
EverydayOneCat
卡其脱离太!

知识点
1.大数据的MATLAB导入导出
1.1调用xlsread函数读取数据
常用格式:
- num = xlsread(filename, sheet, range)
- sheet可省略,默认是’Sheet1’
- range是左上角到右下角
- 切记在全国大学生数学建模赛中不要用绝对路径
- num = xlsread(filename, -1)
- 这个是打开excel表让你自己选择区域,也很常用
将数据A.xlsx放入默认路径下,读取文件A.xlsx第1个工作表中单元格A2:H4中的数据
1 | num=xlsread('A.xlsx', 'A2:H4') |
1.2把数据写入Excel文件
- xlswrite(filename, M, sheet, range)
- M是需要插入的数据名称
- 如果没有该文件,会自动创建一个
把矩阵x写入文件B.xls(放在默认路径下)的第2个工作表中的单元格区域D6:I10,并返回操作信息
1 | [s,t] = xlswrite(‘B.xls', x, Sheet2, 'D6:I10‘) |
定义一个元胞数组,将它写入Excel文件B.xls的自命名工作表的指定区域;把元胞数组x写入文件D盘的B.xls的指定工作表(Sheet1)中的单元格区域A3:F5
1 | x = {1,60101,6010101,'陈亮',63,'';2,60101,6010102,'李旭',73,'';3,60101,... |
2.大数据的清洗
2.1缺失值处理:插值
在实际中,常常要处理由实验或测量所得到的一些离散数据。插值与拟合方法就是要通过这些数据去确定某一类已知函数的参数或寻求某个近似函数,使所得到的近似函数与已知数据有较高的拟合精度。此类问题为插值问题。
MATLAB 实现:实现分段线性插值不需要编制函数程序,它自身提供了内部的功能函数:
interp1 (一维插值) intep2 (二维) interp3 (三维) intern (n维)

例:从1点12点的11小时内,每隔1小时测量一次温度,测得的温度的数值依次为:5,8,9,15,25,29,31,30,22,25,27,24.试估计每隔1/10小时的温度值。
1 | hours=1:12; |
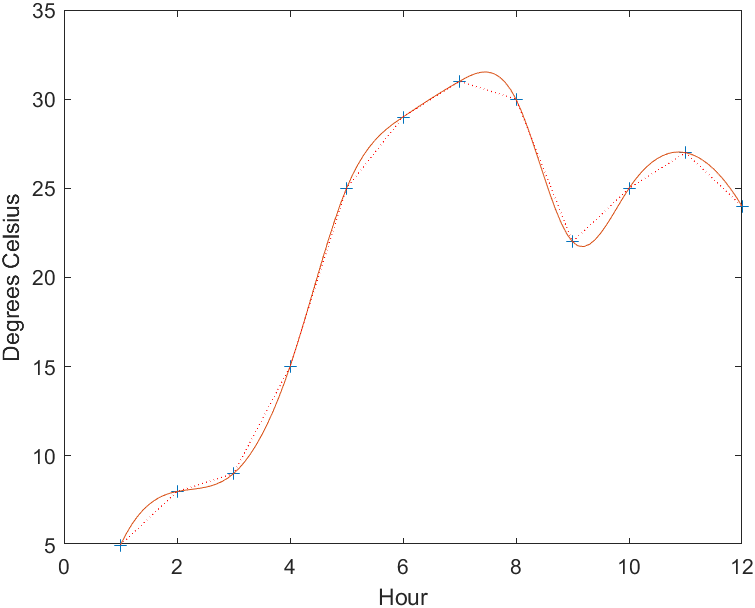
+++

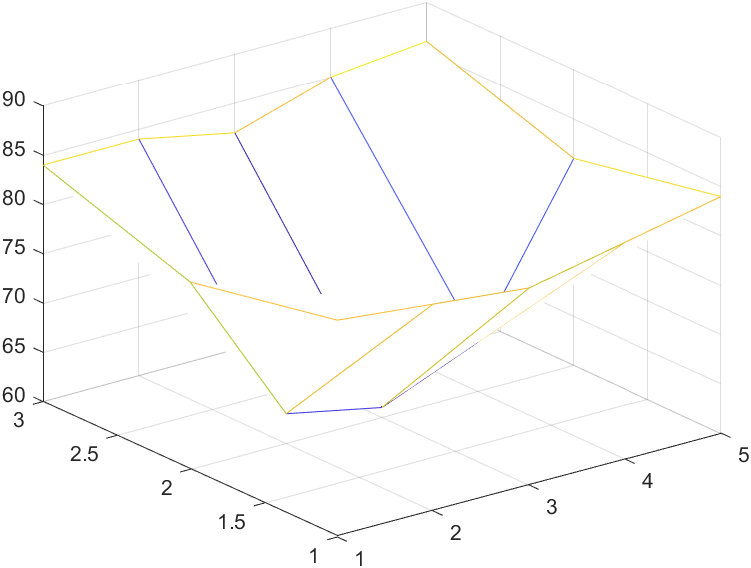
例:测得平板表面3×5网格点处的温度分别为:
82 81 80 82 84
79 63 61 65 81
84 84 82 85 86
试作出平板表面的温度分布曲面z=f(x,y)的图形.
