
EverydayOneCat
ᗢᕡᓗ看來任務失敗了

一、[BX]和loop指令
1.[bx]和内存单元的描述
在masm编译器中,编译器会把mov ax,[0]认为是mov ax,0,就是把中括号直接无视了,这时候我们要想达到预期效果,需要用到bx
bx也是一个通用寄存器,不过是用来存放偏移地址的,一般用法为:
1 | mov bx,xxH |
要完整地描述一个内存单元, 需要两种信息: @内存单元的地址; @内存单元的长度
用[O]表示一个内存单元时, 0 表示单元的偏移地址, 段地址默认在ds 中, 单元的长度(类型)可以由具体指令中的其他操作对象(比如说寄存器)指出。
2.描述性的符号()
为了描述上的简洁,我们将使用一个描述性的符号” () ” 来表示一个寄存器或一个内存单元中的内容。如:
(ax)表示ax 中的内容、(al)表示al 中的内容;(20000H)表示内存20000H 单元的内容(0中的内存单元的地址为物理地址);
3.约定符号idata表示常量
我们在Debug 中写过类似的指令: mov ax,[O], 表示将ds:O 处的数据送入ax 中。指令中, 在“ […]”里用一个常量0 表示内存单元的偏移地址。以后, 我们用idata 表示常量。比如:
mov ax,[idata]就代表mov ax,[l ] 、mov ax,[2] 、mov ax,[3]等。
mov bx,idata 就代表mov bx,1、mov bx,2、mov bx,3 等。
4.Loop指令
loop指令就相当于do……while……循环
CPU执行loop 指令的时候, 要进行两步操作,1、(cx) =(cx)-1;2、判断cx 中的值, 不为零则转至标号处执行程序, 如果为零则向下
执行。
cx中通常存放循环次数,一般框架:
1 | mov cx,循环次数 |
5.在Debug 中跟踪用loop 指令实现的循环程序
计算ffff:0006单元中的数乘以3, 结果存储在dx中
分析:1、运算后的结果是否会超出dx所能存储的范围?
ffff:0006单元中的数是一个字节型的数据,范围在0~255之间,则用它和3相乘结果不会大于65535, 可以在dx中存放下。
2、用循环累加来实现乘法,用哪个寄存器进行累加?
将ffff:0006 单元中的数赋值给ax, 用dx进行累加。先设(dx)=O, 然后做3 次(dx)=(dx)+(ax)。
1 | assume cs:code |
Debug调试:
1、g指令
循环程序段从CS:0012 开始, CS:0012前面的指令, 我们不想再一步步地跟踪, 希望能够一次执行完, 然后从CS:0012处开始跟踪。可以这样来使用g命令, “g0012”, 它表示执行程序到当前代码段(段地址在CS中)的0012b处
2、p
我们希望将循环一次执行完。可以使用p命令来达到目的。再次遇到loop指令时, 使用p命令来执行,Debug就会自动重复执行循环中的指令, 直到(cx)=0为止。
6.loop和[bx]的联合应用
问题:计算ffff:0~ffff:b单元中的数据的和, 结果存储在dx中。
分析:
(1)运算后的结果是否会超出dx 所能存储的范围?
ffff: 0-ffff: b 内存单元中的数据是字节型数据, 范围在0~255之间,12个这样的数据相加, 结果不会大于65535, 可以在dx中存放下。
(2)我们能否将ffff:0-ffff: b中的数据直接累加到dx中?
当然不行, 因为ffff:0-ffff: b中的数据是8位的, 不能直接加到16位寄存器dx中。
( 3)我们能否将ffff:0~ ffff:b 中的数据累加到di中, 并设置(dh)=0, 从而实现累加到dx中?
这也不行, 因为dl 是8 位寄存器, 能容纳的数据的范围在0~255之间,ffff:0~ffff: b中的数据也都是8位, 如果仅向di中累加12个8位数据, 很有可能造成进位丢失。
目前的方法(在后面我们还有别的方法)就是得用一个16位寄存器来做中介。将内存单元中的8位数据赋值到一个16位寄存器ax
中, 再将ax中的数据加到dx上, 从而使两个运算对象的类型匹配并且结果不会超界。
1 | assume cs:code |
7.段前缀
指令“ mov ax,[bx]” 中, 内存单元的偏移地址由bx 给出, 而段地址默认在ds 中。我们可以在访问内存单元的指令中显式地给出内存单元的段地址所在的段寄存器。比如:
1 | mov ax,ds:[bx] |
这些出现在访问内存单元的指令中, 用千显式地指明内存单元的段地址的”ds:” “cs:” “ss:” “es:”, 在汇编语言中称为段前缀。
段前缀的使用:将内存ffff:0-ffff: b 单元中的数据复制到0:200~0:20b 单元中
分析:0:200-0:206 单元等同千0020:0-0020:b 单元, 它们描述的是同一段内存空间。(这样有助于我们知道循环12次)
1 | assume cs:code |
二、包含多个段的程序
前面的程序中, 只有一个代码段。现在有一个问题是, 如果程序需要用其他空间来存放数据, 使用哪里呢?
