
EverydayOneCat
海洋!
知识点
1.笔记



2.平稳性检验
时序图检验:根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常数值附近随机波动,而且波动的范围有界、无明显趋势及周期特征。
自相关图检验:平稳序列通常具有短期相关性。该性质用自相关系数来描述就是随着延迟期数的增加,平稳序列的自相关系数会很快地衰减向零。
SAS代码:
1 | data a; |
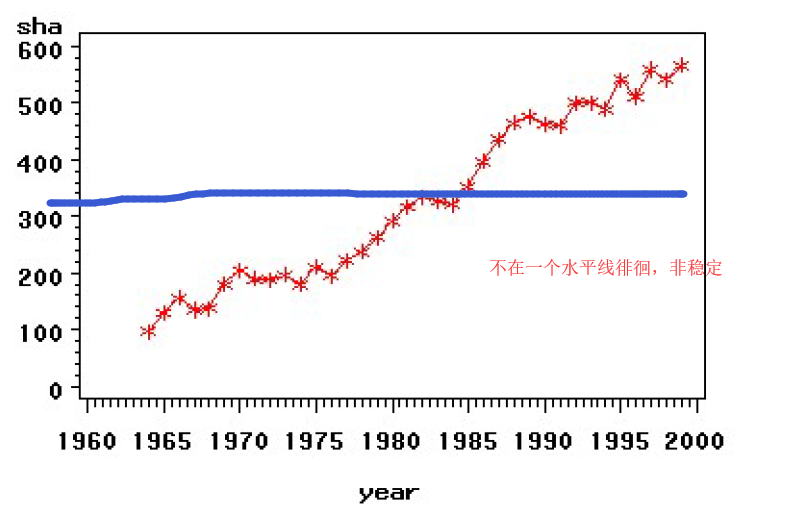
此图没有明显周期,也没有明显趋势,基本可以判断是平稳的
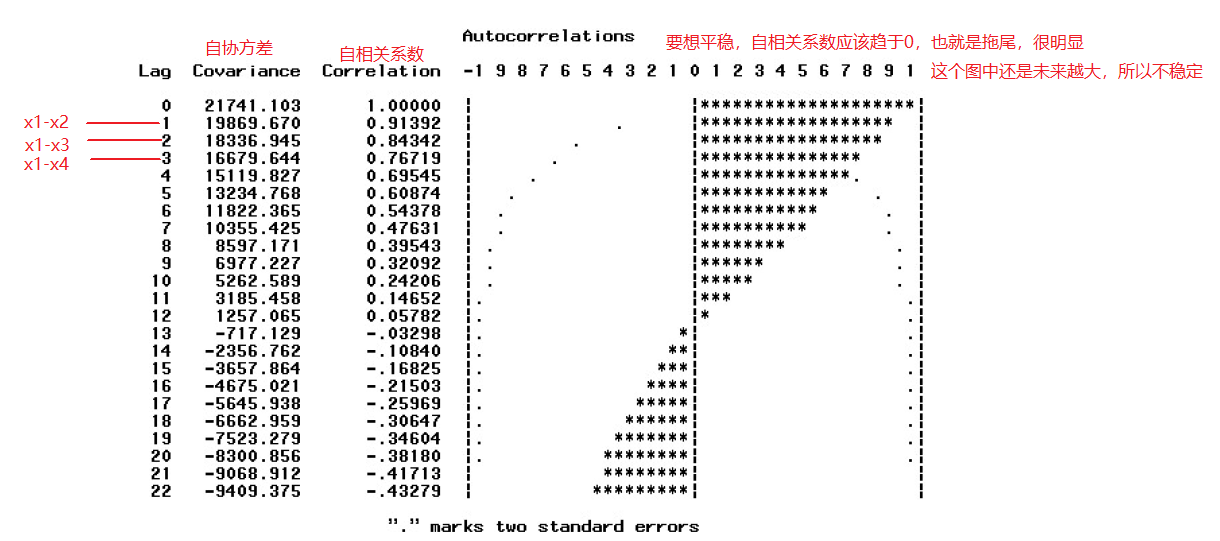
延迟了1步之后,他的相关系数稳定接近于0,说明这个序列具有短期相关性。
2.纯随机性检验
纯随机序列也称为白噪声序列,标准正态白噪声序列时序图
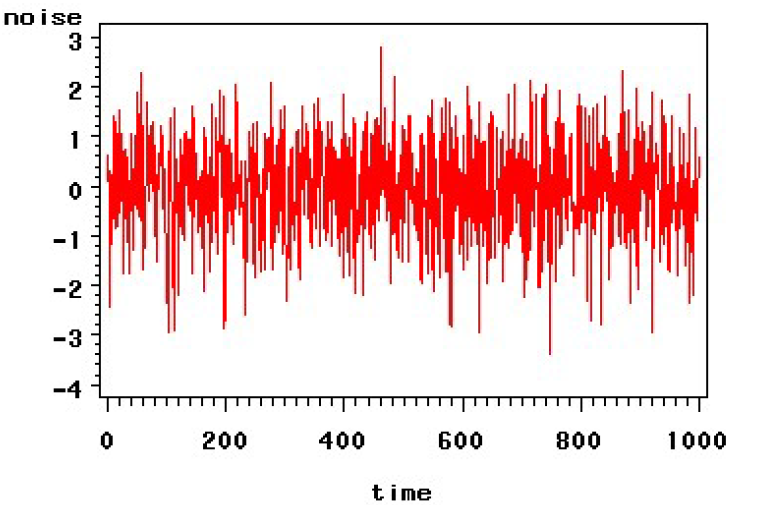
1、首先判断是否平稳,平稳后才能判断是否纯随机
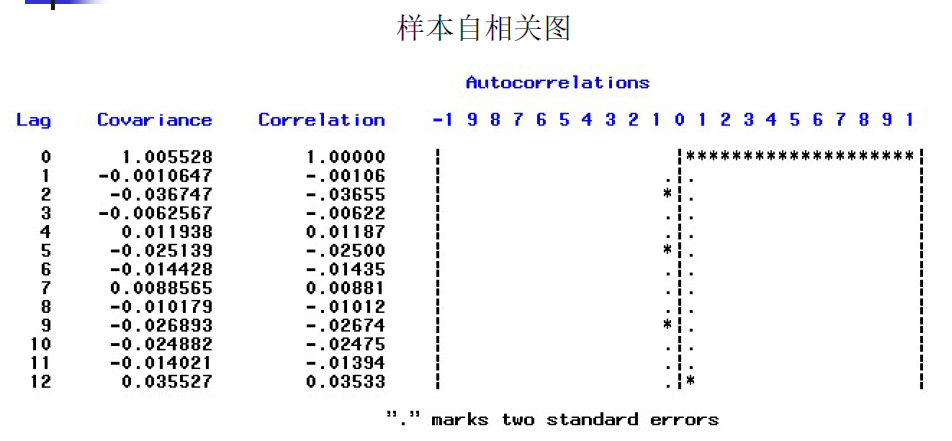
2、白噪声检验
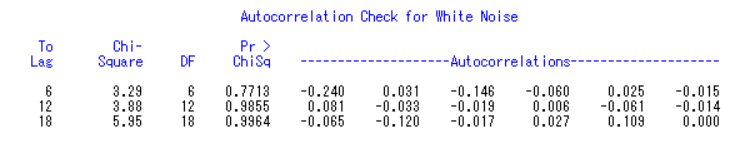
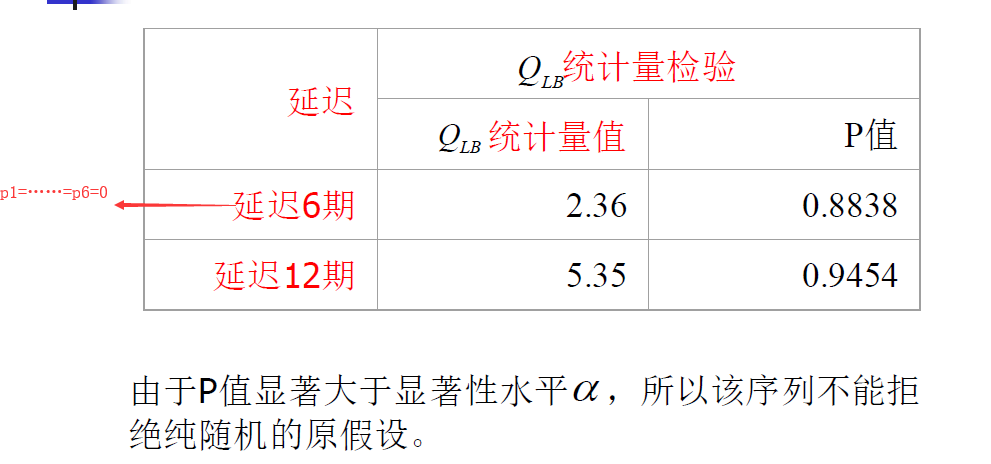
3.平稳时间序列建模
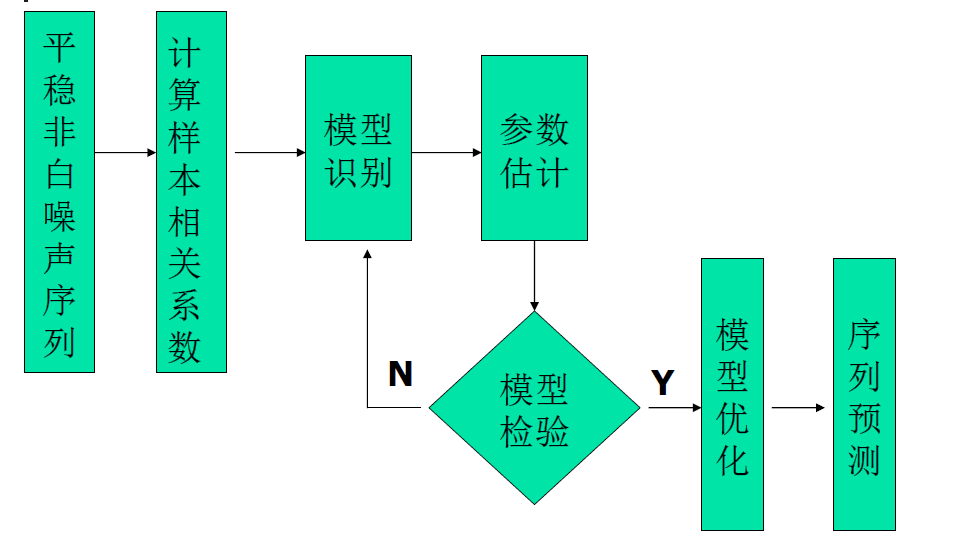
选择合适的模型ARMA拟合1950年——1998年北京市城乡居民定期储蓄比例序列。
先进行平稳性检验:
1 | data a; |
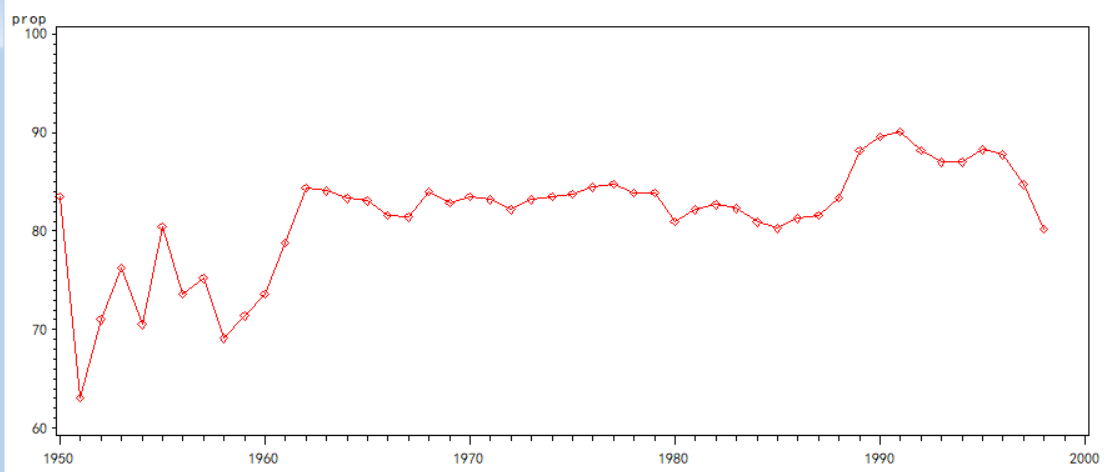