1.先在三维坐标画出原始数据,画出粗糙的温度分布曲线图
1 | x=1:5; |
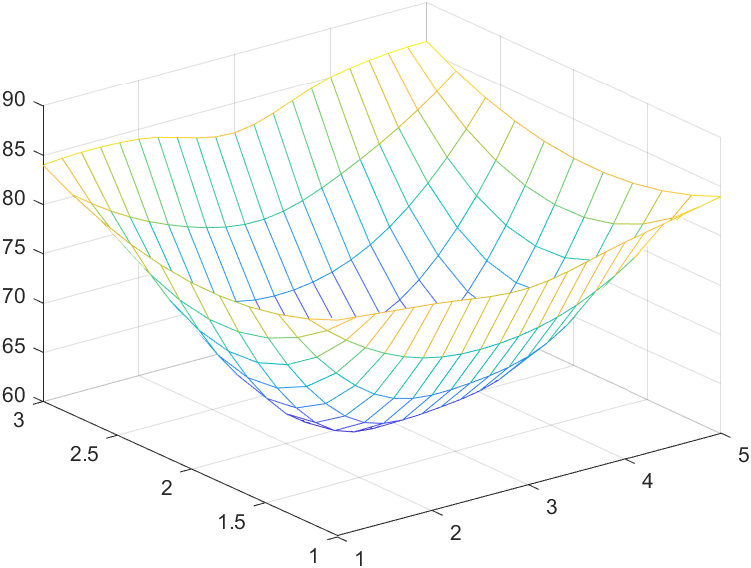
2.以平滑数据,在x、y方向上每隔0.2个单位的地方进行插值,接着画图的图像就更有观测性
1 | xi=1:0.2:5; |
+++

例:在某海域测得一些点(x,y)处的水深z由下表给出,船的吃水深度为5英尺,在矩形区域(75,200)×(-50,150)里的哪些地方船要避免进入.
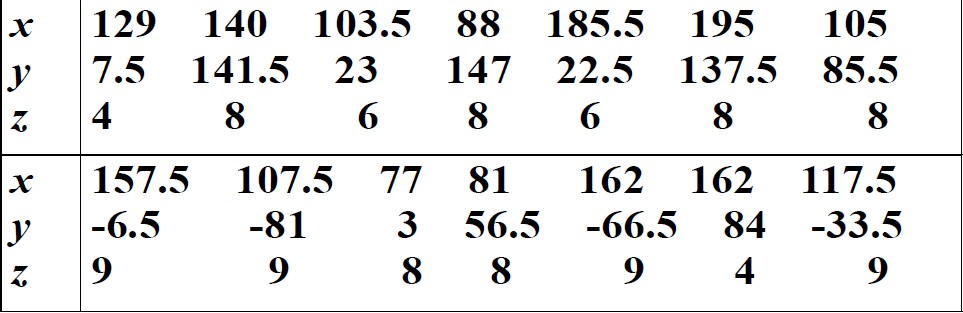
做题步骤:
- 输入插值基点数据
- 在矩形区域(75,200)×(-50,150)进行插值。
- 作海底曲面图
- 作出水深小于5的海域范围,即z=5的等高线.
