
EverydayOneCat
ʚฅ^•ﻌ•^ฅɞ 🪐 🌈 
知识点
1.笔记



2.正态性检验
Pearson相关系数的适用条件:
(1)两变量的总体服从正态分布
(2)样本容量较大,都是连续型变量
(3)变量必须是成对数据
SAS代码:
1 | data ex;input x@@; |
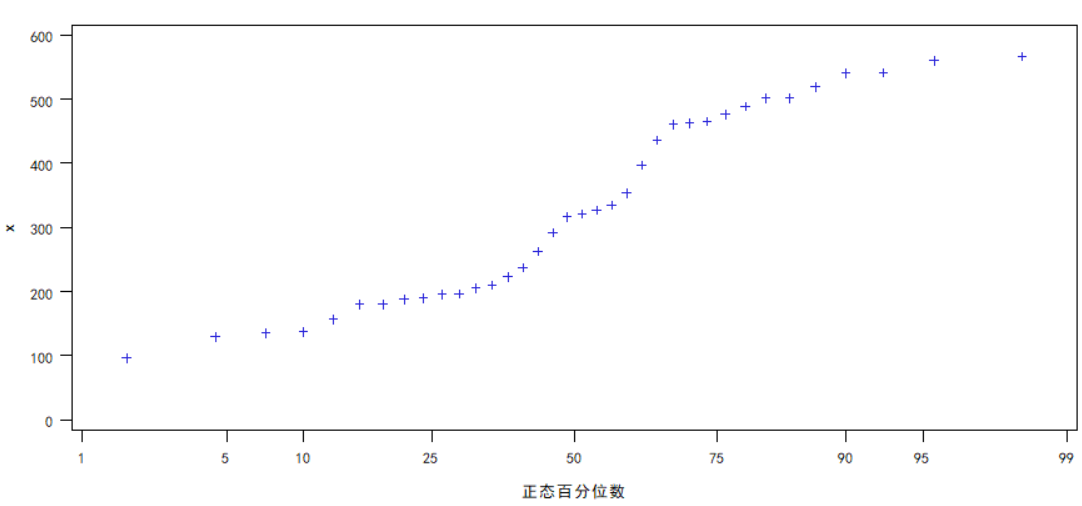
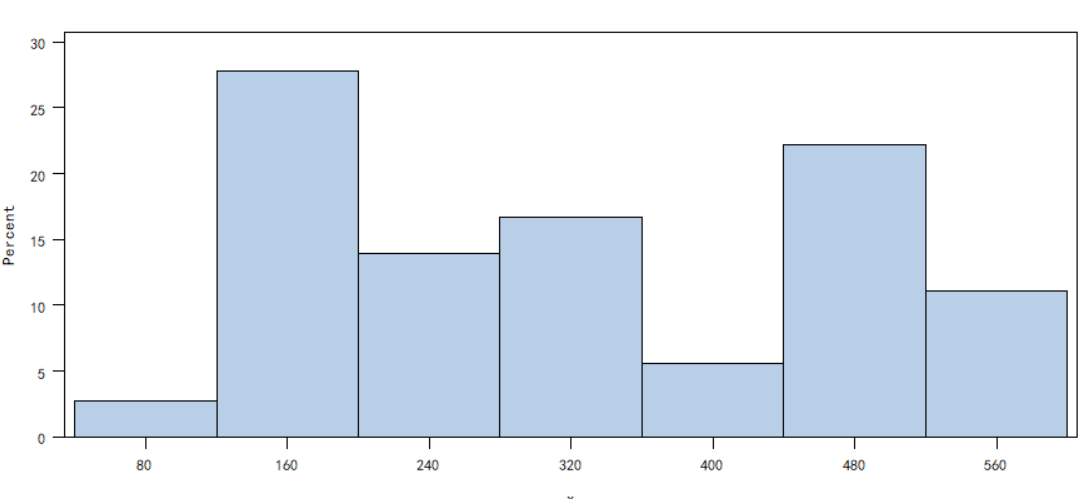
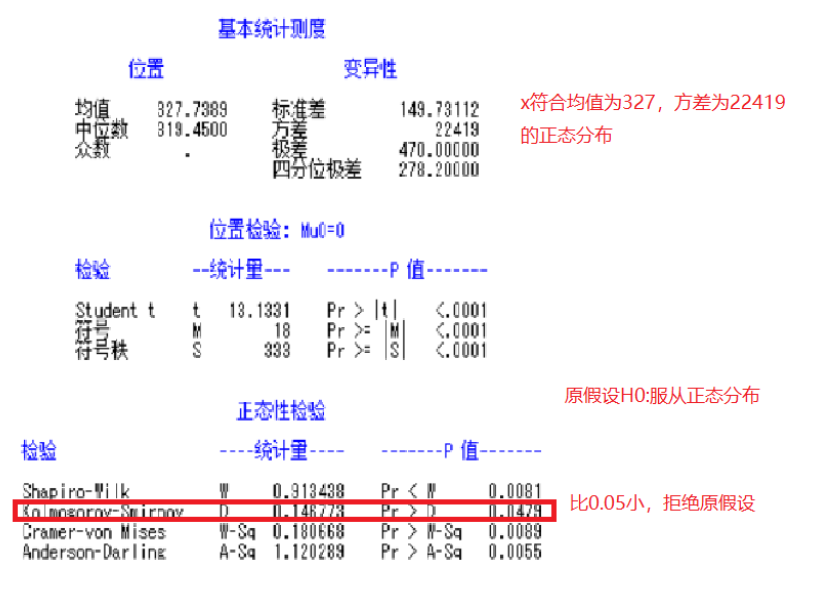
3.偏相关系数
SAS代码:
1 | data ex;input y k s l t@@; |


4.典型相关系数
例蔬菜产出水平主要体现在蔬菜总产量(Y1)、人均蔬菜占有量(Y2)、蔬菜总产增长速度(Y3)三个方面,并称作因变量组(简称“产出组”)。问题:因变量组与自变量X1(市场经济综合因素)、X2(劳动力动力因素) 、X3(气候因素)(简称“影响组”)的关系如何?
SAS代码:
1 | data ex;input y1-y3 x1-x3 @@; |

整理得到蔬菜产出水平与影响因素的三个自变量的典型相关系数及特征值
| 序号 | 典型相关系数 | 标准误差 | 特征值 | 特征值方差比率 | 累计方差比率 |
|---|---|---|---|---|---|
| 1 | 0.969221 | 0.017497 | 15.4987 | 0.8699 | 0.8699 |
| 2 | 0.769604 | 0.117696 | 1.4527 | 0.0815 | 0.9514 |
| 3 | 0.681054 | 0.154778 | 0.8651 | 0.0486 | 1.0000 |
结果表明:前两个典型相关系数较高,表明相应典型变量之间密切相关。
| 序号 | F计算值 | 自由度 | F检验的显著性概率 |
|---|---|---|---|
| 1 | 9.38 | 9 | <.0001 |
| 2 | 4.56 | 4 | 0.0120 |
| 3 | 7.79 | 1 | 0.1765 |
结果表明:只有前两对典型变量通过了统计量检验,表明相应典型变量之间相关关系显著,能够用三个自变量影响变量来解释产出变量。
典型相关模型结果如下:

| 序号 | 典型相关模型 |
|---|---|
| 1 | v1=6.1649 Y1-5.2034 Y2+0.0696 Y3 w1=0.9953X1-0.0054 X2-0.0948X3 |
| 2 | v2=14.7443Y1-15.0750Y2+0.9105Y3 w2= - 0.0132 X1+0.9591 X2-0.2804 X3 |
结果分析:自变量X1即市场经济综合因素对中国蔬菜产出水平起根本性作用。市场经济综合因素与蔬菜总产出的关系体现在第一对典型变量v1和w1中,v1是中国蔬菜产出水平各指标的线性组合,其中,蔬菜总产出(Y1)的载荷为6.164,是各产出水平指标中最大的。w1是影响因素指标的线性组合,其中市场经济综合因素(X1)的载荷为0.9953,远远超过w1内其它指标的数值。考虑到第一对典型相关变量的相关系数几乎接近于1,可以认为,市场经济综合因素对蔬菜总产出水平起根本性作用。自变量X2即劳动力动力因素是决定人均蔬菜占有量的关键因素。
第二对典型变量中.人均蔬菜占有量(Y2)在典型变量v2中的载荷为-15.075,是各产出水平指标中最大的,而自变量X2则在典型变量w2中载荷最大,为0.9591。这一对典型相关变量的相关系数非常之高,表明自变量X2对劳动力动力因素起关键作用。
在第二对典型变量中,Y1与劳动力动力因素关系也非常密切。因为在第二对典型变量中,Y1在v2中的载荷14.7443,与Y2差距并不明显。由此可以分析的处,用Y1作为产出水平的代表,X1、X2、X3作为影响变量建立因果拟合模型效果是最好的。
5.主成分分析
起源一:寻找重要因素
在若干个相互关联、关系复杂的一组变量中,想找到最为关键的因素,是一个重要的科学问题。在寻找关键因素过程中,还需要找到能够反映该组变量这个群体的主要特征。
起源二:综合评价要求评价指标线性无关
在做综合评价的时候,往往需要将多个评价指标综合成一个指标。综合时除了需要将指标同向,还需要评价指标间线性无关或者不相关。
但是很多实际问题中,指标之间是高度关联的,在这种情况下如何进行综合评价?
起源三:建立回归模型的需要
在做多元线性回归模型时,理想状态下是需要自变量线性无关的。
而且,模型拟合时,还需要样本点的个数n与自变量的个数p满足一个不等式:n>3(k+1)
一旦两个条件有一个满足,回归模型的效果将受影响
例:以下是收集整理了的1990-2002年13年间影响中国蔬菜产量的若干因素数据,请你对这些影响因素作主成分分析,并分析结果。
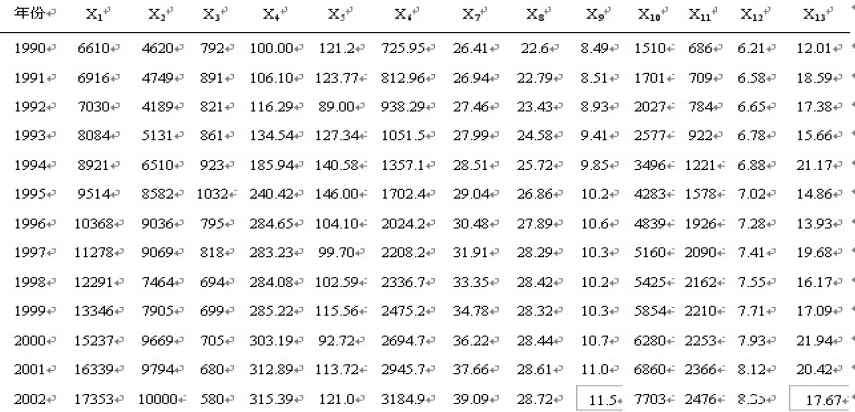
SAS主成分软件包:princomp
编写SAS代码:
1 | data ex; |
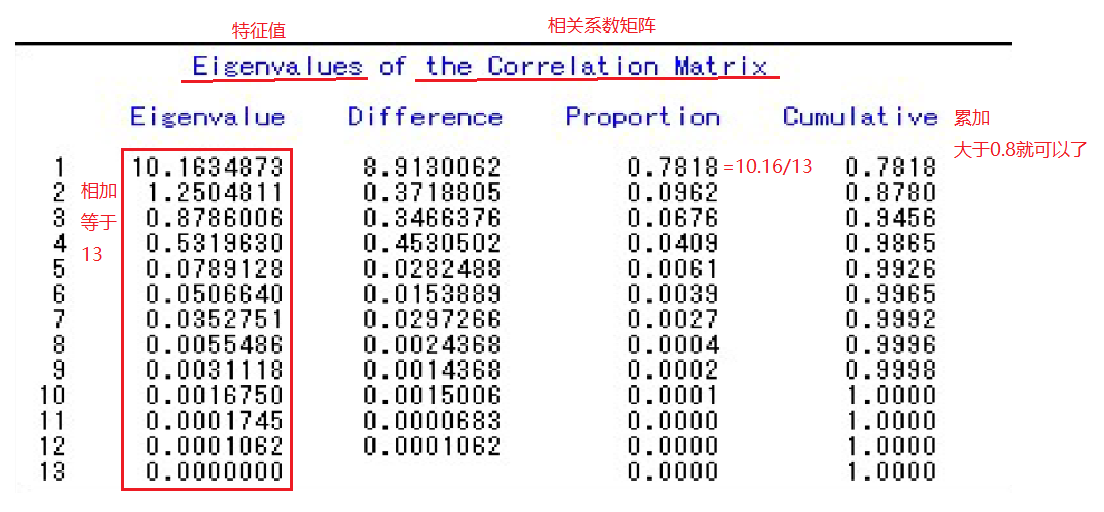
从程序结果可以看出,第一、第二、第三主成分累计解释方差的比率已经超过了94%,所以只需要求λ1、λ2、λ3所对应的正交化特征向量αi(i=1,2,3)
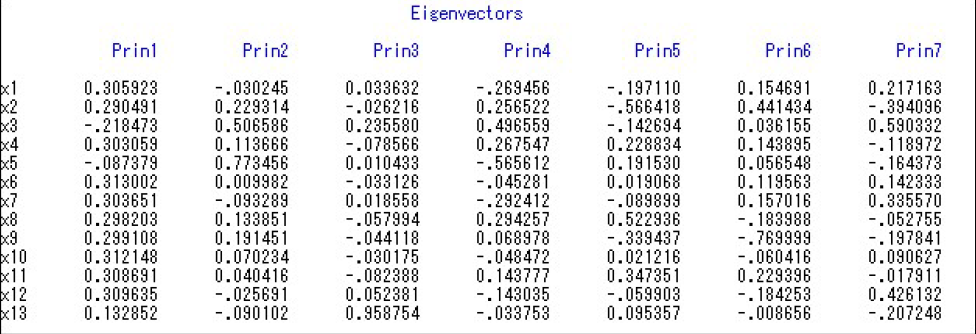
根据这个就可以写出Z的表达式:
Z1=a1X,Z2=a2 X……其中X=(x1,x2,……,x13)
α1=(0.31,0.29,-0.22,0.30,-0.09,0.31,0.30,0.30,0.30,0.31,0.31,0.31,0.13),
α2=(-0.03,0.23,0.51,0.11,0.77,0.01,-0.09,0.13,0.19,0.07,0.04,-0.03,-0.09),
α3=(0.03,-0.03,0.24,-0.08,0.01,-0.03,0.02,-0.06,-0.04,-0.03,-0.08,0.05,0.96)
结果分析:
α1第一主成分在整体最为重要,接着我们看这些因素在第一主成分中的绝对值哪个最大,哪个就相当于对总体为重要。
第一主成分与蔬菜种植面积、每公顷物质费用、蔬菜零售物价指数、市场化程度、城市化水平1、城市化水平2、交通、城镇居民可支配收入、农村居民纯收入、农民文化素质等密切相关,表示的是市场经济综合因素,着重反映的是市场经济的成熟程度与国家现代化水平;
第二主成分与每公顷劳动投入、成本纯收益率等密切相关,表示的是劳动者动力因素;
第三主成分与气候条件密切相关,显然表示的是气候因素。
主成分得分:相当于把Z1,Z2……算出来
6.因子分析
因子分析的基本思想是根据相关性大小把原始变量分组,使得同组内的变量之间相关性较高,而不同组的变量间的相关性则较低。每组变量代表一个基本结构,并用一个不可观测的综合变量表示,这个基本结构就称为公共因子。对于所研究的某一具体问题,原始变量就可以分解成两部分之和的形式,一部分是少数几个不可测的所谓公共因子的线性函数,另一部分是与公共因子无关的特殊因子。
因子分析一般步骤:
1)类似主成分分析,计算 及s , k, j =1,2,..m,建立基本方程组;
2)用主成分分析法确定因子载荷阵A;
3)方差极大正交旋转,对变量系数极值化(尽量趋于0或1);
4)得到因子得分函数,计算样本因子得分。
例:已知12个地区的5个经济指标:人口总数、学校总数、就业人口、服务业总数、房子个数。依据已知的5个经济指标,对12个地区的综合经济实力进行分析。
分析:由于指标个数较多,不便于分析排序。因此,考虑先做因子分析找出指标的共同因子,再计算因子得分,通过分析因子得分来评价该地区的经济指标。
1 | data ex; |
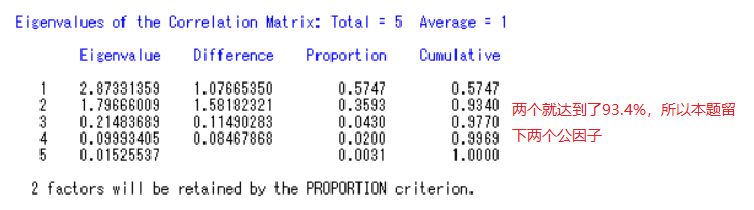
结果表明,5个因子对应的特征值,特征值表示因子贡献率。通常确定因子个数时,要求因子累计贡献率大于80%。结果表明应选取2个因子,记为F1,F2 贡献率分别为57.47%、35.93%。
确定因子载荷阵系数,得到初始的特征向量:

由于对应实际问题,公共因子的实际意义不好解释。因此考虑将指标的系数极值化,即让系数趋于1或0,趋于1说明公共因子与该指标密
切相关,否则趋于0时说明相关程度很低。由此,要做因子旋转实现系数的极值化。
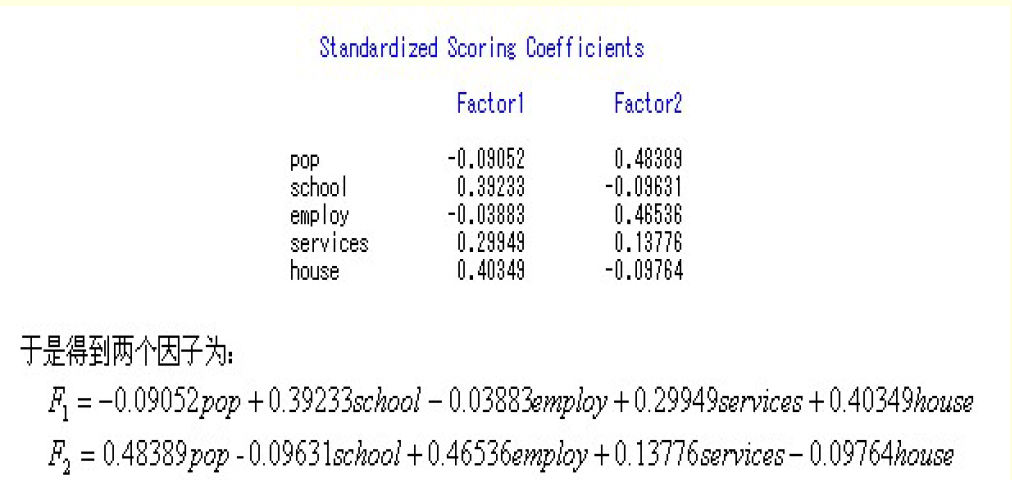
第一公因子和学校、房子、服务密切相关,可推断其代表福利水平,第二个同理推出代表经济水平。
因子得分:
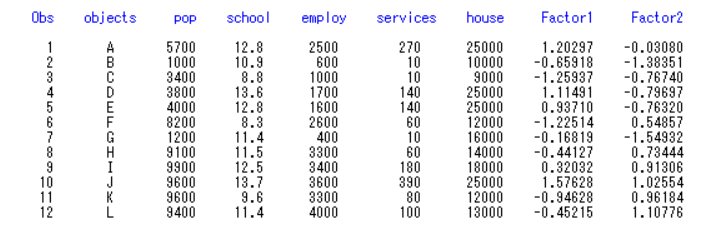
以上为12个样本的5个指标值,以及2个公共指标的得分,因子F1中J地区的得分最高,说明该地区的服务教育服务设施较好。因子F2中L地区的得分最高,说明该地区的就业情况较好。
因子分析与主成分分析的区别与联系:
因子分析、主成分分析都是重要的降维方法(数据简化技术),因子分析可以看作是主成分分析的推广和发展。
主成分分析不能作为一个模型来描述,它只能作为一般的变量变换,主成分是可观测的原始变量的线性组合;因子分析需要构造因子模型,公共因子是潜在的不可观测的变量,一般不能表示为原始变量的线性组合。
因子分析是用潜在的不可观测的变量和随机影响变量的线性组合来表示原始变量,即通过这样的分解来分析原始变量的协方差结构(相依关系)。
7.聚类分析
进行聚类分析时,由于对类与类之间的距离的定义和理解不同,并类的过程中又会产生不同的聚类方法。常用的系统聚类方法有8种:最短距离法;最长距离法;中间距离法;重心法;类平均法;可变类平均法;可变法;离差平方和法。
例:从21个工厂中抽出同类产品,每个产品测两个指标,欲将各厂的质量情况进行分类。
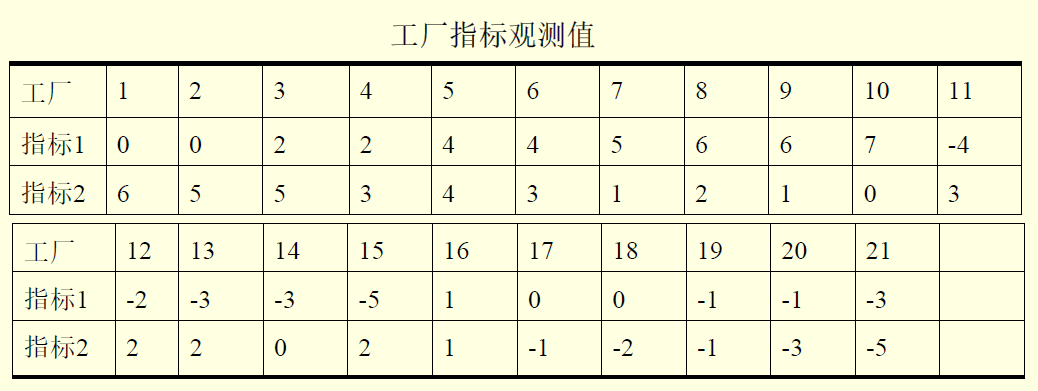
SAS代码:
1 | data ex; |
ccc表示要计算半偏R2,当把数据从G+1类合并为G类时,半偏R2统计量说明了本次合并信息的损失程度,统计量大表明损失程度大。R2统计量反映类内离差平方和的大小,统计量大表明类内离差平方和小。ccc统计量的值大说明聚类的效果好。

