EverydayOneCat
很多很多很多💃💃🕺🕺

🐈👈🐱 🛏️➡️🛌

2017 年,Google 在论文 Attention is All you need 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,其最大的优点是可以并行计算。
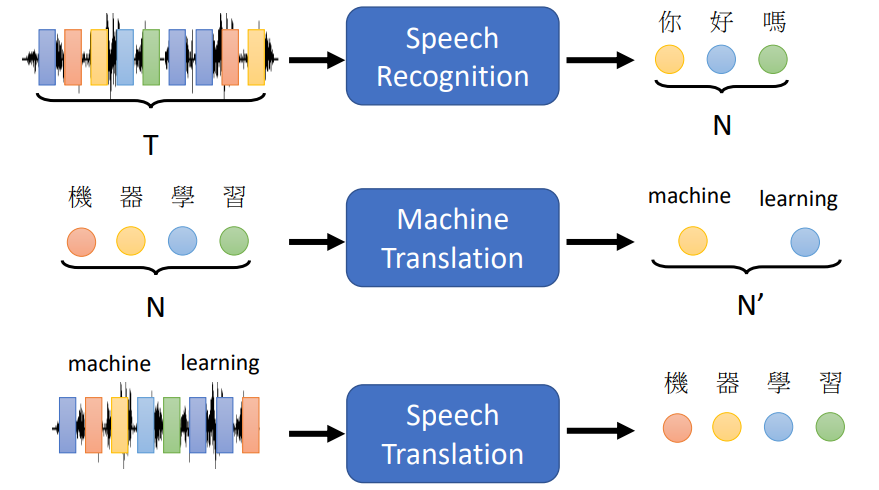
Seq2Seq的含义就是input是一个向量序列,output也是一个向量序列,并且output的长度由机器自己决定。
有很多场景都会用到Seq2Seq,如Text-to-Speech (TTS) Synthesis、Chatbot、Syntactic Parsing、Multi-label Classification等等
Seq2Seq主要结构分为两部分:Encoder(编码器)和Decoder(解码器)
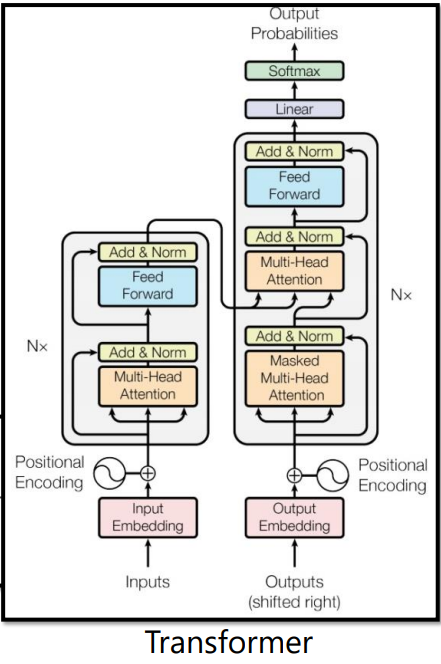
而目前我们在Seq2Seq场景使用的最常用的模型就是Transformer,整体结构如下图:
编码器Encoder的任务其实就是input一排向量集,output同等数量的向量集。这里就用到了我们上篇提到的self-attention,当然CNN和RNN也都能实现,但是效果不太好,主要原因可以看《自注意力机制Self-Attention》
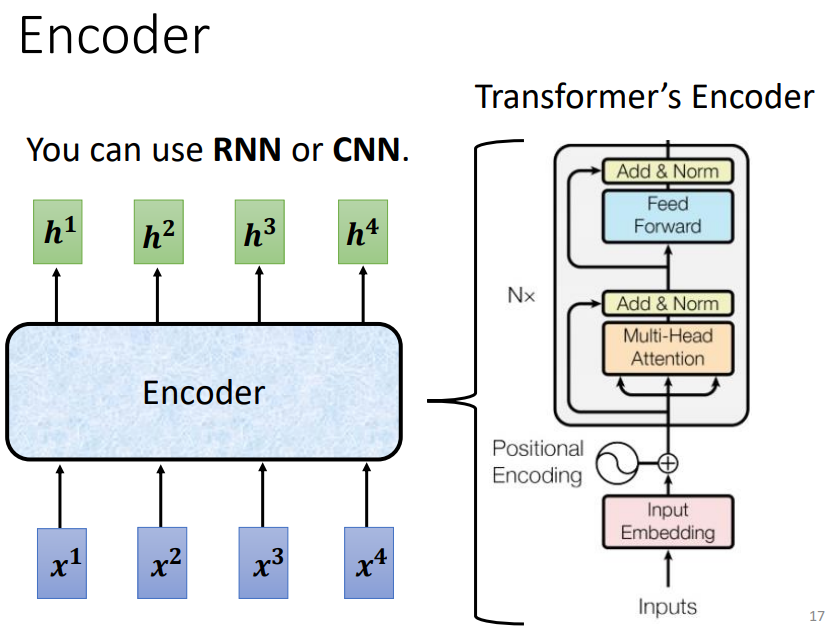
Transformer中的Encode具体结构如下:
Encoder里面会分成很多的block,每个block都是输入一排向量输出一排向量。
但是每个block并不是neural network的一层(layer),是因为一个block里面是好几个layer在做事情。
Transformer里面的block结构:
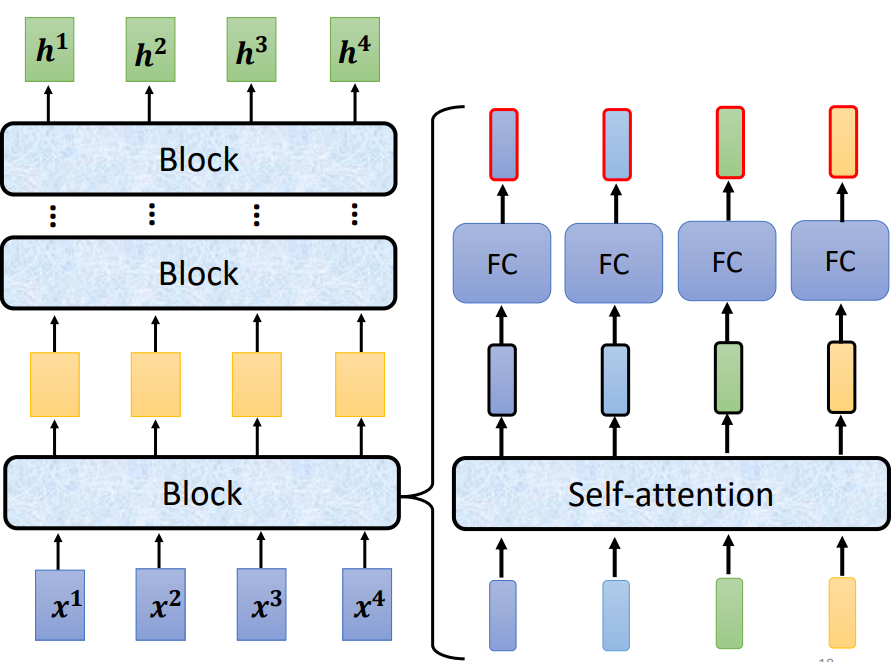
每个Block里的工作:输入一排向量—>经过self-attention处理—>输出一排向量—>在将输出的每个向量丢到fully connected的feed forward network里面在outout另外一排vector。
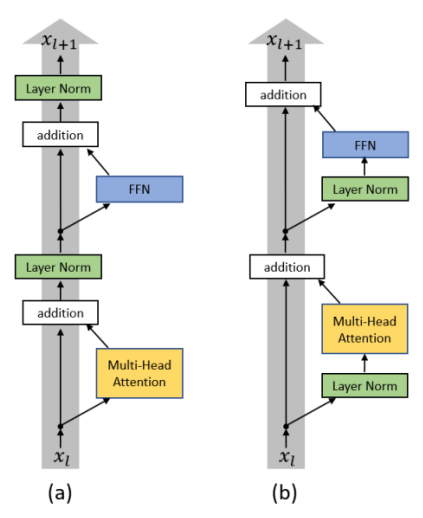
我们可以改进Block结构:加入残差residual结构,我们不只是输出一个vector,还要把输出的vector在加上它的input的到新的output。