1 | %程序1:插值并作海底曲面图 |
海底曲面图:
1 | %程序2:插值并作出水深小于5的海域范围。 |
水深小于5的海域范围: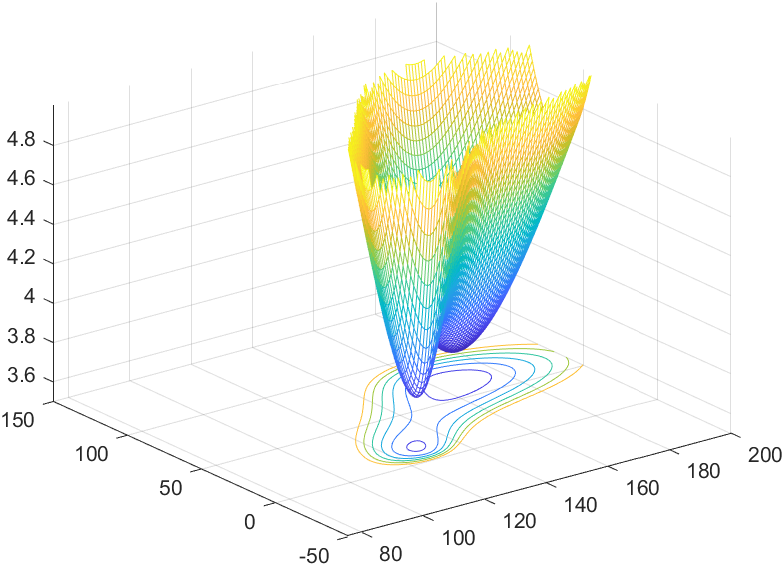
2.2异常值处理
异常是在数据集中偏离大部分数据的数据,使人怀疑这些数据的偏离并非由随机因素产生,而是产生于完全不同的机制。
异常挖掘(outlier mining)问题由两个子问题构成:
• (1)如何度量异常;
• (2)如何有效发现异常。
(1)基于统计的异常检测

基于统计方法异常点检测技术的优缺点:
• 优点:
1)异常点检测的统计学方法具有坚实的基础,建立在标准的
统计学技术(如分布参数的估计)之上。
2)当存在充分的数据和所用的检验类型的知识时,这些检验
可能非常有效。
• 缺点:
1)大部分统计方法都是针对单个属性的,对于多元数据技术方法较少。
2)在许多情况下, 数据分布是未知的。
3)对于高维数据, 很难估计真实的分布。
(2)基于聚类的异常检测
物以类聚——相似的对象聚合在一起,基于聚类的异常点检测方法有两个共同特点:
(1)先采用特殊的聚类算法处理输入数据而得到聚类,再在聚类的基础上来检测异常。