程序取得所需空间的方法有两种, 一是在加载程序的时候为程序分配, 再就是程序在执行的过程中向系统申请。
我们若要一个程序在被加载的时候取得所需的空间, 则必须要在源程序中做出说明。我们通过在源程序中定义段来进行内存空间的获取。
1.在代码段中使用数据
问题:编程计算以下8个数据的和, 结果存在ax寄存器中:0123h、0456h、0789h、0abch、0defh、0fedh、0cbah、0987h
1 | assume cs:code |
程序第一行中的“ dw” 的含义是定义字型数据。dw 即“ defme word” 。在这里, 使用dw 定义了8 个字型数据(数据之间以逗号分隔), 它们所占的内存空间的大小为16 个字节。在cs段中定义,因为用dw 定义的数据处千代码段的最开始, 所以偏移地址为0, 这8 个数据就在代码段的偏移0、2 、4、6、8、A、C 、E 处。
dw用了系统会分配指定空间,我们也可用它来分配空间(栈中使用)
在程序的第一条指令的前面加上了一个标号start,而这个标号在伪指令end 的后面出现。这里, 我们要再次探讨end 的作用。end 除了通知编译器程序结束外, 还可以通知编译器程序的入口在什么地方。
2.在代码段中使用栈
问题:定义的数据存放在cs:仁cs:F 单元中, 共8 个字单元。依次将这8 个字单元中的数据入栈, 然后再依次出栈到这8个字单元中, 从而实现数据的逆序存放。
分析:
我们首先要有一段可当作栈的内存空间。如前所述, 这段空间应该由系统来分配。可以在程序中通过定义数据来取得一段空间, 然后将这段空间当作栈空间来用
我们要将cs:1 O~cs:2F的内存空间当作栈来用, 初始状态下栈为空, 所以ss:sp要指向栈底, 则设置ss: sp指向cs:30。
1 | assume cs:codesg |
3.将数据、代码、栈放入不同的段
在前面的内容中, 我们在程序中用到了数据和栈, 将数据、栈和代码都放到了一个段里面。这样做显然有两个问题:
(l)把它们放到一个段中使程序显得混乱;
(2)前面程序中处理的数据很少, 用到的栈空间也小, 加上没有多长的代码, 放到一个段里面没有问题。但如果数据、栈和代码需要的空间超过64KB, 就不能放在一个段中
多个段来表示和上一个一样的功能:
1 | assume cs:code,ds:data,ss:stack |
这里我们分别定义了数据段,程序段,栈段。” 代码段” 、“数据段” 、“栈段“ 完全是我们的安排
对千如下定义的段:
name segment
name ends
如果段中的数据占N个字节, 则程序加载后, 该段实际占有的空间为16*(N/16+1)。
三、更灵活的定位内存地址的方法
1.and和or指令
and指令: 逻辑与指令, 按位进行与运算。例如指令:
mov al, 01100011B
and al, 00111011B
执行后: al=00100011B
通过该指令可将操作对象的相应位设为o, 其他位不变。将al的第6位设为0的指令是: andal,1011111 IB
or指令: 逻辑或指令, 按B位进行或运算。例如指令:
mov al, 01100011B
or al, 00111011B
执行后: al=01111011B
通过该指令可将操作对象的相应位设为1, 其他位不变。
2.ASCII码
世界上有很多编码方案, 有一种方案叫做ASCII编码, 是在计算机系统中通常被采用的。
我们可以在汇编程序中, 用'……'的方式指明数据是以字符的形式给出的, 编译器将把它们转化为相对应的ASCII码。如:
db ‘unIX’ db ‘foRK’ mov al,’a’ mov bl,’b’
我们通过观察表得出:小写字母的ASCII码值比大写字母的ASCII码值大20H,就ASCII 码的二进制形式来看, 除第5 位(位数从0 开始计算)外, 大写字母和小写字母的其他各位都一样。大写字母ASCII 码的第5 位为0, 小写字母的第5 位为1。
可以用and和or方法将一个数据中的某一位置0 还是置1