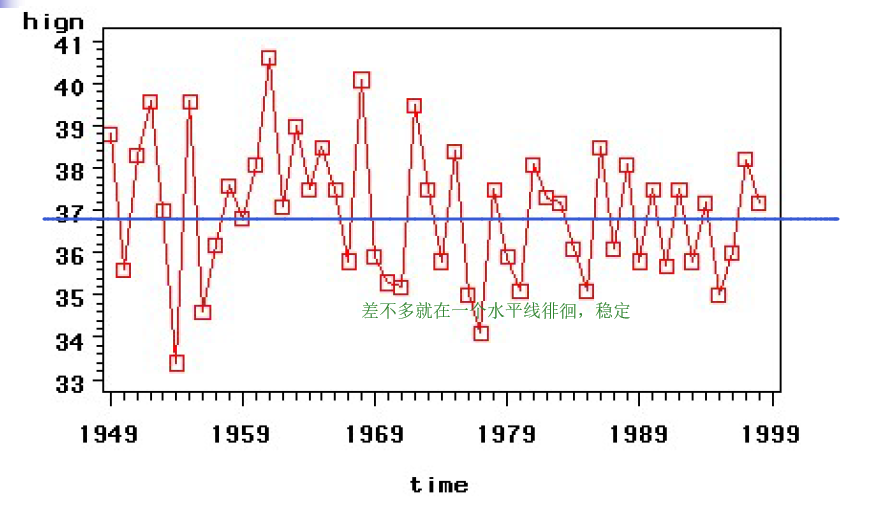
在0上下波动,说明此序列平稳。
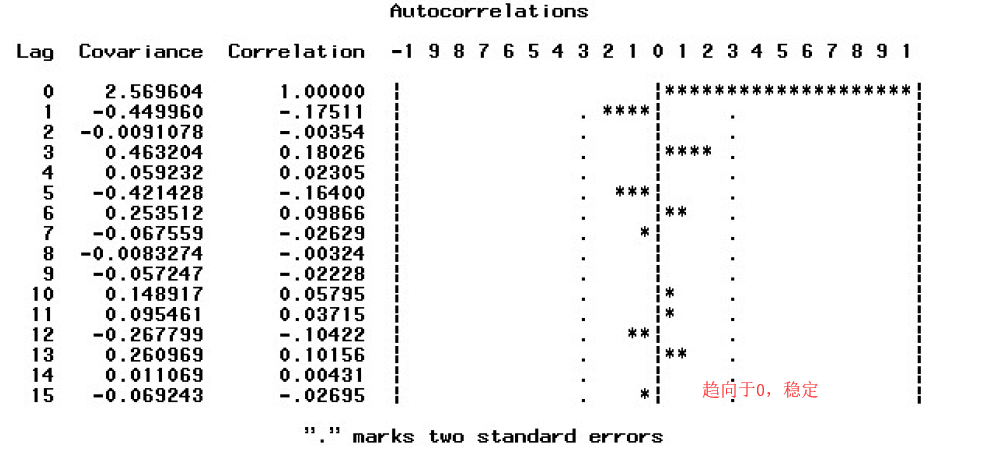
白噪声检验:
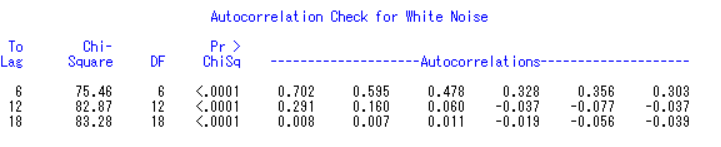
拒绝原假设H0:p1=……=pi=0,说明序列之间有信息传递,是可以做一个ARMA模型的。
相对最优定阶方法:
为了尽量避免因个人经验不足导致的模型识别问题,SAS系统还提供了相对最优模型识别。只要在identify命令中加上一个可选命令minic,就可以获得一定范围内的最优模型定界。
修改代码:
1 | identify var=prop nlag=22 minic p=(0:5) q=(0:5); |
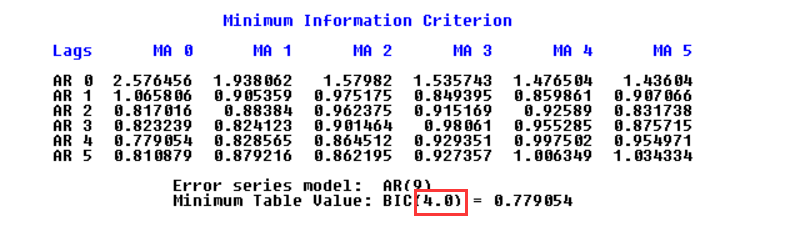
说明p=4,q=0。推断出为AR模型
增加SAS代码:
1 | estimate p=4 q=0; |

