
概述
所谓的线性表,就是将数据排成像一条长线一样的结构,数组,链表,栈,队列都是线性表结构,线性表上的每个数据最多只有前后两个方向。本文将对java中此结构的案例和应用源码做出详解。
1.数组
1.1概念
数组是一种线性表数据结构,它用一组连续的内存空间,来存储一组具有相同类型的数据。
1.2逻辑结构和物理结构
1.2.1定义
逻辑结构:我们可以用什么的表示方式来描述数组元素
物理结构:数组元素实际的存储形式
逻辑结构:可以通过下标方式表示数组
物理结构:连续的内存单元
1.2.2数组元素的访问
寻址公式 :a[i] = baseAddress + i * dataTypeSize
dataTypeSize 代表数组中元素类型的大小 ,如int类型为4字节
1.2.3数组下标为什么从 0 开始
从数组存储的内存模型上来看, “下标”最确切的定义应该是“偏移(offset) ”。
如果用 array 来表示数组的首地址 ,array[0] 就是偏移为 0 的位置,也就是首地址, array[k] 就表示偏移 k 个 type_size 的位置, 所以计算 array[k] 的内存地址只需要用这个公式:
array[k]_address = base_address + k * type_size
但是如果下标从 1 开始,那么计算 array[k]的内存地址会变成:
array[k]_address = base_address + (k-1)*type_size
对比两个公式,不难发现从数组下标从 1 开始如果根据下标去访问数组元素,对于 CPU 来说,就多了一次减法指令 ,效率就降低了。
还有一个原因应该是学的c语言这个祖先。
1.3特点
由于连续的内存空间,相同类型的数据,使得数组有如下两个特点:
高效的随机访问
低效插入和删除
1.3.1高效访问
数组元素的访问是通过下标来访问的,计算机通过数组的首地址和寻址公式能够很快速的找到想要访问的元素
1.3.2低效插入
除了插入最后,每次插入都需要把插入位置之后的每个元素向后挪一位
1.3.3低效删除(解决办法)
原因和上面插入类似,这里着重写一下解决办法:
在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。如果我们将多次删除操作集中在一起执行,删除的效率可以提高很多。
我们可以先记录下已经删除的数据。每次的删除操作并不是真正地搬移数据,只是记录数据已经被删除。当数组没有更多空间存储数据时,我们再触发执行一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。
JVM 标记清除垃圾回收算法的核心思想跟此类似
1.4应用(ArrayList源码分析)
针对数组类型,很多语言都提供了容器类,比如 Java 中的 ArrayList、 C++ STL 中的 vector。
1.4.1添加元素的动态扩容
ArrayList 最大的优势就是可以将很多数组操作的细节封装起来 ,并且支持数组的动态扩容,下面通过源码分析一下底层是怎么实现动态扩容的。

总结下来就是:
1:创建 ArrayList 时采用默认的构造函数创建集合然后往里添加元素,第一次添加时将数组扩容到 10 的大小,之后添加元素都不会在扩容,直到第 11 次添加然后扩容 1.5 倍取整,此后如果需要扩容都是 1.5 倍取整,但是扩容到的最大值是Integer.MAX_VALUE
2:每次扩容时都会创建一个新的数组,然后将原数组中的数据搬移到新的数组中
此外,ArrayList除了无参构造,还提供了有参构造。
如果事先能确定需要存储的数据大小,最好在创建ArrayList 的时候事先指定数据大小
比如我们要从数据库中取出 10000 条数据放入 ArrayList。相比之下,事先指定数据大小可以省掉很多次内存申请和数据搬移操作。
1.4.2获取元素