1 | assume cs:codesg,ds:datasg |
3.[bx+idata]进行数组的处理
我们用[bx]的方式来指明一个内存单元, 还可以用一种更为灵活的方式来指明内存单元: [bx+idata] 表示一个内存单元, 它的偏移地址为(bx)+idata(bx 中的数值加上idata)。
我们对上述大小写进行改进:
1 | mov ax,datasg |
C 语言: a[i], b[i]
汇编语言: O[bx], 5[bx]
通过比较, 我们可以发现,[bx+idata]的方式为高级语言实现数组提供了便利机制
4.SI和DI
si 和di 是8086CPU 中和bx 功能相近的寄存器, si 和di 不能够分成两个8 位寄存器来使用。
用si 和di 实现将字符串’welcome to masm!'复制到它后面的数据区中。
1 | codesg segmen |
[bx+si]和[bx+di]还有[bx+si+idata]和[bx+di+idata]和之前功能差不多,这里不做过多赘述
5.不同的寻址方式的灵活应用
将datasg 段中每个单词改为大写字母。、
在datasg 中定义了4 个字符串, 每个长度为16 个字节(注意, 为了使我们在Debug 中可以直观地查看, 每个字符串的后面都加上了空格符, 以使它们的长度刚好为16 个字节)。因为它们是连续存放的, 我们可以将这4 个字符串看成一个4 行16 列的二维数组。按照要求, 我们需要修改每一个单词, 即二维数组的每一行的前3列。
这里我们需要一个嵌套循环,但是cx只能放一个,实现不了嵌套。而8086CPU只有14个寄存器,我们需要用内存空间来进行存储,如果规定特定的内存空间,你必须要记住数据放到了哪个单元中,容易混乱。因此我们可以使用栈这个结构。
一般来说, 在需要暂存数据的时候, 我们都应该使用栈
1 | assume cs:codesg,ds:datasg,ss:s七acksg |
四、数据处理的两个基本问题
(1) 处理的数据在什么地方?
(2) 要处理的数据有多长?
我们定义的描述性符号: reg和sreg。reg 来表示一个寄存器, 用sreg表示一个段寄存器。
reg 的集合包括: ax、bx、ex、dx、ah、al、bh、bl、ch、cl、dh、di、sp、bp、si、di;
sreg的集合包括: ds、ss、cs、es 。
1.bx 、si 、di和bp
在8086CPU 中, 只有这4 个寄存器可以用在“ […]”中来进行内存单元的寻址。
在[……]中, 这4个寄存器可以单个出现, 或只能以4种组合出现:bx和si、bx和di、bp和si、bp和di。
但是,bx和bp不能组合,si和di不能组合
1、bx默认在ds中,可以和si,di组合使用
2、bp默认在ss中,可以和si,di组合使用
2.寻址方式
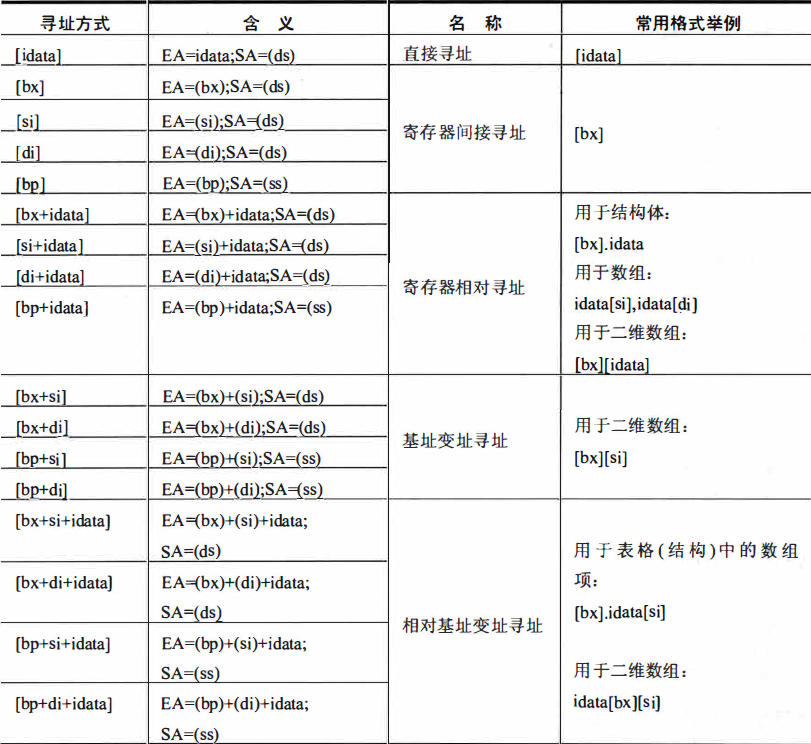
- 直接寻址:[常数]
- 寄存器间接寻址:[bx]
- 寄存器相对寻址:[bx+常数]
- 基址变址寻址:[bx+si]
- 相对变址寻址:[bx+si+常数]
3.指令要处理的数据长度
8086CPU的指令, 可以处理两种尺寸的数据, byte和word。所以在机器指令中要指明, 指令进行的是字操作还是字节操作。
(1)通过寄存器名指明要处理的数据的尺寸。
mov ax,1——字操作
mov al,1——字节操作
(2)在没有寄存器名存在的情况下, 用操作符X ptr 指明内存单元的长度, X在汇编指令中可以为word 或byte 。
mov word ptr ds: [0J, 1
mov byte ptr ds: [0],1
mov byte ptr [1000H],l 访问的是地址为ds:1000H 的字节单元, 修改的是ds1000H 单元的内容;而mov word ptr [1000H],l 访问的是地址为ds:1000H 的字单元, 修改的是ds:1000H 和ds:1001H 两个单元的内容。