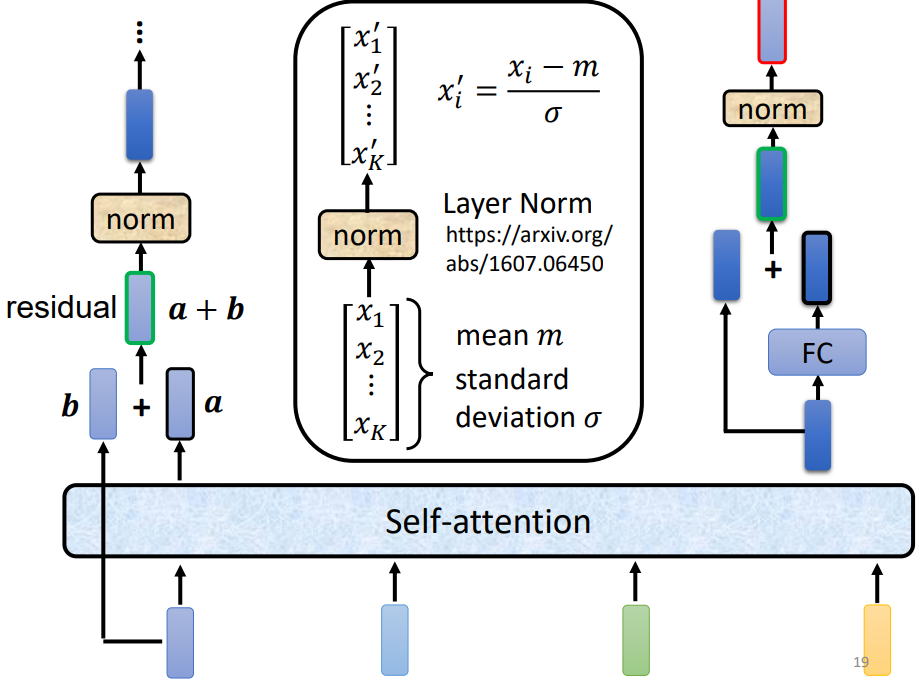
得到residual 的结果以后在经过norm,这里的norm不是batch normalization,用的是layer normalization。它做的事情比bacth normalization更简单一点,简而言之norm就是输入一个向量输出一个向量,不用考虑batch的资讯,过程就是对同一个feature同一个example里面不同的dimension去计算它的mean跟standard deviation,然后在经过标准化就是layer normalization的输出。这个输出后面是FC的输入,而FC里面也有residual的架构,我们会把FC network的input跟它的output加起来做一下residual得到新的输出,再把这个输出做一次layer normalization得到的才是真正的输出,这个输出才是transform encoder里面一个block的输出。
目前也有更多的研究觉得初始Transformer结构存在可优化的地方:
左边论文将layer normalization的顺序调整会达到更优的效果
右边论文讲解为什么batch normalization不如layer normalization