综合各方面的结果,因此分4类最为合适。
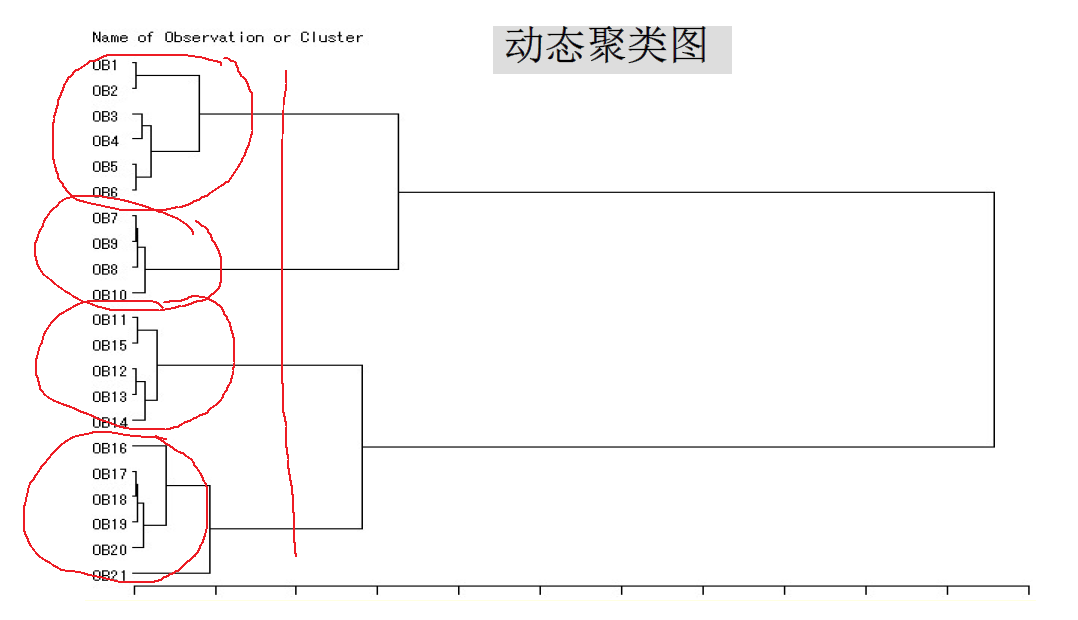
综合以上分析,可以得到结果,将工厂分为4类,分别为
第1类:f1,f2,f3,f4,f5,f6;
第2类:f7,f8,f9,f10
第3类:f11,f12,f13,f14,f15;
第4类:f16,f17,f18,f19,f20,f21。
8.判别分析
判别分析是一种在一些已知研究对象用某种方法已经分成若干类的情况下,确定新的样品的观测数据属于哪一类的统计分析方法。
例题:人文发展指数是联合国开发计划署于1990年5月发表的一份<<人类发展报告>>中公布的数据如下,试通过已知的样品建立判别函数,误判率是多少?并判断待判的归类.
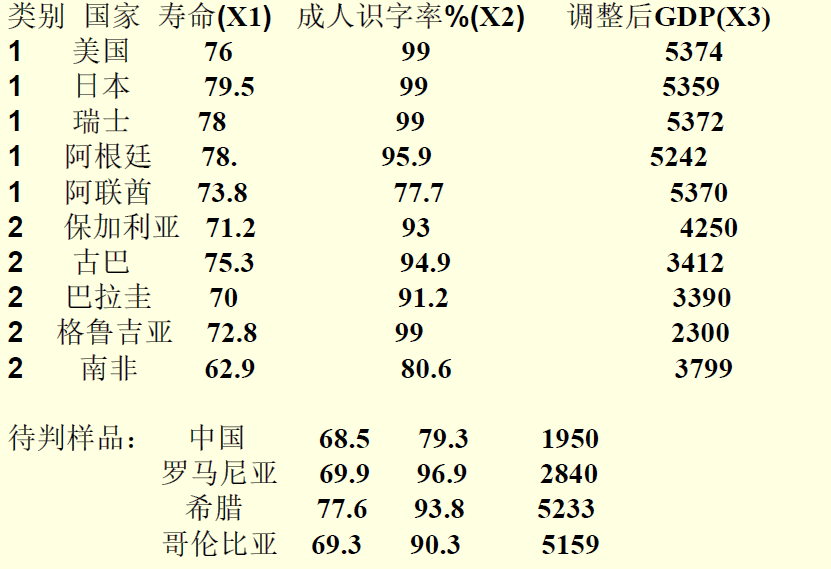
判别分析软件包:discrim
SAS代码:
1 | data ex;input g x1-x3 @@; |
Proc Discrim后的常用选择项有:
(1)Data=数据集名,指定输入数据集名,若缺省则指定最新建立的数据集。
(2)Testdata=数据集名,指定待作出判别的数据集名,其中的变量名须上Data数据集中的变量名一致。
(3)Testout=数据集名,指定输出数据集,输出Testdata数据集中所有观测值以及每个观测值的后验概率和判别后的类别。
(4)List,指定打印每个观测值的回代结果。
(5)Anova,指定输出各类均值检验的一元统计量。
(6)Manova,指定输出各类均值检验的多元统计量。
(7)Simple,指定打印总体和组内的简单统计量。
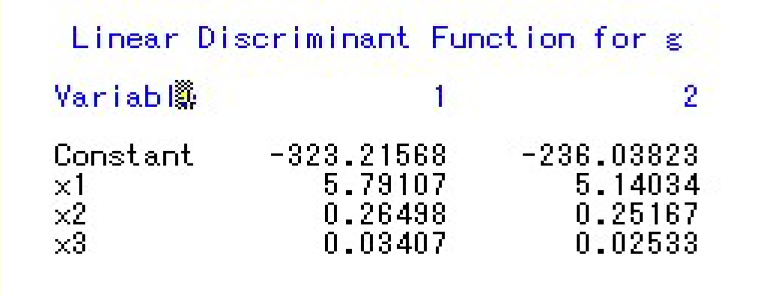
因此Bayes判别函数为
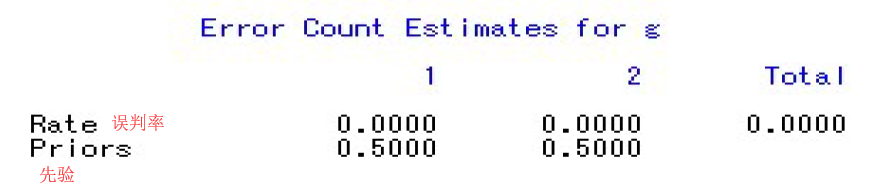
从上面运行结果得知,两类的误判率均为0