(2)只需要扫描数据集若干次,效率较高,适用于大规模数据集。

其中对象p到每个类之间的距离d(p,Ci)有两种计算方法:
- p与类Ci的重心之间的距离;
- p与类Ci中每个样本之间的距离的平均值。
以上异常点检测方法也称为两阶段法,也简称为TOD。
基于聚类的方法:具体程序见程序TOD.m
1 | function yichang=TOD(A) |
在命令窗口输入
1 | A=xlsread('A.xlsx'); yichang=TOD(A) |
运行,得到运行结果:yichang显示1的就是异常
作业
1.异常点
用所学的方法找出book_A中的异常点(红色标号)
文件链接:https://pluto-1300780100.cos.ap-nanjing.myqcloud.com/download/Book_A.xlsx
1 | A=xlsread('Book_A.xlsx','C2:R790'); |
2.城市表层土壤重金属污染分析
随着城市经济的快速发展和城市人口的不断增加,人类活动对城市环境质量的影响日显突出。对城市土壤地质环境异常的查证,以及如何应用查证获得的海量数据资料开展城市环境质量评价,研究人类活动影响下城市地质环境的演变模式,日益成为人们关注的焦点。
按照功能划分,城区一般可分为生活区、工业区、山区、主干道路区及公园绿地区等,分别记为1类区、2类区、……、5类区,不同的区域环境受人类活动影响的程度不同。
现对某城市城区土壤地质环境进行调查。为此,将所考察的城区划分为间距1公里左右的网格子区域,按照每平方公里1个采样点对表层土(0~10 厘米深度)进行取样、编号,并用GPS记录采样点的位置。应用专门仪器测试分析,获得了每个样本所含的多种化学元素的浓度数据。另一方面,按照2公里的间距在那些远离人群及工业活动的自然区取样,将其作为该城区表层土壤中元素的背景值。
附件1列出了采样点的位置、海拔高度及其所属功能区等信息,附件2列出了8种主要重金属元素在采样点处的浓度,附件3列出了8种主要重金属元素的背景值。
对2011年全国建模A的数据,进行插值,画出该地区的地形图,同时绘出各金属污染物的密度分布图
地形图:
1 | x=xlsread('cumcm2011A附件_数据.xls','附件1','B4:B322'); |
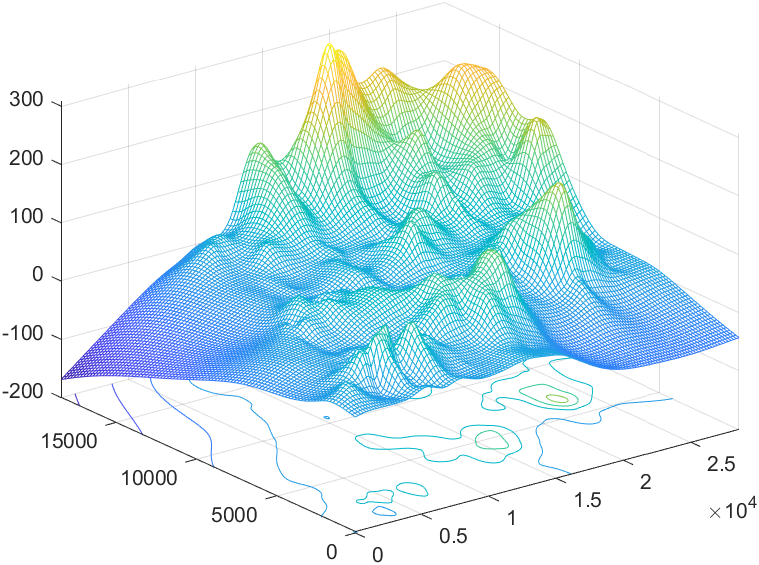