decoder其实有两种:Autoregressive (AT) 和Non-autoregressive(NAT)
我们举例语音辨识过程来了解它的运作过程。
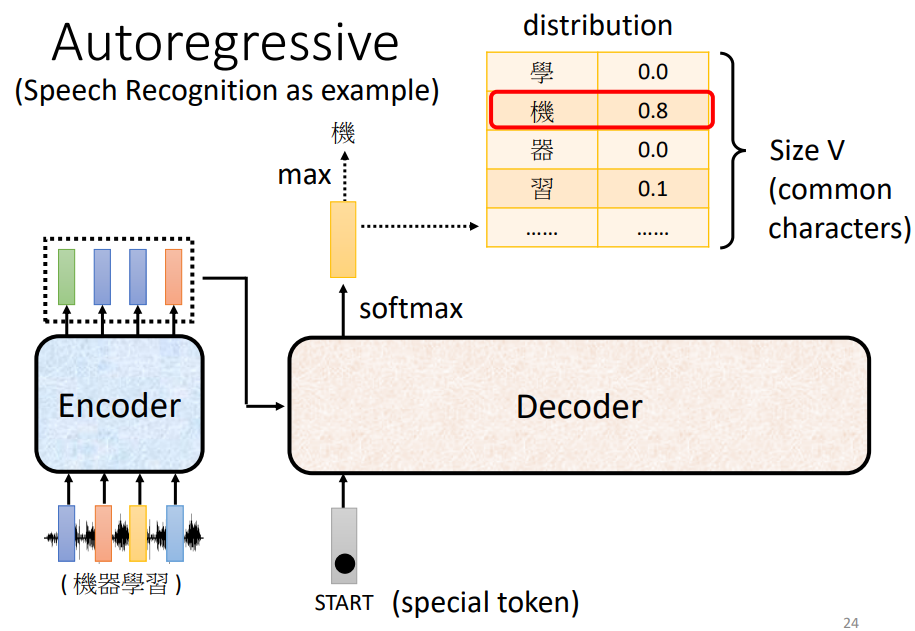
首先,输入一个声音讯号,经过encoder输出一组vector, 然后将这个输出当作decoder的输入,最后产生语音辨识的结果。
如果要处理NLP的问题,每一个token都可以把他用一个ONe-Hot的Vector(其中一维是1,其他都是0)来表示,所以begin也是用ONe-Hot Vector来表示。然后decoder吐出一个向量,这个vector的长度非常长,跟vocabulary的size是一样的。
Vocabulary:首先知道decoder输出的单位是什么? 假设是中文的语音辨识,那这里vocabulary的size可能就是中文的方块字的数目。要是英文的话,用字母数量会很少,用单词数量又会太多,所以可以用Subword当作英文的单位,即单词的字首字根的组合,数量适中。
然后输出的向量中的每一个中文的字通过softmax都会对应一个数值,数值最高的那一个中文字就是最终的输出。