1.4.3ArrayList和数组的优劣
- Java ArrayList 无法存储基本类型,比如 int、 long,需要封装为 Integer、 Long 类,而 Autoboxing、 Unboxing 则有一定的性能消耗,所以如果特别关注性能,或者希望使用基本类型,就可以选用数组。
- 如果数据大小事先已知,并且对数据的操作非常简单,用不到 ArrayList 提供的大部分方法,也可以直接使用数组。
对于业务开发,直接使用容器就足够了,省时省力。毕竟损耗一丢丢性能,完全不会影响到系统整体的性能。但如果你是做一些非常底层的开发,比如开发网络框架,性能的优化需要做到极致,这个时候数组就会优于容器,成为首选。
2.链表
2.1概念
物理存储单元上非连续、非顺序,元素的逻辑顺序是通过链表中的指针链接次序实现的,链表由一系列结点组成,每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
2.2存储结构
数组:需要一块连续的存储空间,对内存的要求比较高,比如我们要申请一个1000M 的数组,如果内存中没有连续的足够大的存储空间则会申请失败,即便内存的剩余可用空间大于 1000M,仍然会申请失败。
链表:与数组相反,它并不需要一块连续的内存空间,它通过指针将一组零散的内存块串联起来使用,所以如果我们申请一个 1000M 大小的链表,只要内存剩余的可用空间大于 1000M,便不会出现问题。
2.3链表类型
2.3.1单链表
链表最基本的结构,内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。 我们把这个记录下个结点地址的指针叫作后继指针 next ,
我们习惯性地把第一个结点叫作头结点,把最后一个结点叫作尾结点。其中, 头结点用来记录链表的基地址,有了它,我们就可以遍历得到整条链表。而尾结点特殊的地方是:指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点。
在链表中插入或者删除一个数据,我们并不需要为了保持内存的连续性而搬移结点,因为链表的存储空间本身就不是连续的。所以,在链表中插入和删除一个数据是非常快速的。如你在p结点和q结点中间插入r结点,你只需要:
1 | r.next = p.next |
因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要根据针一个结点一个结点地依次遍历,直到找到相应的结点,所以,链表随机访问的性能没有数组好。
2.3.2循环链表
循环链表是一种特殊的单链表 。只需要单链表尾结点的next不指向null,而是指向头节点就是一个循环链表
2.3.3双向链表
单向链表只有一个方向,结点只有一个后继指针 next 指向后面的结点。而双向链表,顾名思义,它支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。
双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历,这样也带来了双向链表操作的灵活性。
应用:LinkedList,HashMap
2.3.4双向循环链表
循环链表和双向链表结合在一起
2.4链表和数组性能比较
数组简单易用,在实现上使用的是连续的内存空间,缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足( out of memory) ”。如果声明的数组过小,则可能出现不够用的情况。这时只能再申请一个更大的内存空间,把原数组拷贝进去,非常费时。
链表本身没有大小的限制,天然地支持动态扩容,我觉得这也是它与数组最大的区别。你可能会说,我们 Java 中的 ArrayList 容器,也可以支持动态扩容啊?我们上一节课讲过,当我们往支持动态扩容的数组中插入一个数据时,如果数组中没有空闲空间了,就会申请一个更大的空间,将数据拷贝过去,而数据拷贝的操作是非常耗时的。
总结:数组的优势是查询速度非常快,但是增删改慢;链表的优势是增删改快,但是查询慢。
2.5应用(LinkedList源码分析)
2.5.1通过无参构造函数创建容器并添加元素