发现2,3,4没通过t检验。修改p=1

可得出AR模型公式,类似于下图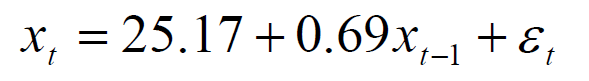

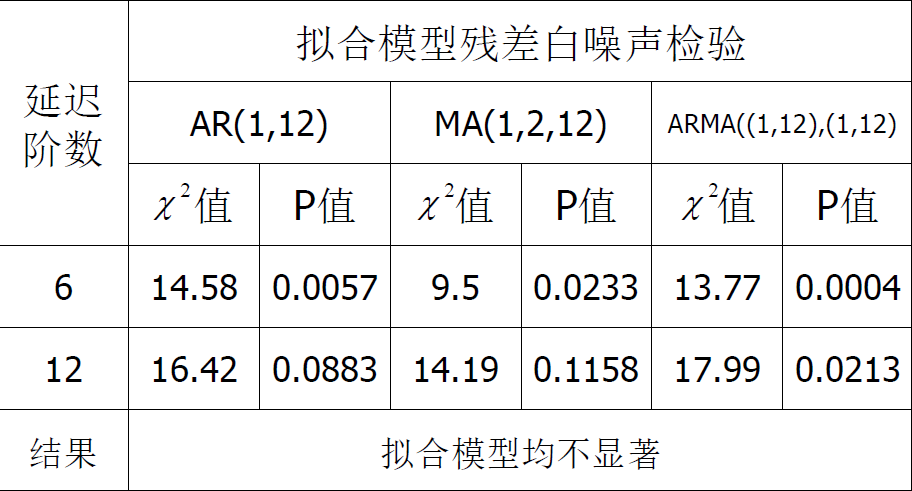
残差需要接受白噪声检验。可以看出所有的都接受了原假设:残差序列为白噪声序列

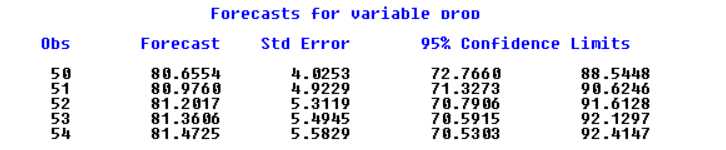
编写预测代码:
1 | forecast id=year lead=5 out=out; |
编写代码画图:
1 | proc gplot data=out; |
4.非平稳序列差分方式的选择
1、原序列时序图:
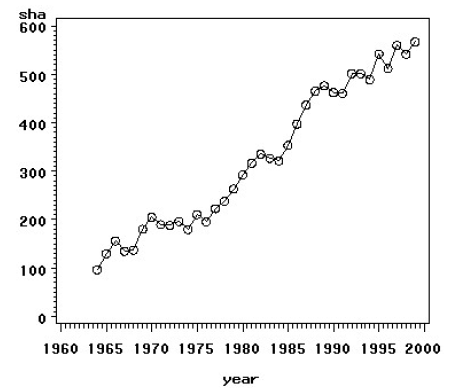
差不多呈线性,我们使用一阶差分,差分后序列时序图:
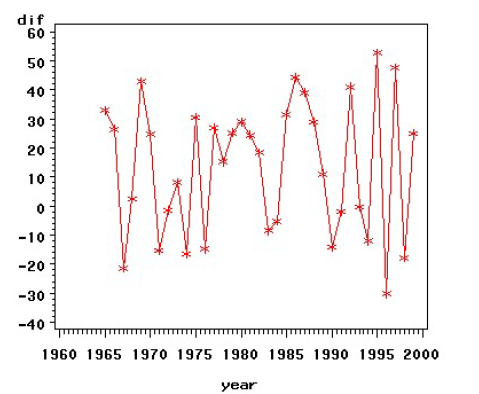
2、原序列时序图:
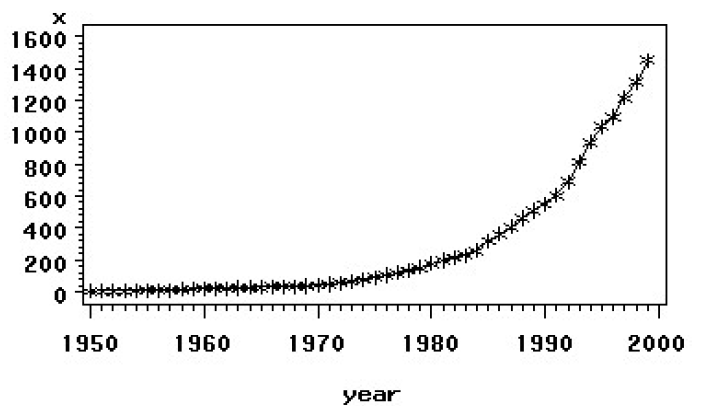
曲线趋势,我们选择二阶差分:
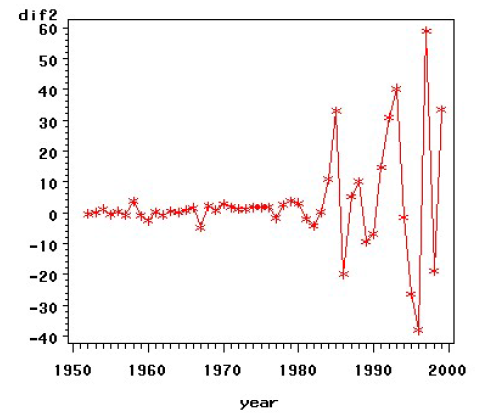
3、原序列时序图:
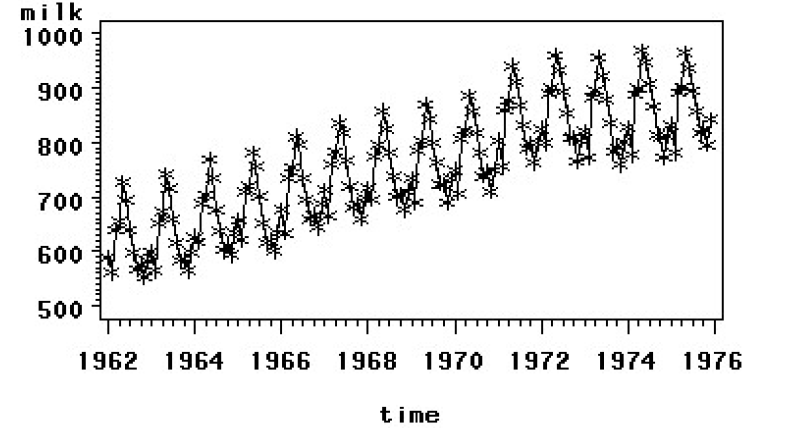
差不多可以看出来是周期,我们通过SAS来观测周期时长
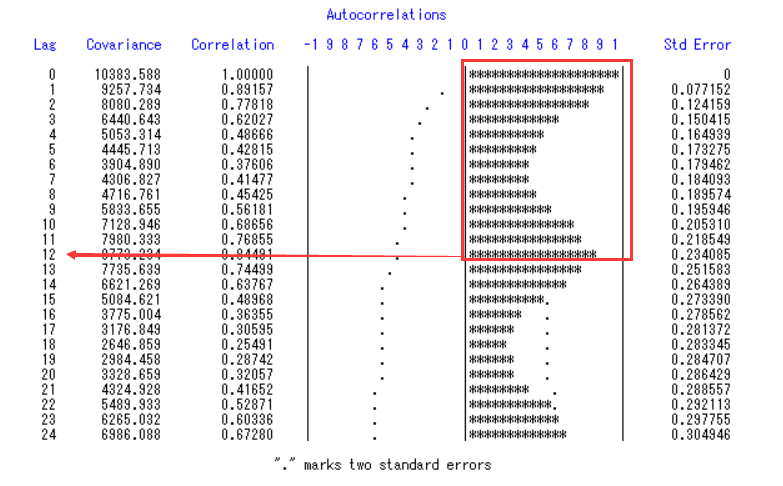
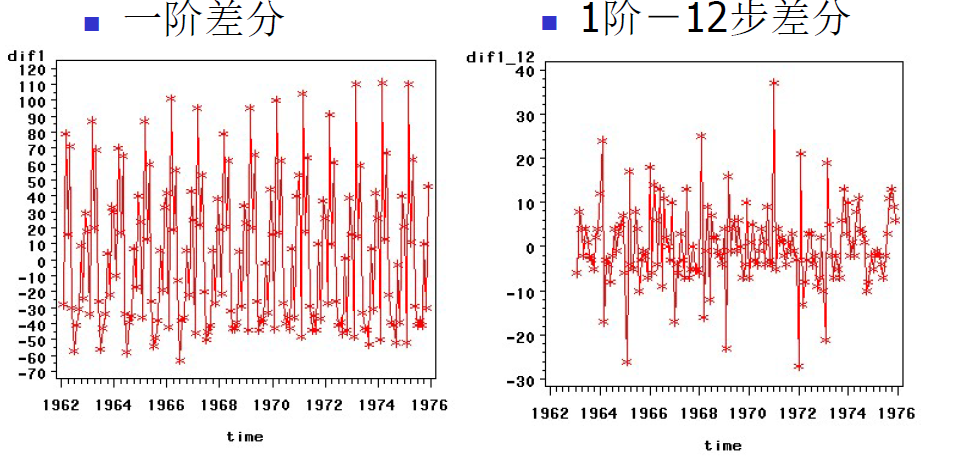
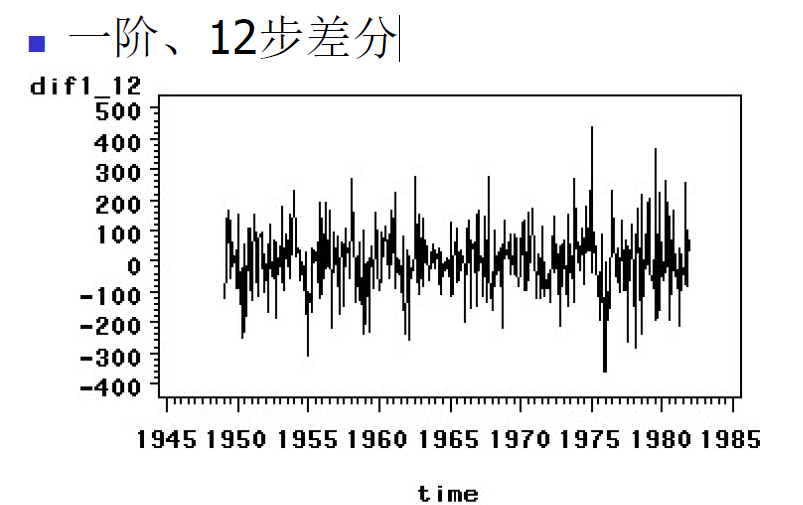