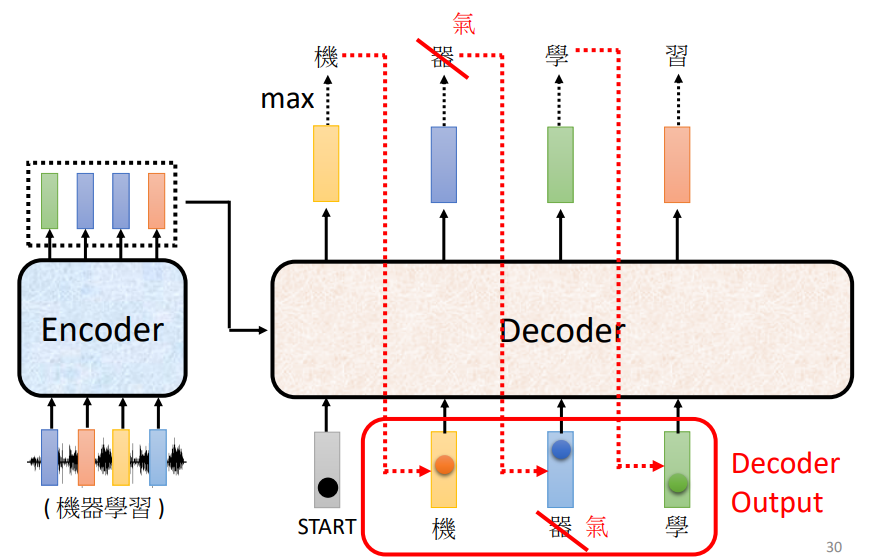
在上图的例子中,我们Begin的input会对应“机”的输出。然后把”机”当作是decoder新的input, 原来只有bengin一个输入,现在在加上“机”,“机”也可表示成一个ONe-Hot的Vector作为decoder的输入,所以现在有两个输入,然后就得到一个输出向量,在根据这个向量里面给出的每一个中文字的分数得到分值最高的输出,后面依次循环。Encoder的输出也会参与到这个过程中来。
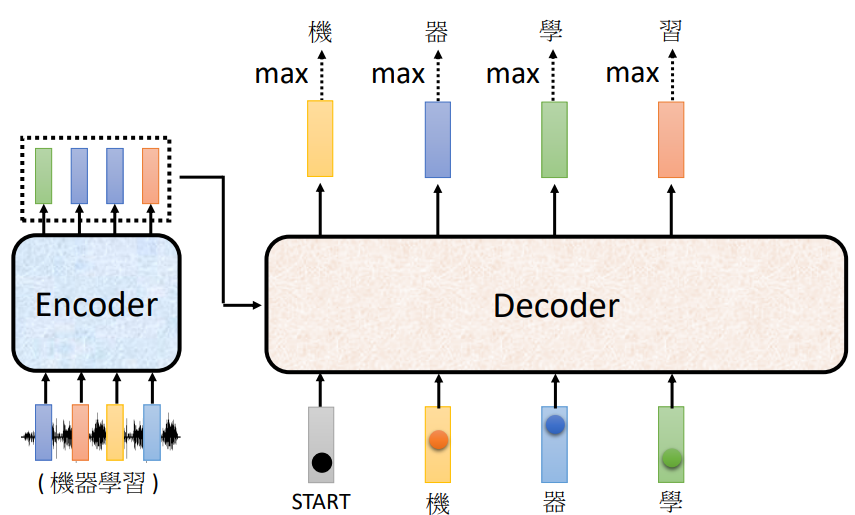
这里就会有一个问题:当decoder在产生一个句子的时候,它其实有可能在中途产生错误的输出,因为它是将自己的输出作为产生下一个字符的输入,而那个输出有可能是错误的。让decoder看到自己产生出来的错误的输入,再被decoder自己吃进去会不会造成Error Propagation(一步错,步步错)的问题呢?
下图是Decoder的内部结构:
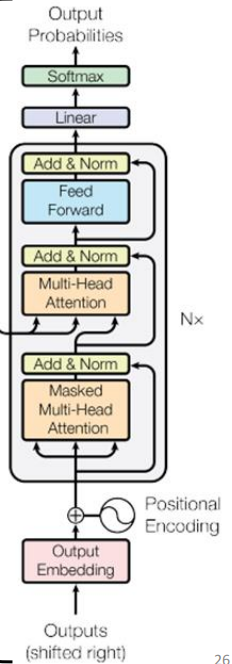
我们发现如果decoder中间遮住一部分,就会发现和encoder两者基本相同,如下图:
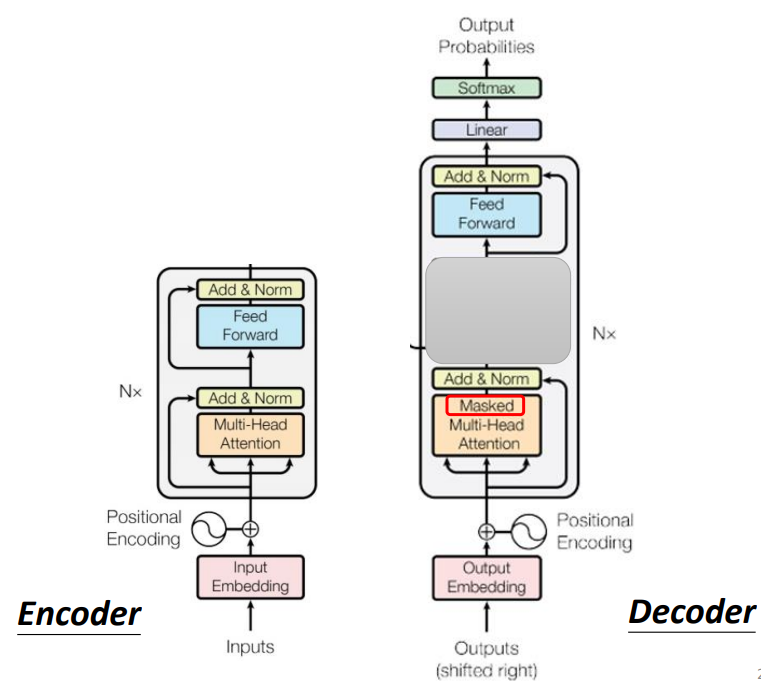