(3) 其他方法
有些指令默认了访问的是字单元还是字节单元, 比如, push [1000H]就不用指明访问的是字单元还是字节单元, 因为push 指令只进行字操作。
4.寻址方式的综合应用
修改这些字段
1 | mov ax,seg |
5.div指令
div 是除法指令, 使用div 做除法的时候应注意以下问题。
( 1) 除数: 有8 位和16 位两种, 在一个reg 或内存单元中。
(2) 被除数:默认放在AX 或DX和AX 中, 如果除数为8 位, 被除数则为16 位,默认在AX 中存放;如果除数为16 位, 被除数则为32位, 在DX和AX 中存放, DX存放高16 位, AX 存放低16 位。
(3)结果: 如果除数为8位, 则AL存储除法操作的商, AH存储除法操作的余数;如果除数为16 位, 则AX 存储除法操作的商, DX存储除法操作的余数。
div byte ptr ds: [OJ
含义: (al)= (ax)/ ((ds) 16+0)的商
(ah)= (ax)/ ((ds) 16+0)的余数
div word ptr es: [0]
含义: (ax)= [ (dx) *10000H+ (ax) ] / ((es) 16+0)的商——10000H是为了变成32位
(dx) = [ (dx) 10000H+ (ax)] / ((es) 16+0)的余数
编程, 利用除法指令计算100001/100。
分析:被除数100001(186AIH)大于65535, 不能用ax 寄存器存放, 所以只能用dx和ax两个寄存器联合存放100001, 也就是说要进行16位的除法。除数100小千255, 可以在一个8位寄存器中存放, 但是, 因为被除数是32位的, 除数应为16位, 所以要用一个16位寄存器来存放除数100。
1 | mov dx,1 |
程序执行后,(ax)=03E8H(即1000), (dx)=l(余数为1)
编程, 利用除法指令计算1001/100。
分析:被除数1001可用ax寄存器存放, 除数100可用8位寄存器存放, 也就是说, 要进行8位的除法。
1 | mov ax,1001 |
程序执行后,(al)=0AH(即10), ( ah)=1(余数为1)。
6.伪指令dd
之前的回顾:db定义字节型,dw定义字形
dd 是用来定义dword(double word, 双字)型数据的。
1 | data segment |
第一个数据为01H, 在data:O 处, 占1 个字节;
第二个数据为0001H, 在data:1处, 占1 个字;
第三个数据为00000001H, 在data:3 处, 占2 个字。
问题:用div 计算data 段中第一个数据除以第二个数据后的结果, 商存在第三个数据的存储单元中。
1 | data segment |
分析:data 段中的第一个数据是被除数, 为dword(双字)型, 32 位, 所以在做除法之前, 用dx 和ax 存储。应将data:0 字单元中的低16 位存储在ax 中, data:2 字单元中的高16 位存储在dx 中。
1 | mov ax,data |
7.dup
dup 是一个操作符, 在汇编语言中同db 、dw 、dd 等一样, 也是由编译器识别处理的符号。它是和db 、dw 、dd 等数据定义伪指令配合使用的, 用来进行数据的重复。
db 3 dup (0)——定义了3 个字节, 它们的值都是o, 相当千db 0,0,0。
db 3 dup (0,1,2)——定义了9 个字节, 它们是0 、l 、2 、0 、1 、2 、0 、1 、2, 相当千db 0,1,2,0,1,2,0,1,2。
db 3 dup (‘abc’,’ABC’)——定义了18个字节, 它们是abcABCabcABCabcABC’, 相当千db’abcABCabcABCabcABC’o
dup是一个十分有用的操作符, 比如要定义一个容量为200 个字节的栈段:
1 | stack segment |
结语
今天好像说错话了,难顶😥