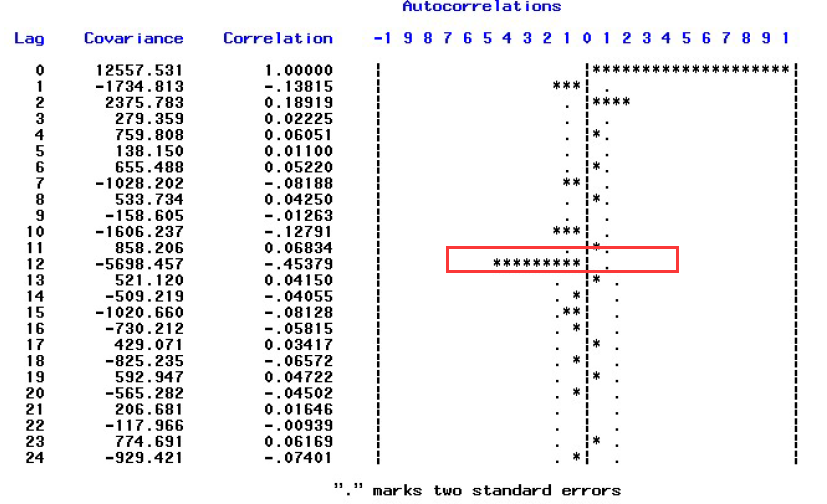
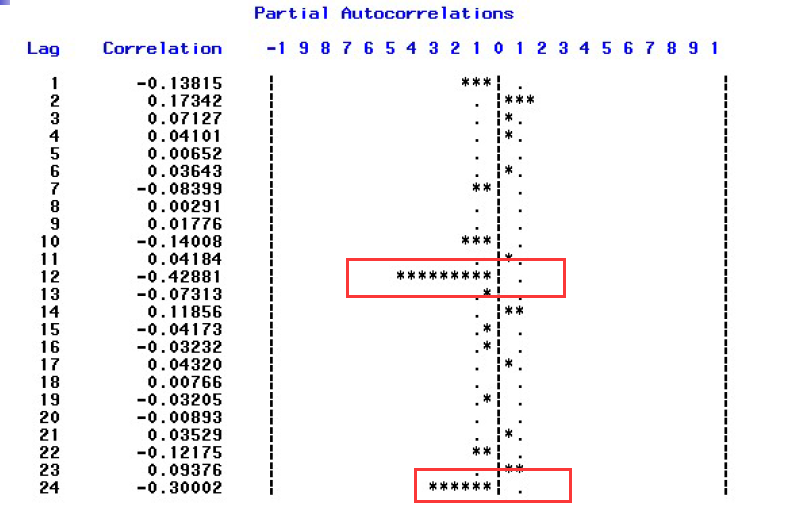
可以看出周期为12,我们先做一阶差分,再做12步差分:
5.ARIMA模型建模步骤

对1952年——1988年中国农业实际国民收入指数序列建模
SAS代码:
1 | goptions vsize=7cm hsize=10cm; |
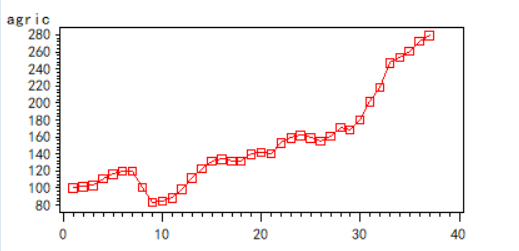
有向上发展的趋势,我们需要进行差分
一步(一阶)差分:dif(xx)
二部差分:dif2(xx)
二阶差分:dif(dif(xx))
修改SAS代码:
1 | goptions vsize=7cm hsize=10cm; |
自相关系数图:

可以看出差不多在0左右徘徊,我们再来看看时序图:
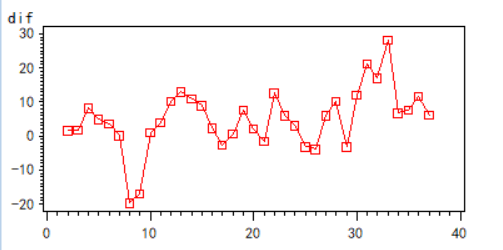
综合以上,基本稳定。接着我们看一阶差分之后的白噪性检验:

只要有一个里面比0.05小,就说明有信息传递,可以用时间序列拟合。
接下来做一阶差分的模型识别,修改SAS代码:
1 | identify var=dif nlag=18 minic p=(0:5) q=(0:5); |
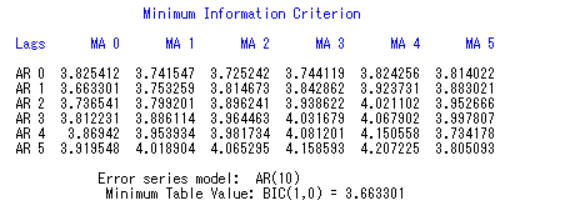
得到p=1,q=0,模型为ARIMA(1,1,0)(中间参数是代表阶数)
模型的检验:
1 | estimate p=1; |
进行参数的检验:

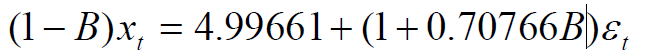
对模型进行显著性检验,即对残差序列进行白噪声检验:

都大于0.05,接受原假设,说明残差之间没有信息传递。
预测代码:
1 | forecast lead=10 id=time interval=year out=out; |
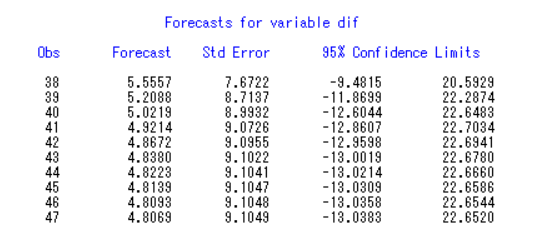
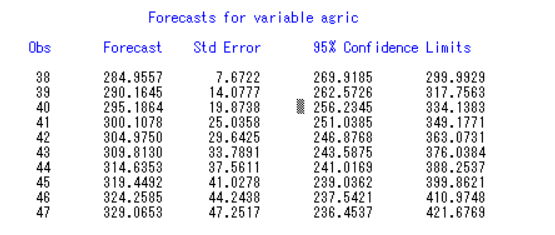
这里预测的是一阶差分之后的数据量,我们如果想要看本来的数据,可以修改代码来使预测的数据导入原始序列:
一步(一阶)差分:xx(1)
二部差分:xx(2)
二阶差分:xx(1,1)
一阶12步差分:xx(1,12)
1 | proc arima; |
6.疏系数模型
对1917年-1975年美国23岁妇女每万人生育率序列建模
初始SAS代码:
1 | goptions vsize=7cm hsize=10cm; |

发现初始序列并不稳定,我们做一阶差分。
1 | identify var=x(1); |

自相关系数趋向于0,说明一阶差分后稳定了
接着我们需要确定模型
1 | identify var=x(1) nlag=22 minic p=(0:5) q=(0:5); |
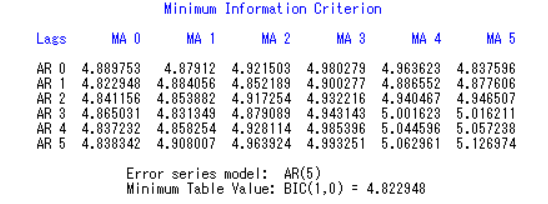
这里最好选择p=1,但是我们为了研究疏系数模型,我们取次小的p=4来研究
参数分析:
1 | estimate p=4; |
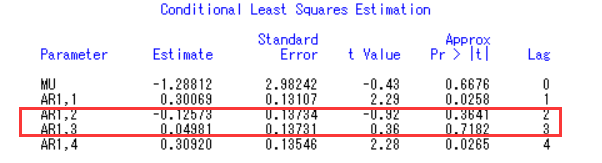
常数,AR2,AR3接受了原假设,需要去掉,修改代码:
1 | estimate p=(1 4) noint; |

残差检验:所有的都要大于0.05

接着就可以做预测了:
1 | forecast lead=5 id=year out=out; |
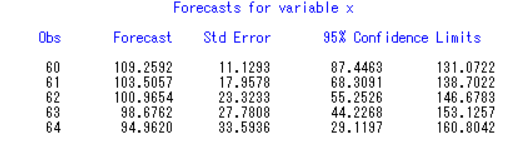
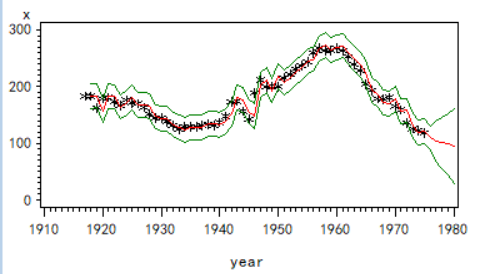
7.简单季节模型
拟合1962——1991年德国工人季度失业率序列
初始SAS代码:(首先这个肯定不平稳,我们直接跳到一阶差分)
1 | goptions vsize=7cm hsize=10cm; |
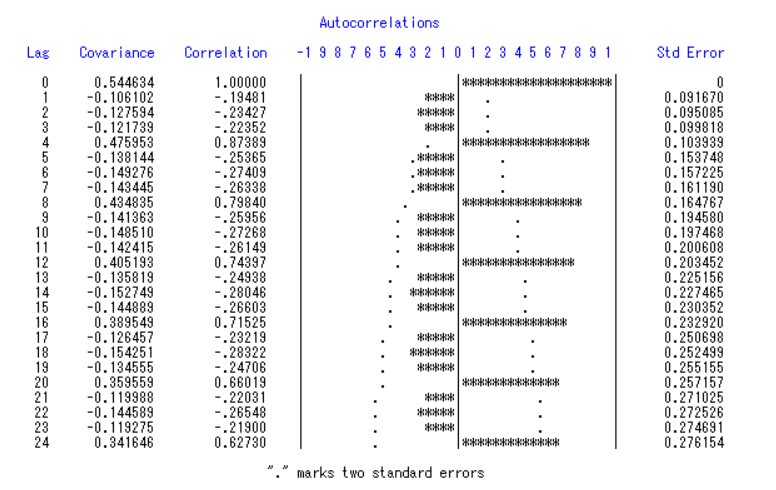
可以看出,一阶差分之后周期性还是很明显的。我们可以发现周期大概是四,因此我们在此基础上再来四步差分。修改SAS代码:
1 | goptions vsize=7cm hsize=10cm; |
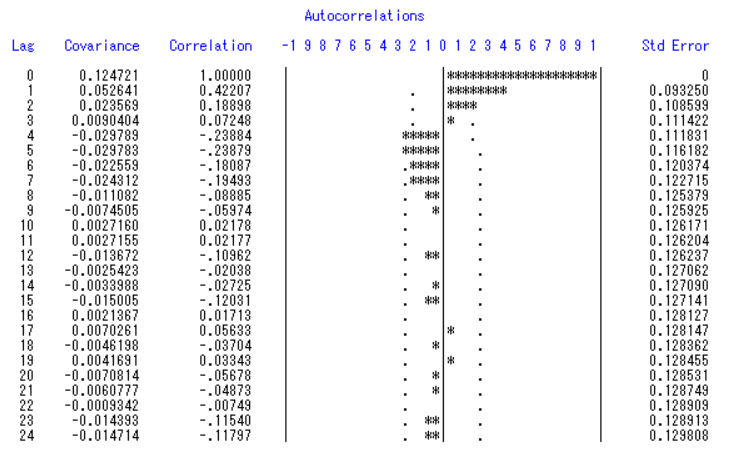
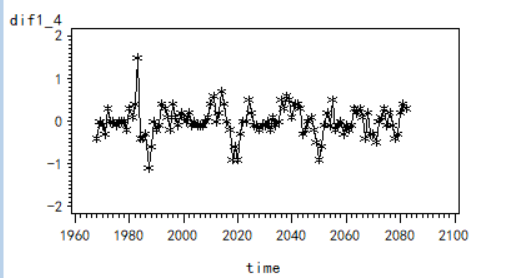
综合自相关系数表和时序图可以看出此时时间序列平稳了,接着我们还需要看白噪声检验:

都小于0.05,说明一阶四步差分之后的序列可以做时间序列的模型。
接着我们要预测模型(此步上面都有,不再赘述),试出来是p=4,再进行参数检验,最后p=(1 4) noint,定阶模型为ARIMA((1,4),(1,4),0)。
最后看残差的白噪声检验,通过了就可以做预测了,附上SAS代码
1 | goptions vsize=7cm hsize=10cm; |

参数估计: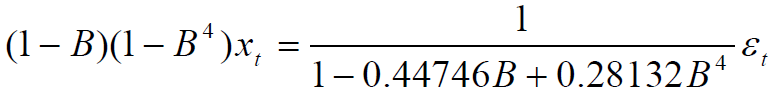
8.乘积季节模型
拟合1948——1981年美国女性月度失业率序列
初始SAS代码:(原始序列不稳定确定过程略过,直接先进行一阶差分)
1 | data a; |