不同点:
(1)Decoder最后会做一个softmax,使得它的输出变成一个几率
(2)加了一个Masked
为什么需要加入Masked,具体原因如下:
我们知道原本的self-attention,输入一排vector,输出一排vector,这个vector的每一个输出都要看过完整的input之后才做决定,其实输出b1的时候其实是根据a1到a4所有的资讯去输出b1。
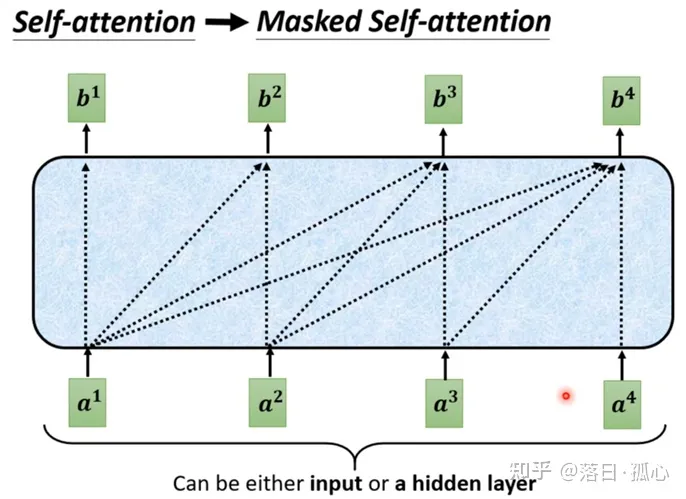
如上图,当self-attention转成Masked Attention的时候,他的不同点是,现在我们不能再看右边的部分,也就是我们产生b1的时候只能考虑a1的资讯,不能去看a2、a3、a4,产生b2的时候只能考虑a1、a2的资讯,不能考虑a3、a4的资讯,后面类似,最后产生b4时可以考虑所有的资讯。这就是Masked的self-attention。
更具体点,当产生b2时,只拿第二个位置a2的Query去跟第一个位置的Key和第二个位置的Key去计算Attention,第三个位置和第四个位置不用去管它。

Why masked?