从上面运行结果得知,两类的误判率均为0因而得知中国与罗马尼亚归入第二类,希腊与哥伦比亚归入第一类。
9.逐步判别分析
逐步判别法其基本思路类似于逐步回归分析,按照变量是否重要逐步引入变量,每引入一个“最重要”的变量进入判别式,同时要考虑较早引入的变量是否由于其后的新变量的引入使之丧失了重要性变得不再显著了(例如其作用被后引入地某几个变量的组合所代替),应及时从判别式中把它剔除,直到判别式中没有不重要的变量需要剔除,剩下来的变量也没有重要的变量可引入判别式时,逐步筛选结束。也就是说每步引入或剔除变量,都作相应的统计检验,使最后的判别函数仅保留“重要”的变量。
逐步回归选取变量SAS代码:
1 | data ex; |
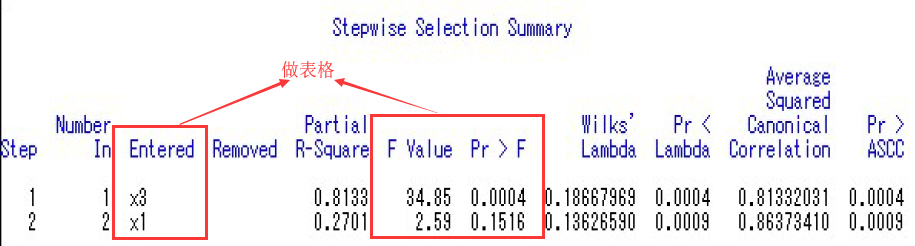
结果显示:x3对应的F值为34.85,Pr>F的概率为0.0004小于0.3,x1对应的F值为2.59,Pr>F的概率为0.1516小于0.3,所以我们就写入x1,x3进入判别函数中。
增加SAS代码:
1 | proc discrim data=ex testdata=ex1 /*待判别集合*/ |
得到判别函数:
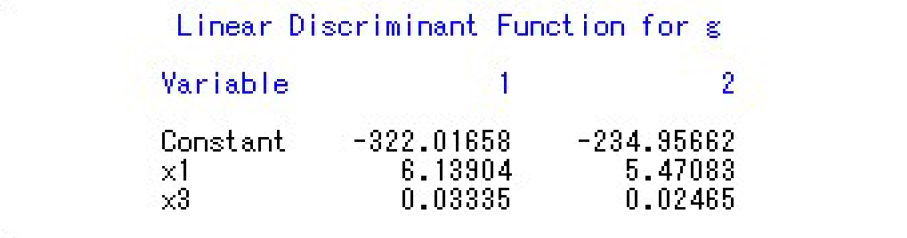
根据此可写出具体的判别函数,同上。
误判概率:
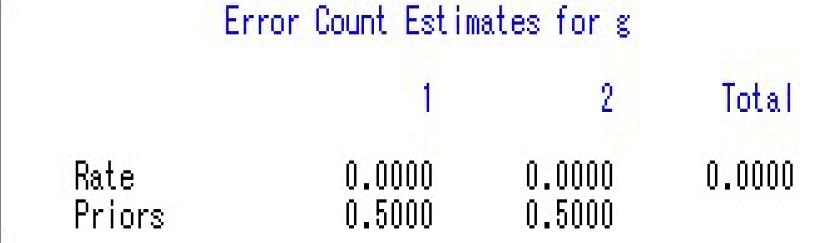
两类的误判率均为0,说明判别能力很强,于是可以利用已经得到的判别函数去判别新样本。
待判样本分类结果:

结果表明,中国与罗马尼亚归入第二类,希腊与哥伦比亚归入第一类。
由以上两个例子可知,逐步判别法所得到的结果可看出来,尽管这里没有利用变量X2(成人识字率),但是最终的判别结果与利用全部变量所得得判别结果完全一致,这说明了三个变量在判别式中所起到的作用不同。由此可见,在解决现实问题中应结合两种方法使得更加科学的使用已知数据得到更加合理的结论。
作业
1.相关系数
本题选取了1990-2006年影响我国就业的13个指标的时间序列数据,见表1以及表1(续)。
城镇就业人数与各影响因素数据一览表
| 年 份 | 城镇就业人数 | GDP总量1 | 城镇总投资2 | 教育投入3 | 出口贸易额4 | 城镇可支配收入5 | 通货膨胀率6 |
|---|---|---|---|---|---|---|---|
| 万人 | 亿元 | 亿元 | 亿元 | 亿元 | 元 | % | |
| 1990 | 17041 | 18547.9 | 6767.2 | 102.52 | 1510.2 | 1510.2 | 3.1 |
| 1991 | 17465 | 20250.4 | 8542.5 | 119.39 | 1700.6 | 1700.6 | 3.4 |
| 1992 | 17861 | 23134.2 | 10317.8 | 151.34 | 2026.6 | 2026.6 | 6.4 |
| 1993 | 18262 | 26364.7 | 12093.1 | 204.45 | 2577.4 | 2577.4 | 14.7 |
| 1994 | 18653 | 29813.4 | 13868.4 | 261.53 | 3496.2 | 3496.2 | 24.1 |
| 1995 | 19040 | 33070.5 | 15643.7 | 352.69 | 4283 | 4283 | 17.1 |
| 1996 | 19922 | 36380.4 | 17567.2 | 430.29 | 4838.9 | 4838.9 | 8.3 |
| 1997 | 20781 | 39762.7 | 19194.2 | 529.21 | 5160.3 | 5160.3 | 2.8 |
| 1998 | 21616 | 42877.4 | 22491.4 | 615.56 | 5425.1 | 5425.1 | -0.8 |
| 1999 | 22412 | 46144.6 | 23732.0 | 711.65 | 5854.02 | 5854.02 | -1.4 |
| 2000 | 23151 | 50035.2 | 26221.8 | 823.37 | 6280 | 6280 | 0.4 |
| 2001 | 23940 | 107449.7 | 30001.2 | 951.36 | 6859.6 | 6859.6 | 0.7 |
| 2002 | 24780 | 117208.3 | 35488.8 | 1164.56 | 7702.8 | 7702.8 | -0.8 |
| 2003 | 25639 | 128958.9 | 45811.7 | 1671.14 | 8472.2 | 8472.2 | 1.2 |
| 2004 | 26476 | 141964.5 | 59028.2 | 2024.82 | 9421.6 | 9421.6 | 3.9 |
| 2005 | 27331 | 156775.3 | 75095.1 | 2209.19 | 10493 | 10493 | 1.8 |
| 2006 | 28310 | 204556.1 | 93368.7 | 2270.23 | 11759.5 | 11759.5 | 1.5 |
| 2007 | 29350 | 26651.01 | 117464.5 | 2375.55 | 13785.8 | 13785.8 | 4.8 |
其中,指标GDP总量、城镇总投资、教育投入(以教育投入资金表示)、出口贸易额、城镇居民人均可支配收入、通货膨胀率、消费指数、市场化程度(以人均年社会消费品零售额表示)、城镇化水平(以全国从事第二三产业人口占全国人口比重表示)、全国人口总数和居民储蓄总额的数据来源于1991-2007年的《中国统计年鉴》,而指标利率和汇率来源于《世界经济年鉴2008-2009》。
表(续) 城镇就业人数与各影响因素数据一览表
| 年 | 消费指数7 | 市场化程度8 | 城镇化水平9 | 人口总数10 | 汇率11 | 利率12 | 居民储蓄总额13 |
|---|---|---|---|---|---|---|---|
| 份 | 1990为100 | 元/人 | % | 万人 | 万人 | % | 亿元 |
| 1990 | 103.1 | 699.75 | 22.01 | 114333 | 478.32 | 1.8 | 5911.2 |
| 1991 | 103.4 | 812.96 | 22.79 | 115823 | 478.32 | 1.8 | 9241.6 |
| 1992 | 106.4 | 938.29 | 23.43 | 117171 | 478.32 | 3.15 | 11759.4 |
| 1993 | 114.7 | 1051.5 | 24.58 | 118517 | 478.32 | 3.15 | 15203.5 |
| 1994 | 124.1 | 1357.1 | 25.72 | 119850 | 478.32 | 3.15 | 21518.8 |
| 1995 | 117.1 | 1702.4 | 26.86 | 121121 | 835.1 | 1.98 | 29662.3 |
| 1996 | 108.3 | 2024.2 | 27.89 | 122389 | 831.42 | 1.71 | 38520.8 |
| 1997 | 102.8 | 2208.2 | 28.29 | 123626 | 828.98 | 1.44 | 46279.8 |
| 1998 | 99.2 | 2336.7 | 28.42 | 124761 | 827.91 | 1.44 | 53407.5 |
| 1999 | 98.6 | 2475.2 | 28.32 | 125786 | 827.83 | 0.99 | 59621.8 |
| 2000 | 100.4 | 2694.7 | 28.44 | 126743 | 827.84 | 0.99 | 64332.4 |
| 2001 | 100.7 | 2945.7 | 28.61 | 127627 | 827.7 | 0.99 | 73762.4 |
| 2002 | 99.2 | 3184.9 | 28.72 | 128453 | 827.7 | 0.72 | 86910.6 |
| 2003 | 101.17 | 3558 | 29.32 | 129227 | 827.7 | 0.72 | 103617.3 |
| 2004 | 103.9 | 4163 | 30.72 | 129988 | 827.68 | 0.72 | 119555.4 |
| 2005 | 101.8 | 5153 | 31.96 | 130756 | 819.17 | 0.72 | 141051 |
| 2006 | 101.45 | 5828 | 33.35 | 131448 | 797.18 | 0.72 | 161587.3 |
| 2007 | 104.8 | 6769 | 34.47 | 132129 | 760.4 | 0.72 | 172534.2 |
利率和汇率来源于《世界经济年鉴2008-2009》,其它指标来源于1991-2008年的《中国统计年鉴》。
请回答下列问题
1.哪些变量服从正态分布?
2.计算教育投入、出口贸易额、城镇可支配收入、市场化程度、城镇化水平、人口总数、居民储蓄总额之间的偏相关系数(只关注这几个变量,其他变量不容考虑)。
1.1问题1
SAS代码:
1 | data ex; |
分析结果时,我们只需要看正态性检验中第二个是否大于0.05即可,大于0.05即拒绝不是正态分布的原假设,最后发现:
计算教育投入、出口贸易额、城镇可支配收入、市场化程度、城镇化水平、人口总数、居民储蓄总额这几个变量呈正态分布。
1.2问题2
SAS代码:
1 | data ex; |
2.通径分析
继续运用上求的数据。请将城镇失业人数对教育投入、出口贸易额、城镇可支配收入、市场化程度、城镇化水平、人口总数、居民储蓄总额进行通径分析。写出通径方程,求出直接通径,并将结果与标准化回归系数进行对比。
根据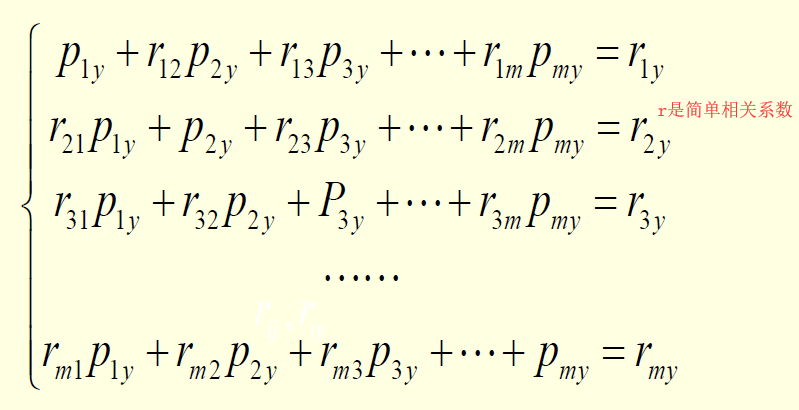
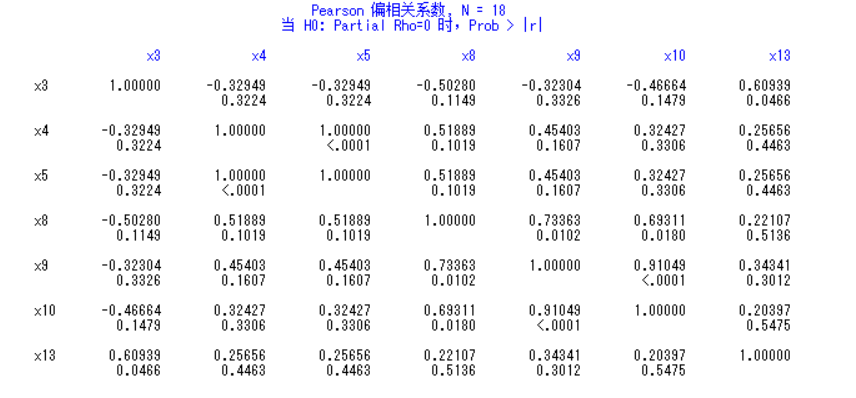
先求简单相关系数
1 | proc corr;var x3-x5 x8-x10 x13 y; |