可以看出周期差不多是12,因此在进行12步差分
1 | identify var=x(1,12); |
先进行差分平稳:
得到的自相关系数图:
偏自相关系数图:
从上面这两张图差不多可以看出进行了差分后并没有完全平稳,接着我们制定模型,中间的参数检验逐步把p(AR)和q(MA)不符合的去掉,最后得到p=0,q=1 noint;
再看残差白噪声检验:
好几个小于0.05,说明残差直接有信息传递,这时候我们发现简单季节模型并不适用,我们考虑使用乘积季节模型

最终调试出来的代码:
1 | estimate p=1 q=(1)(12) noint; |

参数检验通过
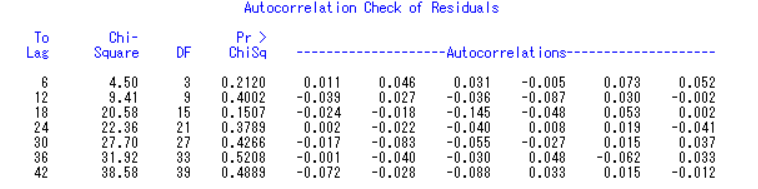
残差白噪声检验也通过了。
模型定阶: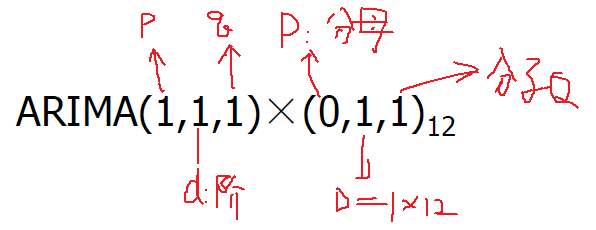

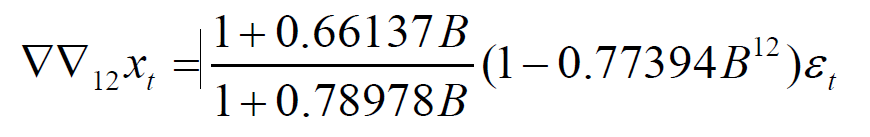
作业
1.平稳时间序列
现有201个连续的生产纪录,如下
81.9 89.4 79.0 81.4 84.8 85.9 88.0 80.3 82.6
83.5 80.2 85.2 87.2 83.5 84.3 82.9 84.7 82.9
81.5 83.4 87.7 81.8 79.6 85.8 77.9 89.7 85.4
86.3 80.7 83.8 90.5 84.5 82.4 86.7 83.0 81.8
89.3 79.3 82.7 88.0 79.6 87.8 83.6 79.5 83.3
88.4 86.6 84.6 79.7 86.0 84.2 83.0 84.8 83.6
81.8 85.9 88.2 83.5 87.2 83.7 87.3 83.0 90.5
80.7 83.1 86.5 90.0 77.5 84.7 84.6 87.2 80.5
86.1 82.6 85.4 84.7 82.8 81.9 83.6 86.8 84.0
84.2 82.8 83.0 82.0 84.7 84.4 88.9 82.4 83.0
85.0 82.2 81.6 86.2 85.4 82.1 81.4 85.0 85.8
84.2 83.5 86.5 85.0 80.4 85.7 86.7 86.7 82.3
86.4 82.5 82.0 79.5 86.7 80.5 91.7 81.6 83.9
85.6 84.8 78.4 89.9 85.0 86.2 83.0 85.4 84.4
84.5 86.2 85.6 83.2 85.7 83.5 80.1 82.2 88.6
82.0 85.0 85.2 85.3 84.3 82.3 89.7 84.8 83.1
80.6 87.4 86.8 83.5 86.2 84.1 82.3 84.8 86.6
83.5 78.1 88.8 81.9 83.3 80.0 87.2 83.3 86.6
79.5 84.1 82.2 90.8 86.5 79.7 81.0 87.2 81.6
84.4 84.4 82.2 88.9 80.9 85.1 87.1 84.0 76.5
82.7 85.1 83.3 90.4 81.0 80.3 79.8 89.0 83.7
80.9 87.3 81.1 85.6 86.6 80.0 86.6 83.3 83.1
82.3 86.7 80.2
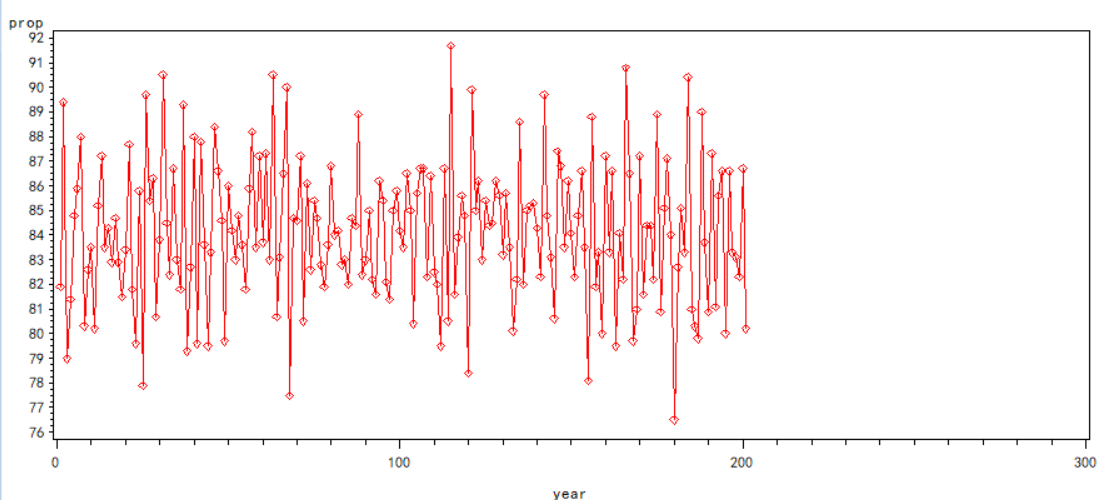
(1)判断该序列的平稳性
(2)如果该序列平稳且非白噪声。选择适当模型拟合该序列的发展
(3)写出拟合模型,预测该序列后5年的95%预测的置信区间。
1、首先我们进行平稳性和非白噪声检验并初步确立模型,编写对应的SAS代码
1 | data ex; |
时序图:
已知时间序列为平稳序列的条件如下: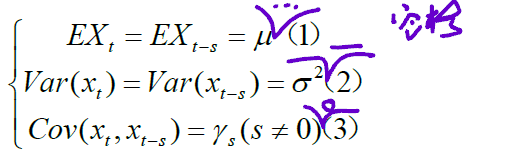
观察时间序列图可知,序列基本上在一条水平线上下波动,可知该组数据的均值基本不变,为固定值,满足条件(1);序列的波动性较小可判断其方差存在且可能为常数,满足条件(2)。因此,从该时间序列图我们猜测数据可能为平稳序列。接着,通过自相关图中自相关系数的变化进一步判断。
自相关系数图:

由自相关系数图可知,当跨越步数p为0 时,自相关系数为1,此时自相关系数最大。随着跨越步数的逐渐增大,自相关系数的绝对值越小。跨越步数越大,自相关系数的绝对值越接近于0,具有拖尾的性质。可见,该序列是平稳序列。
2、在序列为平稳序列的基础上,我们对该序列进行白噪声检验
白噪声检验表:
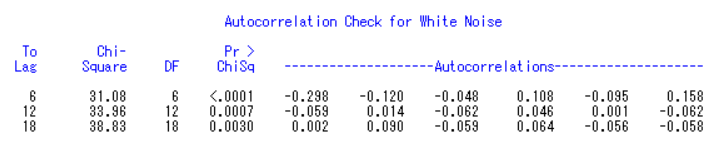