一开始decoder的运作方式它是一个一个输出的,是先有a1,再有a2,然后是a3、a4,所以当计算b2时是没有a3和a4的,所以没办法将后面的考虑进来。
这跟原来的Self-Attention不一样,原来的Self-Attention中a1到a4是一次整个输入到Model里面的。
关键问题:Decoder自己决定输出的长度,但是到底输出的sequence的长度应该是多少呢?也就是机器如何决定该何时停下来。这里没办法决定,输出多少输出多少是非常复杂的,我们其实是期望机器可以自己学到。
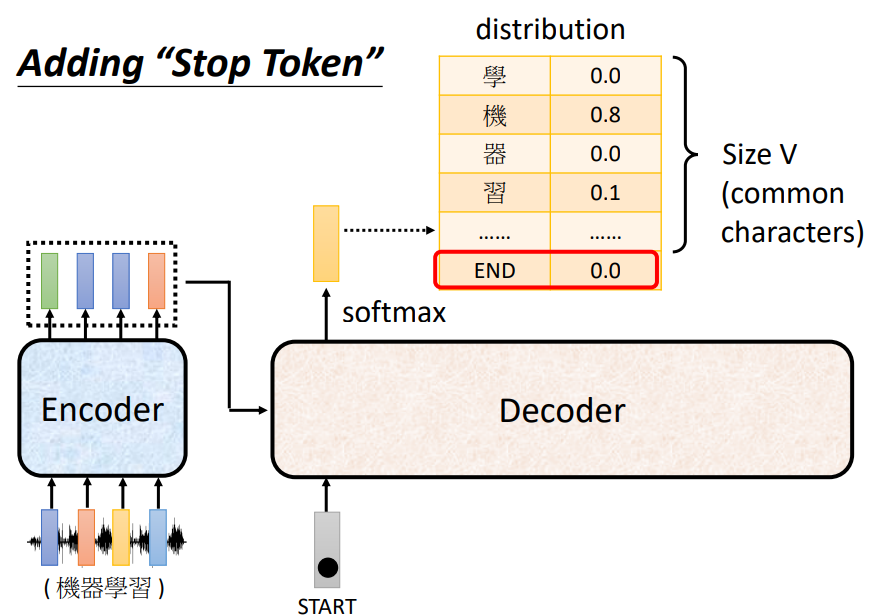
如上图,准备一个特别的符号“断”,用end来表示这个特别的符号,其实begin和end可以用同一个符号,因为begin只在开始时会出现一次。
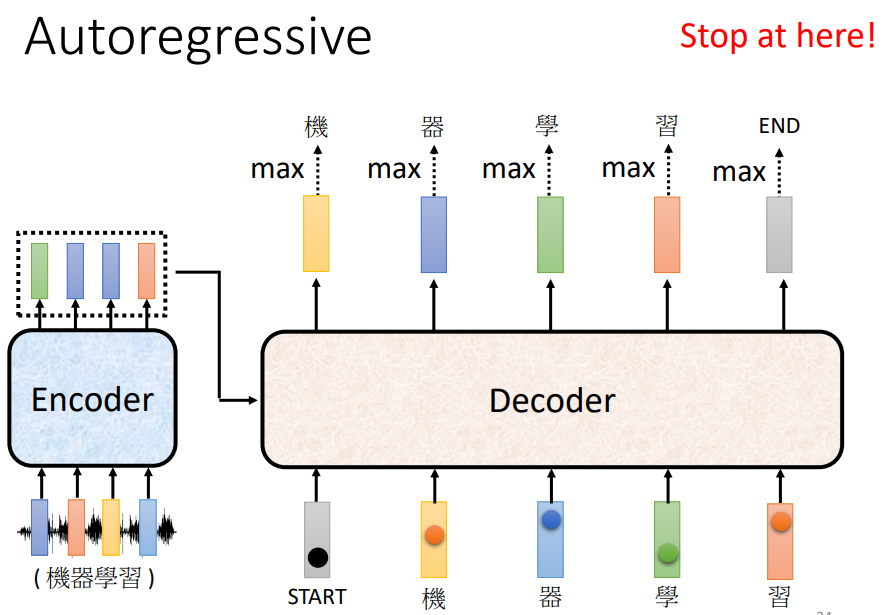
机器要自己知道在将自己的输出“习”再次当作输入时,要能够判断出现在应该输出end。
AT VS NAT:
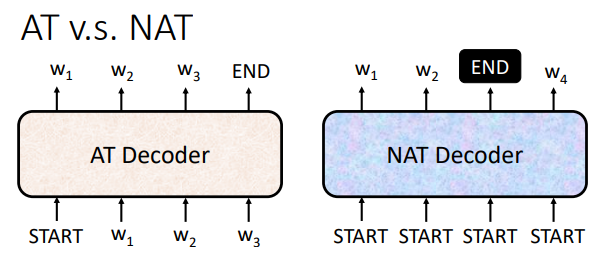
如图可见,AT是输入一个begin,输出一个字符,输入一个输出一个。而NAT是一次性输入全部的begin,然后输出全部的字符。
这里会出现相同的问题:输出的长度怎么来确定呢?