金属污染物密度分布图:
1 | x=xlsread('cumcm2011A附件_数据.xls','附件1','B4:B322'); |
As密度分布图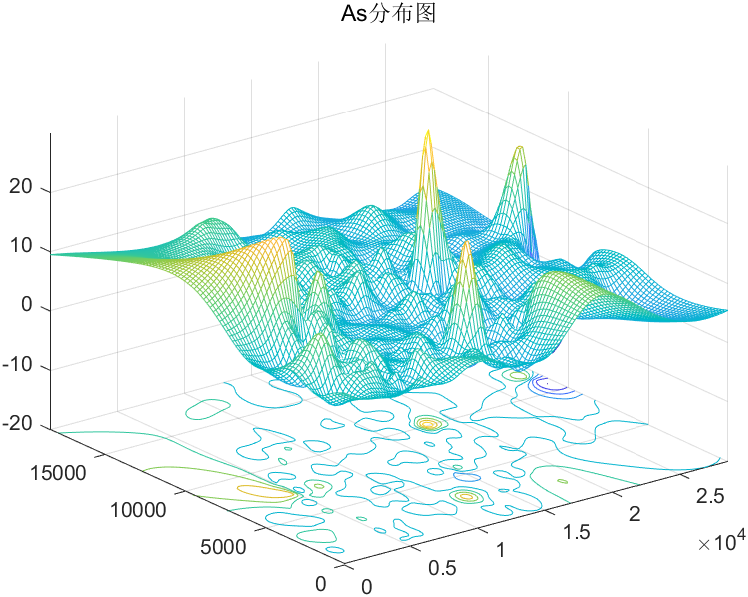
Cd密度分布图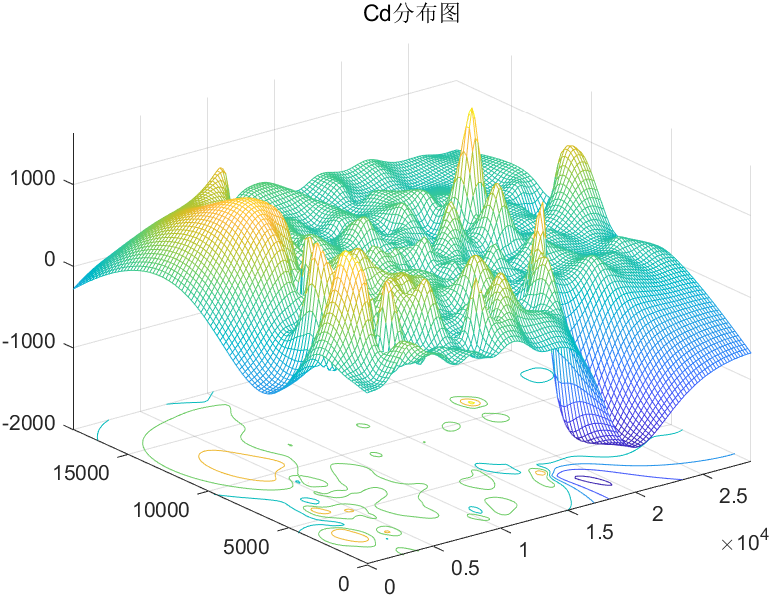
Cr密度分布图
Cu密度分布图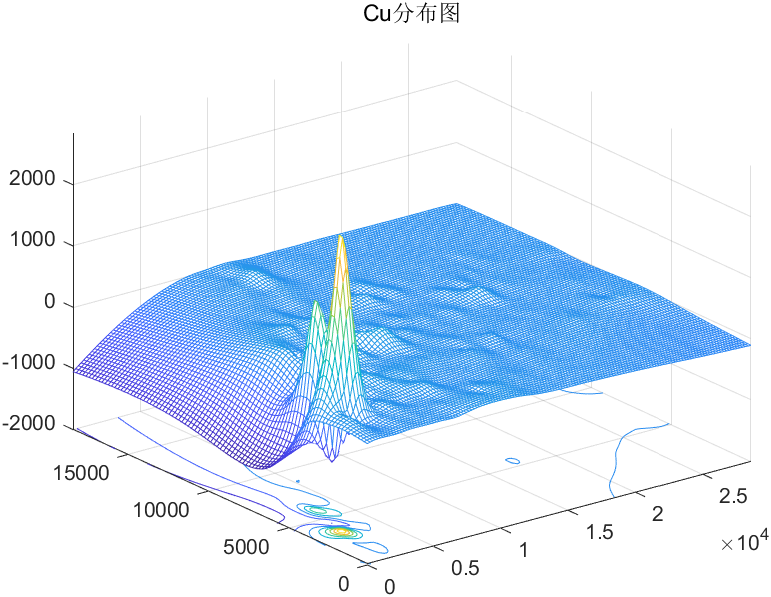
Hg密度分布图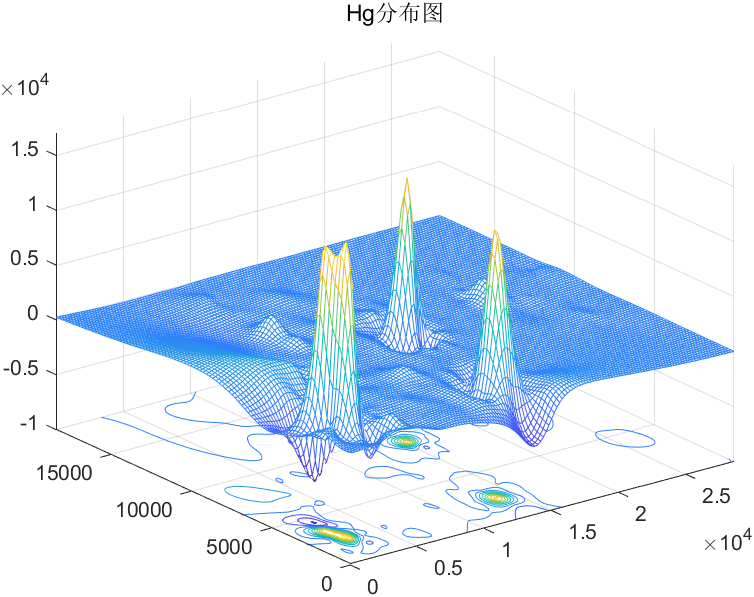
Ni密度分布图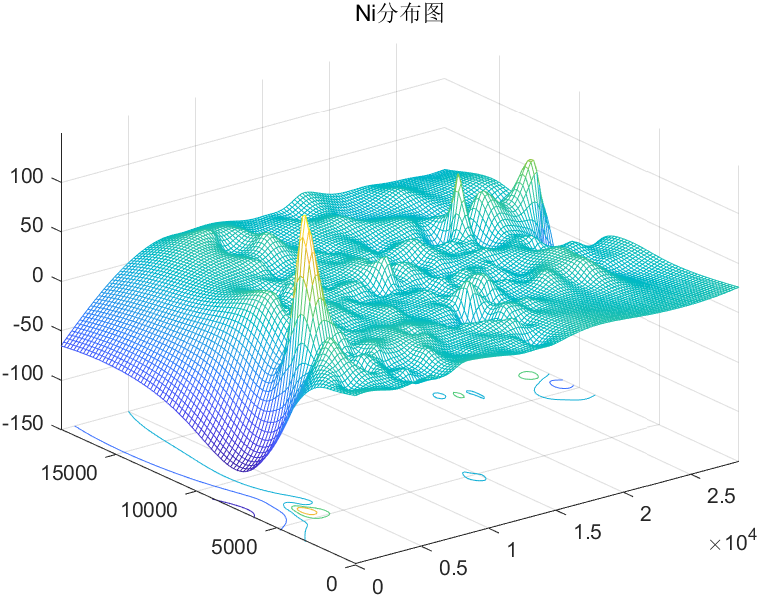
Pb密度分布图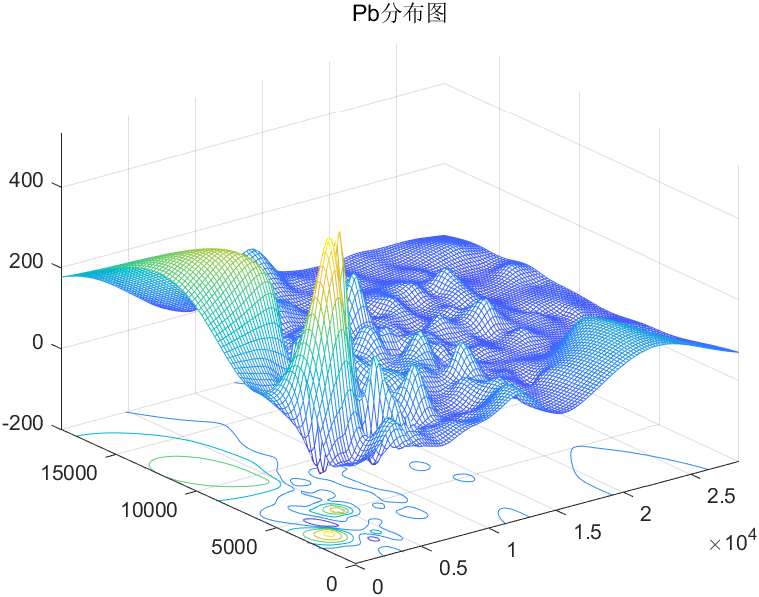
Zn密度分布图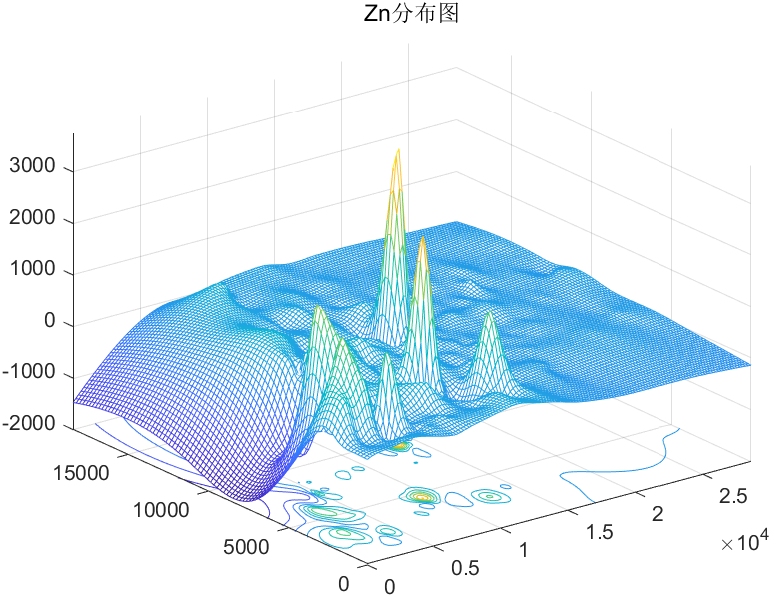
结语
Let life be beautiful like summer flowers and death like autumn leaves
要为六级做准备了😥