写出通径方程:
……………………
求出p1、p2、……、p13的值
求出后我们需要算出标准化系数,修改SAS代码:
1 | proc reg;model y=x3 x4 x8-x10 x13 stb; |
这里应该错了,结果分析不出来。如有想法,请在评论区交流。后续如果会了会更新这部分。
3.典型相关分析
这是调查表,请做学生、专家、同事打分与其影响因素的典型相关分析
| 教师编 号 | 教师学历 x1 | 教师年龄 x2 | 单位工时 x2 | 发表论文数 x4 | 教师职称 x5 | 拥有科研经费 x6 | 找学生谈话次数 x7 | 教师气质 x8 | 学生打分 y1 | 专家打分 y2 | 同事打分 y3 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 41 | 4 | 12 | 5 | 10 | 1 | 7 | 88.10 | 90 | 98 |
| 2 | 3 | 40 | 5 | 4 | 4 | 0 | 3 | 9 | 92.60 | 95 | 98 |
| 3 | 3 | 44 | 20 | 0 | 4 | 3 | 1 | 7 | 88.40 | 84 | 95 |
| 4 | 3 | 52 | 5 | 22 | 5 | 6 | 1 | 6 | 87.40 | 86 | 99 |
| 5 | 3 | 59 | 22 | 4 | 5 | 1 | 5 | 9 | 94.10 | 99 | 99 |
| 6 | 3 | 50 | 17 | 12 | 4 | 2 | 3 | 9 | 94.30 | 99 | 99 |
| 7 | 3 | 44 | 22 | 2 | 4 | 0 | 0 | 8 | 87.40 | 80 | 90 |
| 8 | 4 | 41 | 15 | 16 | 4 | 1 | 1 | 7 | 89.89 | 80 | 95 |
| 9 | 4 | 41 | 5 | 8 | 4 | 0 | 1 | 7 | 94.60 | 93 | 98 |
| 10 | 4 | 35 | 12 | 12 | 4 | 2 | 4 | 6 | 93.60 | 98 | 95 |
| 11 | 3 | 34 | 6 | 0 | 3 | 0 | 3 | 8 | 91.70 | 98 | 95 |
| 12 | 4 | 34 | 5 | 4 | 3 | 0 | 0 | 8 | 88.90 | 90 | 94 |
| 13 | 3 | 30 | 9 | 0 | 3 | 0 | 1 | 7 | 89.60 | 92 | 92 |
| 14 | 3 | 30 | 7 | 0 | 3 | 0 | 1 | 8 | 88.30 | 85 | 92 |
| 15 | 4 | 34 | 11 | 2 | 3 | 0 | 0 | 6 | 84.90 | 78 | 90 |
| 16 | 3 | 30 | 7 | 1 | 3 | 0 | 1 | 9 | 90.90 | 96 | 92 |
| 17 | 3 | 29 | 6 | 3 | 3 | 0 | 1 | 8 | 91.50 | 90 | 93 |
| 18 | 3 | 29 | 6 | 1 | 3 | 0 | 1 | 7 | 85.80 | 88 | 92 |
| 19 | 3 | 29 | 6 | 4 | 3 | 0 | 0 | 7 | 86.50 | 87 | 92 |
| 20 | 3 | 27 | 5 | 1 | 2 | 0 | 1 | 9 | 93.82 | 93 | 90 |
| 21 | 3 | 27 | 5 | 1 | 2 | 0 | 0 | 8 | 91.74 | 90 | 88 |
| 22 | 3 | 27 | 5 | 2 | 2 | 0 | 0 | 7 | 91.50 | 86 | 88 |
| 23 | 3 | 27 | 5 | 11 | 2 | 0 | 0 | 7 | 89.30 | 86 | 87 |
| 24 | 3 | 27 | 5 | 1 | 2 | 0 | 1 | 7 | 92.00 | 93 | 88 |
| 25 | 3 | 26 | 5 | 2 | 2 | 0 | 0 | 8 | 87.60 | 92 | 88 |
| 26 | 4 | 26 | 2 | 4 | 2 | 3 | 2 | 7 | 92.00 | 93 | 87 |
| 27 | 4 | 34 | 3 | 4 | 3 | 3 | 0 | 7 | 90.40 | 88 | 89 |
| 28 | 4 | 28 | 3 | 4 | 3 | 3 | 0 | 6 | 90.10 | 95 | 86 |
| 29 | 4 | 30 | 3 | 3 | 3 | 3 | 0 | 7 | 93.60 | 84 | 89 |
| 30 | 4 | 32 | 3 | 4 | 3 | 3 | 0 | 7 | 89.10 | 84 | 88 |
| 31 | 5 | 37 | 2 | 6 | 4 | 3 | 0 | 7 | 84.20 | 80 | 88 |
| 32 | 4 | 34 | 3 | 3 | 3 | 0 | 2 | 9 | 87.90 | 86 | 88 |
| 33 | 4 | 28 | 2 | 5 | 2 | 3 | 1 | 7 | 84.00 | 85 | 85 |
| 34 | 4 | 28 | 2 | 4 | 2 | 3 | 1 | 8 | 89.70 | 88 | 85 |
| 35 | 4 | 28 | 2 | 4 | 2 | 3 | 0 | 8 | 88.90 | 84 | 85 |
| 36 | 4 | 27 | 1 | 2 | 1 | 0 | 0 | 8 | 87.88 | 83 | 82 |
| 37 | 4 | 26 | 1 | 1 | 1 | 0 | 0 | 6 | 80.67 | 80 | 82 |
SAS代码:
1 | data ex; |
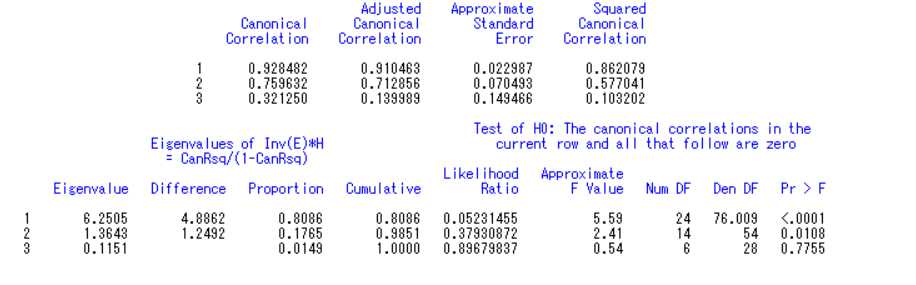
前两个典型相关系数较高,表明相应典型变量之间密切相关。并且只有前两对典型变量通过了统计量检验,表明相应典型变量之间相关关系显著,能够用三个自变量影响变量来解释产出变量。
典型相关模型结果如下:

根据此能写出典型相关模型式子。
在第一对典型变量V1和W1中,同事打分(y3)在典型变量V1中载荷为0.214,是所有打分指标中最大的。而自变量x5在典型变量w1中载荷最大,为0.9364。说明教师职称(x5)对同事打分(y3)起关键作用。
在第二对典型变量V2和W2中,专家打分(y2)在典型变量V2中载荷为0.1985,是所有打分指标中最大的。而自变量x7在典型变量w2中载荷最大,为0.8022。说明找学生谈话次数(x7)对专家打分(y2)起关键作用。
在第三对典型变量V3和W3中,学生打分(y1)在典型变量V3中载荷为0.4466,是所有打分指标中最大的。而自变量x8在典型变量w3中载荷最大,为1.069。说明找教师气质(x8)对学生打分(y3)起关键作用。
4.主成分分析
下表是某地区某时间的气候综合指数,其中,x1为某地区平均降水量,x2为气压值,x3为气温值,x4为绝对湿度。试用主成分分析法分析该地区的气候综合指数。
| x1 | 42.4 | 10.2 | 116.8 | 4.8 | 43.6 | 13.3 | 61.1 | 99.3 | 139.3 | 55.5 | 68.3 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| x2 | 12 | 19.4 | 24.6 | 28.8 | 24.7 | 28.3 | 18.7 | 18.3 | 9.4 | 8.1 | 3.5 |
| x3 | 24 | 18.4 | 12.5 | 1 | 2.8 | 1.8 | 8.8 | 13.7 | 18.7 | 22.6 | 26.7 |
| x4 | 22.7 | 15.1 | 12.1 | 4.4 | 5.4 | 4.7 | 8.5 | 11.8 | 17.9 | 22.3 | 29.1 |
| x1 | 83.4 | 90 | 18.8 | 47.6 | 99.6 | 100.1 | 80.6 | 90 | 100.8 | 146.1 | 55.1 |
| x2 | 5.7 | 12.8 | 19.4 | 22.8 | 21 | 23 | 2.8 | 21.2 | 15.1 | 8.4 | 6.7 |
| x3 | 27.5 | 23.7 | 17.4 | 13.3 | 9.5 | 3.6 | 2.6 | 6.8 | 14.2 | 19.6 | 22.4 |
| x4 | 29.4 | 23.6 | 15.1 | 12.3 | 10.6 | 6.7 | 6.2 | 8.3 | 13.7 | 18.6 | 21.2 |
编写SAS主成分分析代码:
1 | data ex; |
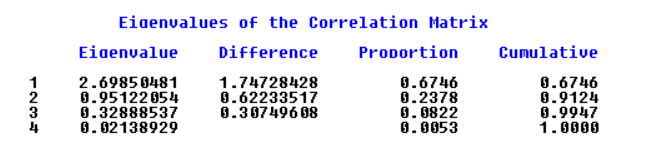
从程序结果可以看出,第一、第二主成分累计解释方差的比率已经超过了91%,所以只需要求λ1、λ2所对应的正交化特征向量αi