可以得知:LinkedList 内部采用双向链表实现数据的存储
2.5.2通过索引从集合中获取元素
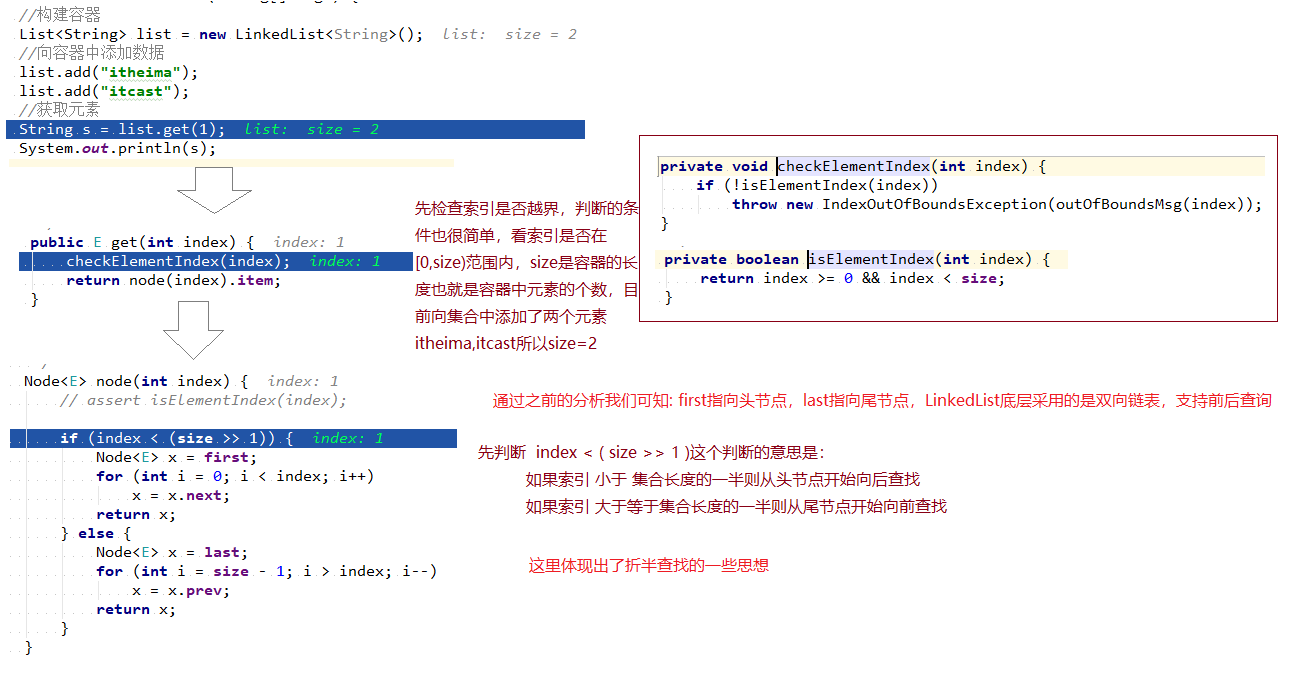
这里源码中通过双向链表和折半查找一部分解决了链表查询慢的问题
2.6面试题
2.6.1LinkedList 和 ArrayList 的比较
- ArrayList 的实现基于数组, LinkedList 的实现基于双向链表
- 对于随机访问, ArrayList 优于 LinkedList, ArrayList 可以根据下标对元素进行随机访问。而 LinkedList 的每一个元素都依靠地址指针和它后一个元素连接在一起,在这种情况下,查找某个元素只能从链表头开始查询直到找到为止
- 对于插入和删除操作, LinkedList 优于 ArrayList,因为当元素被添加到LinkedList 任意位置的时候,不需要像 ArrayList 那样重新计算大小或者是更新索引
- LinkedList 比 ArrayList 更占内存,因为 LinkedList 的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
2.6.2反转单链表
详情参见另一篇文章《leetcode 206.反转链表(链表)》
3.栈
3.1概念
栈就是一种操作受限的线性表,只允许在栈的一端进行数据的插入和删除,这两种操作分别叫做入栈和出栈。当某个数据集合如果只涉及到在其一端进行数据的插入和删除操作,并且满足先进后出,后进先出的特性时,我们应该首选栈这种数据结构来进行数据的存储。
特点:先进后出,后进先出 。 Last In First Out 即 LIFO
3.2实现
3.2.1基于数组顺序栈的实现
1 | public class ArrayStack { |
3.2.2支持动态扩容的顺序栈
修改上面代码
1 | /** |
3.2.3基于链表的链式栈的实现
定义双向链表节点对象
1 | public class Node { |
双向链表实现:
1 | /** |
定义单链表结点对象
1 | private static class Node { |
基于单链表实现的栈 :
1 | public class StackBasedOnLinkedList { |
3.3应用(Stack源码分析)
3.3.1栈的创建和元素入栈

3.3.2元素出栈

4.队列
4.1概念
队列和栈一样都属于一种操作受限的线性表,队列跟栈很相似,支持的操作也有限,最基本的两个操作一个叫入队列 enqueue(),将数据插入到队列尾部,另一个叫出队列 dequeue(),从队列头部取出一个数据。
先进先出,这就是典型的队列。 First In First Out 即 FIFO
4.2常见队列及实现
4.2.1顺序队列的实现(数组)
1 | public class ArrayQueue { |
4.2.2链式队列的实现(单链表)
1 | public class LinkedListQueue { |
4.3应用
一般情况下,如果是对一些及时消息的处理,并且处理时间很短的情况下是不需要队列的,直接阻塞式的方法调用就可以了。但是如果在消息处理的时候特别费时间,这个时候如果有新消息来了,就只能处于阻塞状态,造成用户等待。这个时候便需要引入队列了。当接收到消息后,先把消息放入队列中,然后再用新的线程进行处理,这个时候就不会有消息阻塞了。所以队列用来存放等待处理元素的集合,这种场景一般用于缓冲、并发访问,及时消息通信,分布式消息队列等。
结语
身体最重要😊
希望各位身体一直安康,今天又是不咕咕咕的一天

