
EverydayOneCat
Cat要就此长长地睡上240小时
一、爬虫初识

网络爬虫(网络蜘蛛)原理图:
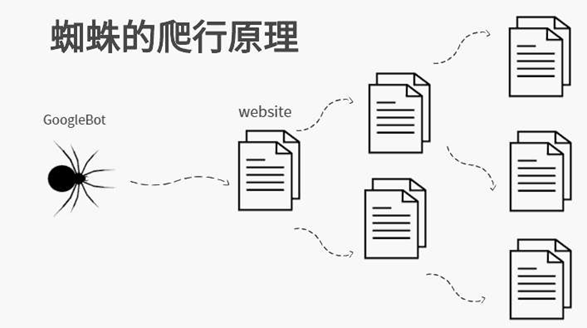
搜索引擎原理图:
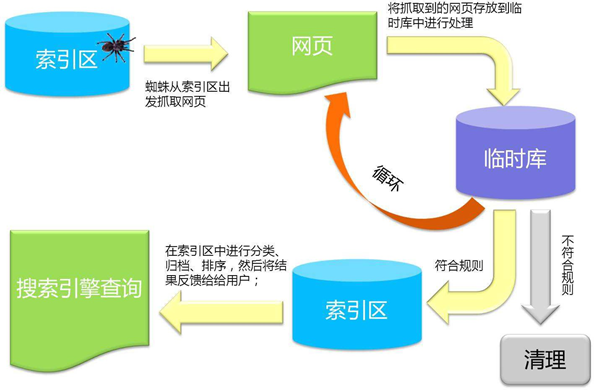
基本流程:

二、获取数据
1.urllib模块
是python内置的一个http请求库,不需要额外的安装。只需要关注请求的链接,参数,提供了强大的解析。
urllb.request 请求模块
urllib.error 异常处理模块
urllib.parse 解析模块
2.1用法
简单的一个get请求
1 | import urllib.request |
简单的一个post请求
1 | import urllib.parse import urllib.request |
超时处理
1 | data = bytes(urllib.parse.urlencode({"name":"jy","password":"xxx"}),encoding="utf-8") |
打印出响应类型,状态码,响应头:
1 | import urllib.request |
2.2简单的反爬虫处理
对于一些网站有简单的爬虫机制,普通爬虫会给你返回418错误。这时候我们需要把我们的爬虫伪装成浏览器,使得我们的爬虫能进去嗅探资源。
伪装的手段我们通过修改请求头来实现:
1 | url = "https://www.douban.com" |
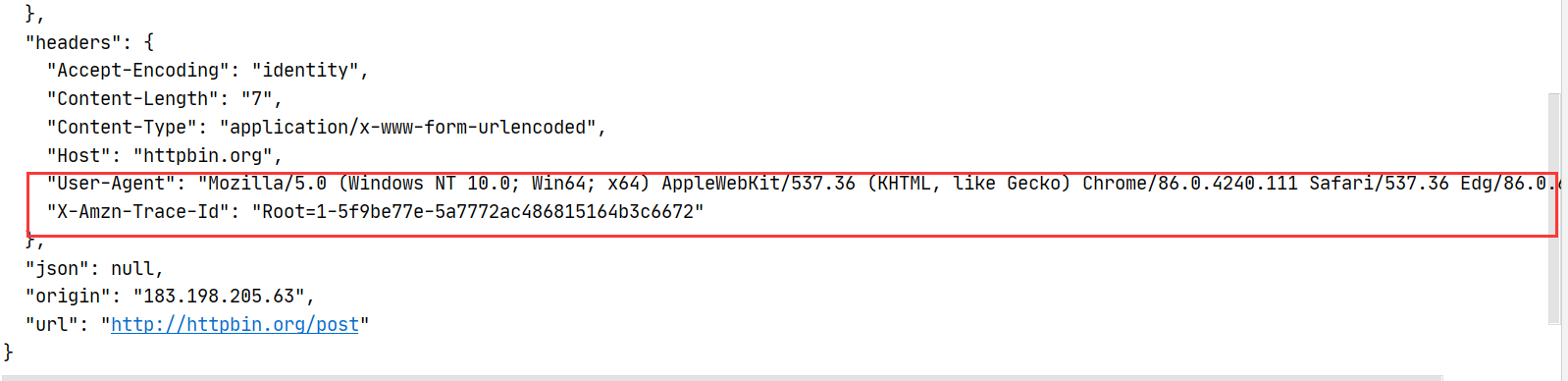
2.获取指定url的网页内容
1 | def askUrl(url): |
三、解析数据
1.BeautifulSoup模块
1.1简介
BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它, 则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
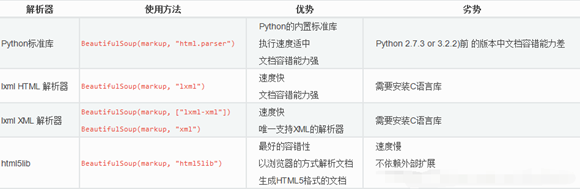
1.2Bs4用法
1 | from bs4 import BeautifulSoup |
1.3搜索文档树
1 | #字符串过滤:查找与字符串完全匹配的内容 |
2.Re模块
2.1正则表达式
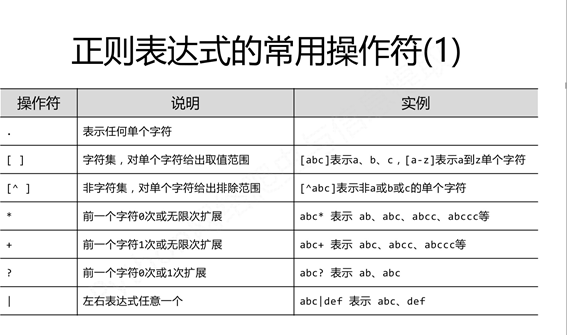
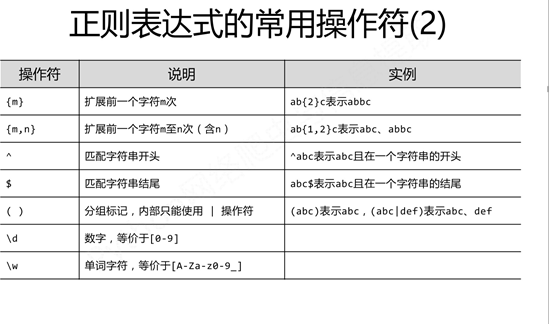
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。 多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
2.2re模块下的函数
1 | import re |
3.提取数据
正则表达式抽取:
1 | ''' |
获取数据:
1 | def getData(baseUrl): |

4.保存数据
4.1xlwt模块
1 | import xlwt |
4.2保存数据到Excel
1 | def saveData(dataList,savepath): |
4.3sqlite3模块
1 | import sqlite3 |
4.4数据库存储
1 | #datalist是封装好的数据,dbpath是数据库文件存放的全路径 |
四、整合
1.爬取豆瓣Top250完整代码
1 | #-*- codeing = utf-8 -*- |
2.结果
结语
旧王已经复苏,哎,lck的统治又要来了吗😭