说明存在序列相关性,不满足纯随机序列 ,可以用时间序列拟合
3、调用SAS,对生产量进行minic 识别,指定p 和q 的最小值都为0,最大值都为6,得到BIC 信息指数如下:
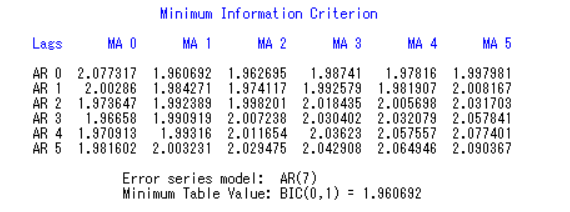
暂时确定p=0,q=1,该序列为MA模型。
4、使用条件最小二乘估计进行参数估计,参数估计值如下表:
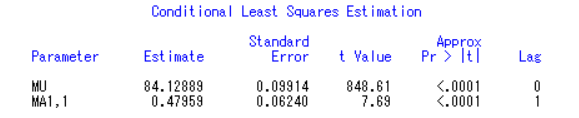
其中,第一列为估计的参数名称,第二列是参数的估计值,第三列是参数估计值的标准误,第四列是参数显著性检验的 t 值,第五列为显著性检验的概率值 P。
可以发现 MU 和 MA1 ,1 的 P 值均小于 0.05 ,通过了 t 检验,得出移动平均系数多项式: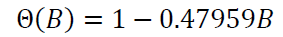
根据移动平均模型的定义:𝑥𝑡=Θ(𝐵)𝜀𝑡,又可以推出 时间序列模型:𝑥𝑡=84.12889+(1−0.47959𝐵)𝜀𝑡
5、接着对模型进行显著性检验,即对残差序列进行白噪声检验,得到的残差序列检验表如下:
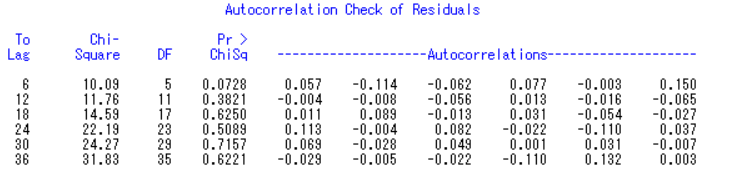
可以看出,对 36 期的残差序列进行显著性检验后,其 P 值均大于 0.05 ,接受了原假设,服从白噪声序列,说明拟合模型能够提取观察值序列中几乎所有的样本相关信能够提取观察值序列中几乎所有的样本相关信息息。。
6、预测该序列后5 年的 95% 预测的置信区间 ,结果如表:

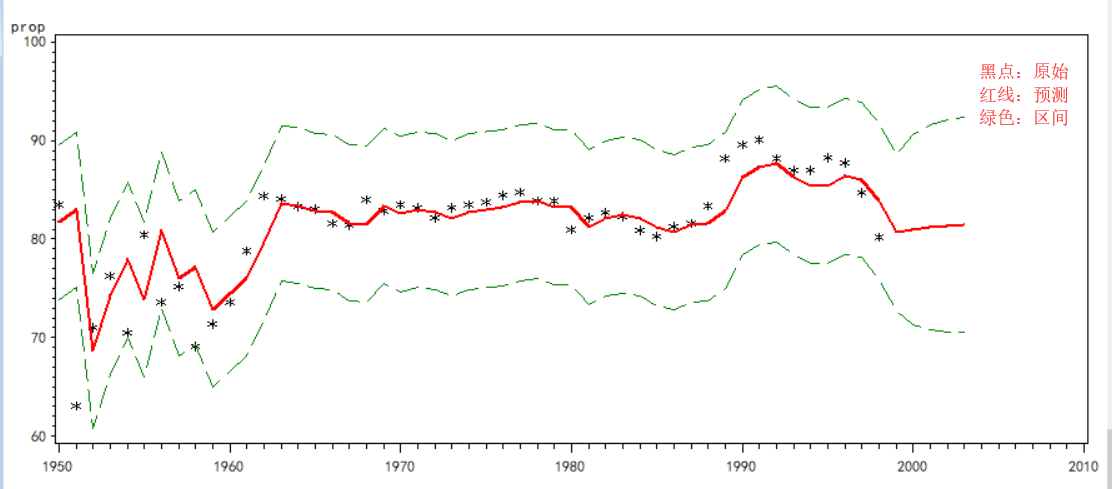
通过预测数据绘制除原数据与预测数据的拟合曲线如下图:
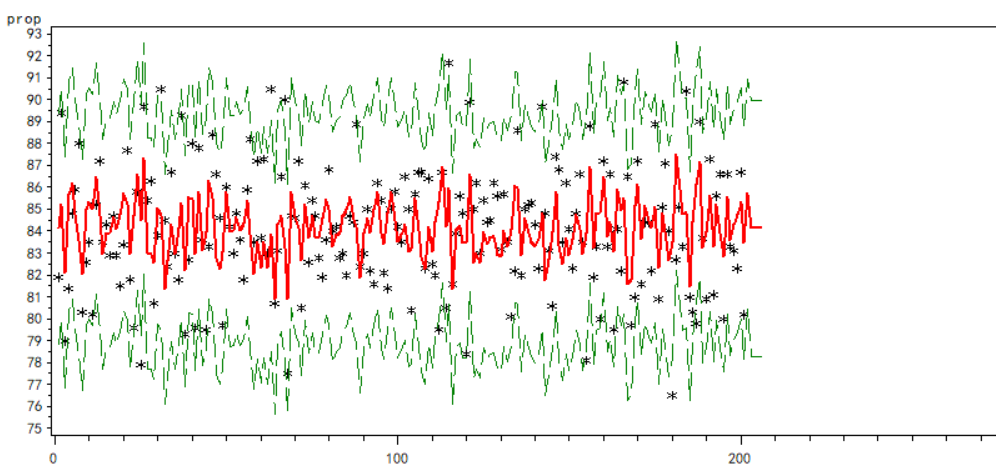
由预测曲线图可以看出,大部分原数据在预测曲线上,预测趋势与原数据走势基本相似。
不在预测曲线上的数据几乎全部落在95%的预测曲线内,预测效果较好。
2.非平稳时间序列
习题:某城市连续14年的月度婴儿出生率数据如下
26.663 23.598 26.931 24.740 25.806 24.364 24.477 23.901
23.175 23.227 21.672 21.870 21.439 21.089 23.709 21.669
21.752 20.761 23.479 23.824 23.105 23.110 21.759 22.073
21.937 20.035 23.590 21.672 22.222 22.123 23.950 23.504
22.238 23.142 21.059 21.573 21.548 20.000 22.424 20.615
21.761 22.874 24.104 23.748 23.262 22.907 21.519 22.025
22.604 20.894 24.677 23.673 25.320 23.583 24.671 24.454
24.122 24.252 22.084 22.991 23.287 23.049 25.076 24.037
24.430 24.667 26.451 25.618 25.014 25.110 22.964 23.981
23.798 22.270 24.775 22.646 23.988 24.737 26.276 25.816
25.210 25.199 23.162 24.707 24.364 22.644 25.565 24.062
25.431 24.635 27.009 26.606 26.268 26.462 25.246 25.180
24.657 23.304 26.982 26.199 27.210 26.122 26.706 26.878
26.152 26.379 24.712 25.688 24.990 24.239 26.721 23.475
24.767 26.219 28.361 28.599 27.914 27.784 25.693 26.881
26.217 24.218 27.914 26.975 28.527 27.139 28.982 28.169
28.056 29.136 26.291 26.987 26.589 24.848 27.543 26.896
28.878 27.390 28.065 28.141 29.048 28.484 26.634 27.735
27.132 24.924 28.963 26.589 27.931 28.009 29.229 28.759
28.405 27.945 25.912 26.619 26.076 25.286 27.660 25.951
26.398 25.565 28.865 30.000 29.261 29.012 26.992 27.897
(1)选择适当的模型拟合该序列的发展
(2)使用该拟合模型预测下一年度该城市月度婴儿出生率
1、首先我们先绘制原本数据的时间序列图,初始SAS代码如下:
1 | goptions vsize=7cm hsize=10cm; |
时间序列图:
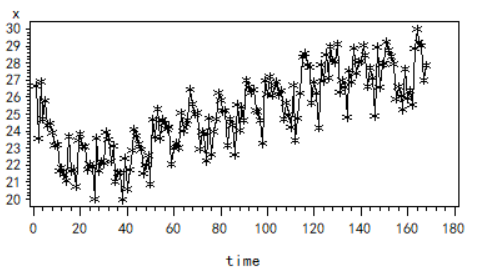
自相关系数:
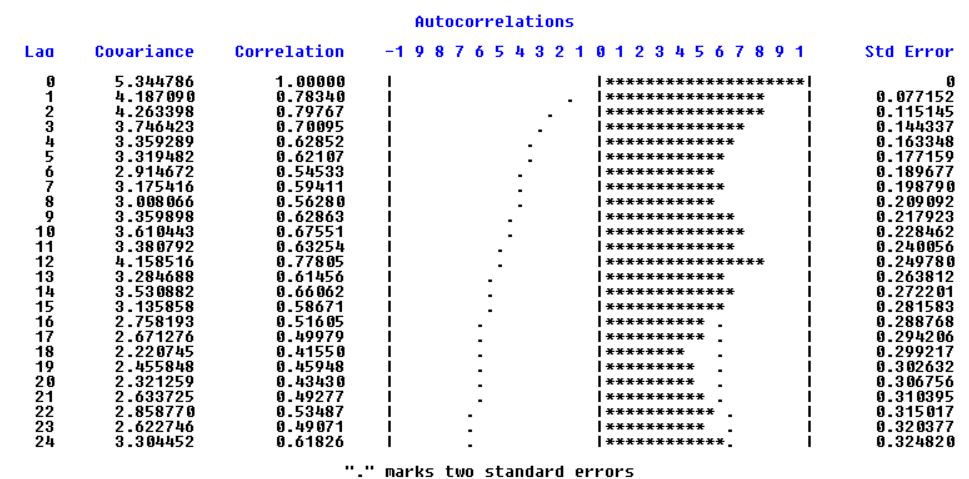
可以看出序列非平稳,接着我们对序列进行差分处理,希望消除其周期性和趋势性。
2、一阶差分
1 | goptions vsize=7cm hsize=10cm; |
时间序列图: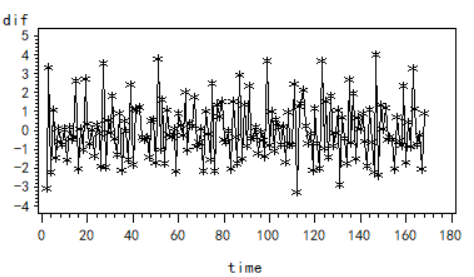