可以看出第一主成分与气压值、气温值、绝对湿度密切相关,第二主成分与平均降水量密切相关。
主成分得分:
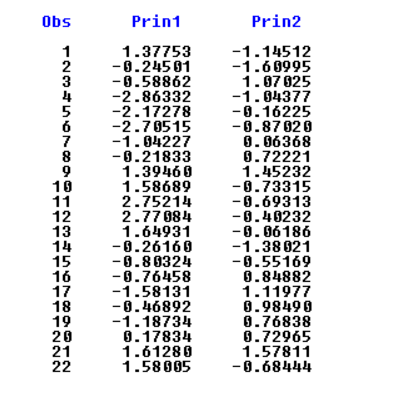
可以看出第12组数据综合评价得分最高,即第12组数据天气综合指数最高。
5.因子分析
对10名大学生进行有关价值观的测验,包括9个项目,测试结果如下表所示,表中数据为各学生在相应测验项目上的得分。试根据这9项内容作相应的因子分析,即对9名学生进行有关价值观的排序。
| 合作性 | 16 | 18 | 17 | 17 | 16 | 20 | 18 | 14 | 19 | 19 |
|---|---|---|---|---|---|---|---|---|---|---|
| 服从分配 | 16 | 19 | 17 | 17 | 15 | 17 | 16 | 16 | 19 | 14 |
| 出发基础 | 13 | 15 | 17 | 17 | 16 | 16 | 16 | 15 | 20 | 14 |
| 工作投入 | 18 | 16 | 14 | 16 | 16 | 17 | 20 | 19 | 14 | 116 |
| 发展机会 | 16 | 18 | 17 | 19 | 18 | 18 | 15 | 19 | 18 | 17 |
| 社会地位 | 17 | 18 | 18 | 18 | 18 | 18 | 16 | 19 | 20 | 16 |
| 上进心 | 15 | 18 | 16 | 19 | 15 | 17 | 19 | 18 | 19 | 17 |
| 职位升迁 | 16 | 17 | 16 | 20 | 16 | 19 | 14 | 19 | 17 | 18 |
| 领导风格 | 16 | 19 | 16 | 19 | 16 | 18 | 17 | 14 | 20 | 19 |
编写SAS因子分析代码:
1 | data ex; |

结果表明,应选取2个因子,记为F1,F2,F3 贡献率分别为38.62%、25.06%、18.62%
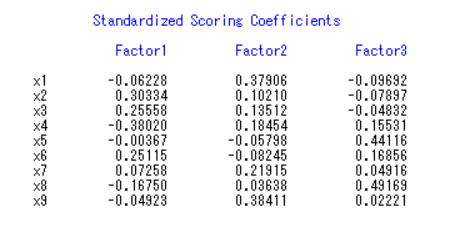
由图可看出,第一公因子和服从分配、出发基础、工作投入 、社会地位密切相关,第二公因子和合作性、领导风格密切相关,第三公因子和发展机会、职位升迁密切相关。
因子得分:

以上为10个样本的9个指标值,以及3个公共指标的得分,因子F1、F2中第9位学生的得分最高,说明该学生的价值观更偏向于服从分配、出发基础、社会地位、合作性、领导风格。因子F3中第8位学生的得分最高,说明该学生的价值观更偏向于发展机会、职位升迁。
6.聚类分析
现有8个企业,对每个企业用3个指标来刻画企业的技术密集水平:生产工人劳动生产率(x)、每百万元固定资产所容纳的职工人数(y)和技术管理人员在职工中的比重(z)。具体数据如下表,试对这8个企业的技术密集水平作聚类分析。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| x | 1.8 | 2.1 | 3.2 | 2.2 | 2.5 | 2.8 | 1.9 | 2.0 |
| y | 95 | 99 | 101 | 103 | 98 | 102 | 120 | 130 |
| z | 0.15 | 0.21 | 0.18 | 0.17 | 0.16 | 0.20 | 0.09 | 0.11 |
SAS代码:
1 | data ex; |
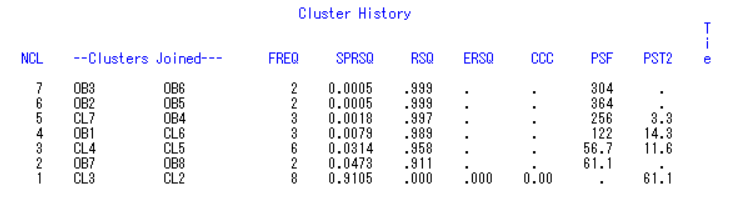
从图中可以看出,当从两类合并到一类时,信息损失了91.05%,远超10%,故分为两类最为合适。
聚类分析效果图如下:
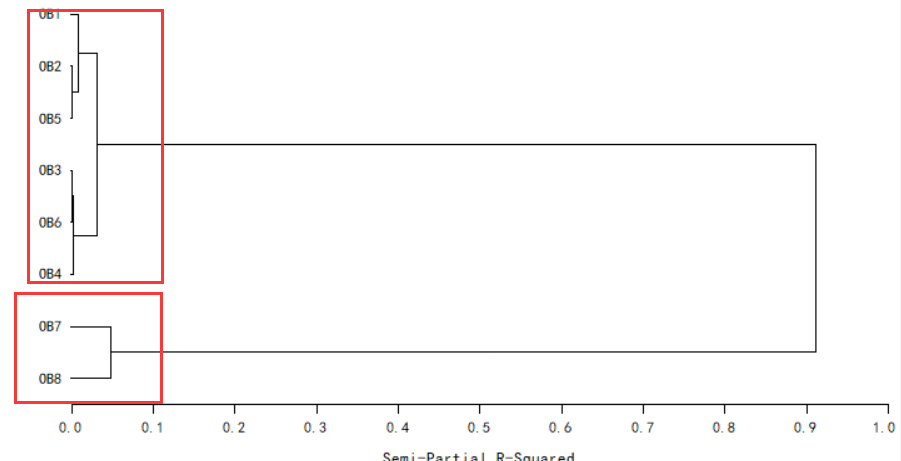
综合以上分析,可以得到结果,将工厂分为2类,分别为第1类:1、2、5、3、6、4;第2类:7、8。
7.判别分析
观测3名健康人和4名心肌梗塞病人的心电图的3项指标x、y、z所得的观测值如下表,现有一人心电图的3项指标为(400.72,49.46,2.25),请问他应属两类中的哪一类。哪个变量是判断最主要的变量?
| 类 | 号 | x | y | z |
|---|---|---|---|---|
| 1(健康) | 1 | 436.70 | 49.59 | 2.32 |
| 1 | 2 | 290.67 | 30.02 | 2.46 |
| 1 | 3 | 352.53 | 36.23 | 2.36 |
| 2(病人) | 1 | 510.47 | 67.64 | 1.73 |
| 2 | 2 | 510.41 | 62.71 | 1.58 |
| 2 | 3 | 470.30 | 54.40 | 1.68 |
| 2 | 4 | 364.12 | 46.26 | 2.09 |
SAS代码:
1 | data ex; |

因此Bayes 判别式为:
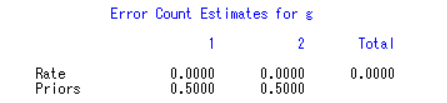
两类的误判率均为0,说明判别能力很强,于是可以利用已经得到的判别函数去判别新样本。

此人心电图指标归于第1类的概率高,归于第2类的概率低,所以将此人心电图指标归于第1类——健康。
结语
写这篇文章写到最后NMD蓝屏了,我还没保存,本来八千多字瞬间降到两千字!心态炸裂。还好Typora比较强大,每隔一段时间自动保存到一个文件夹,虽然还是丢失了不少,但是至少比全丢了强。
嗯,说了这么多,我想表达的就是——神州真TM坑,没事别追求性价比上船,血妈痛的教学(╬▔皿▔)凸

