的缓慢性失忆。师母便不让马老师直播,每天同学们都会来到老马的直播间,却找不到那只呆头鹅。
渐渐地,马老师的记性越来越差,医生建议玩一些益智游戏,但老师病情并没有缓解,玩植物大战僵尸也经常忘了带莲叶,他也忘记了当年国服皇子叱咤风云的人是谁。
一天,曾经的学生石乐志来到马老师家请他吃饭,马老师好不容易才想起他。刚到饭店,马老师看了看表便要回家,石乐志问:“老师,您有什么急事吗?”马老师指了指表,说:“三点了,该上课了。”