可以看出数据仍存在明显的周期性。估计其周期大致为12,接着用逐步差分消除周期性。
3、十二步差分
1 | goptions vsize=7cm hsize=10cm; |
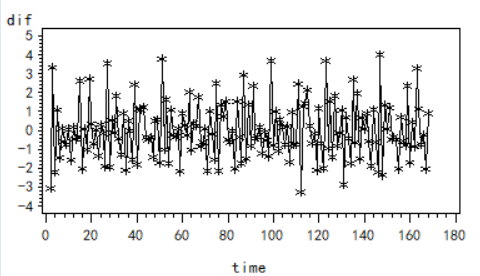
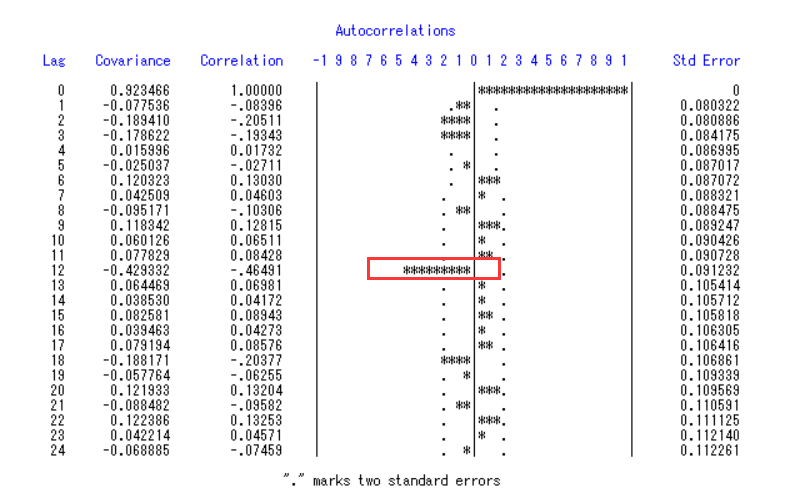
由该自相关系数图同样可以观察到周期性减弱了许多,但仍然可能残余部分周期信息未被提取完全。我们先认为序列为平稳序列,对其进行白噪声检验。
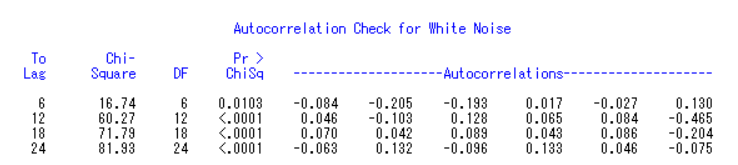
4、因为数据序列为平稳序列且为非白噪声序列,所以数据间存在一定的相关性,我们决定先尝试使用ARIMA 模型中的简单季节模型进行预测
1 | identify var=x(1,12) minic p=(0:5) q=(0:5); |
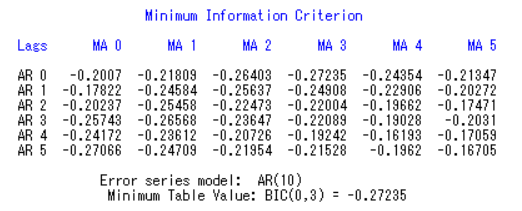
由上表可知,当p=0,q=3 时,模型最优。模型为ARMA(0,3)。
5、接下来进行参数估计:
1 | estimate p=0 q=3; |
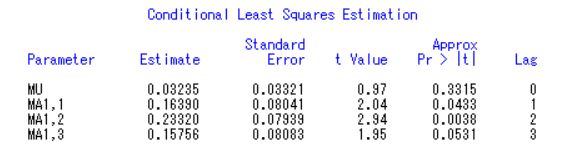
由上参数检验表可知常数 、q=3 的P 值>0.05,参数不通过检验。因此删除上述未通过检验的参数再进行检验
1 | estimate p=0 q=2 noint; |

参数全部通过检验,接着对模型进行显著性检验,即对残差进行白噪声检验
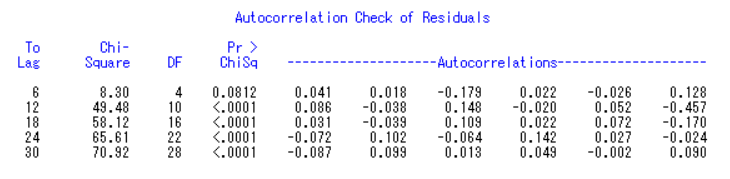
很多都小于0.05,说明残差之间有信息传递。此模型并不适用,因此,我们选择使用ARIMA 模型中的乘积季节模型进行预测。
6、这里我们使得P、Q=0……5来一个个看,发现D(步数)等于12时均不能达到,我们这时候可以把D=2,即看成24步,再次来算就容易多了
最终确定为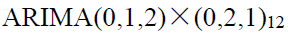
参数检验表:

残差序列检验表:


该模型的方程为: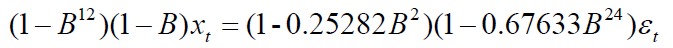
7、得到模型我们就可以做预测了
1 | goptions vsize=7cm hsize=10cm; |
预测结果如下表所示:
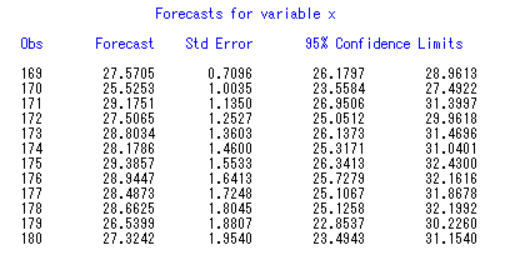
通过预测数据绘制除原数据与预测数据的拟合曲线如下图:
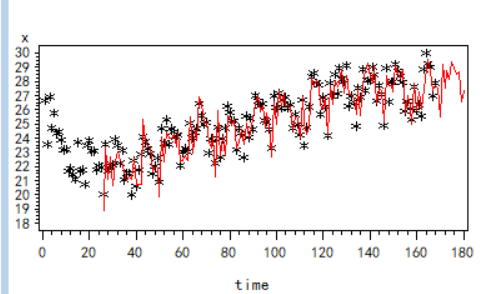
由预测曲线图可以看出,大部分原数据在预测曲线上,预测趋势与原数据走势基本相似。
不在预测曲线上的数据几乎全部落在95%的预测曲线内,预测效果较好。
结语
鉴于本人最近嘴唇有了溃疡,决定鸽几天数学建模,看看品优购舒服一下(‾◡◝)