有两个办法:
(1)另外取一个classfier,这个classifier输入encoder的input,输出一个数字,这个数字代表应该要输出的长度。
(2)输入一堆begin的token,也就是大于输出上限值数量的输入,所以输出一堆的字符,忽略end后面的只取前面的字符。
NAT的好处:
(1)平行化:AT输出时是一个一个产生的,所以要输出100个字的句子,就要做一百次的decoder。但是NAT的decoder不管句子的长度如何,都是一个步骤就产生出完整的句子。速度上NAT的decoder会跑的比AT快。
(2)可以控制输出的长度。例如语音合成时,如果想要系统讲话快一点,就可以把classfier的output除以二,讲话的速度就会变成二倍速。同理,放慢速度就将输出的长度乘以二。
Nat通常比At的表现差。
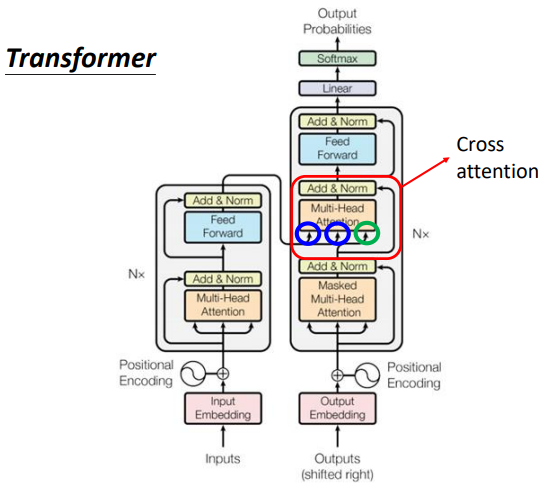
圈起来的那部分叫做Cross attention,它是连接Encoder跟Decoder之间的桥梁,从图中可以看出,这个模块的输入部分,有两个箭头来自encoder,一个来自decoder。
模块Cross attention实际运作过程:
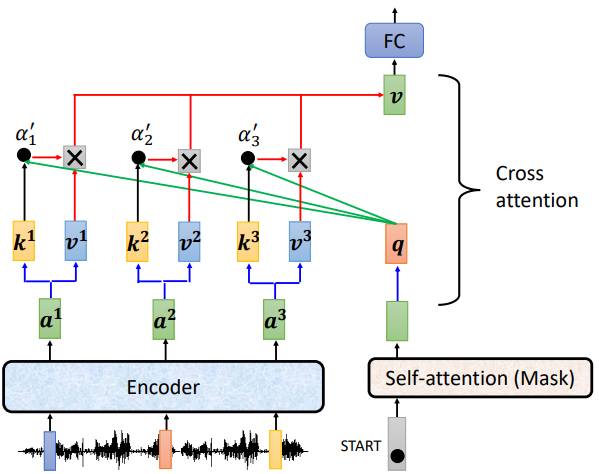
如上图,decoder就是产生一个q,去encoder那边抽取资讯出来当作接下来decoder里面的Fully-Connected 的Network的Input。具体来说就是,q和k1、k2、k3去计算分数,然后在和v1、v2、v3做Weighted Sum做加权,加起来得到v’,然后交给Fully-Connected处理。
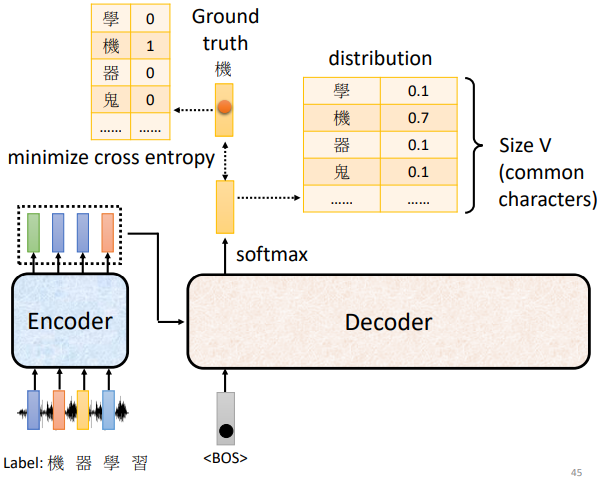
如上图,输入一段声音讯号,第一个而应该要输出的中文字是机,所以当我们把begin丢给decoder的时候,它的第一个输出要跟机越接近越好,即“机”这个字会被表示成一个One-Hot的Vector,在这个vector里面只有机对应的那个维度为1,而decoder的输出是一个Distribution是一个几率的分布,我们希望这个几率的分布跟One-Hot的Vector越接近越好。所以去计算Ground truth和distribution之间的Cross Entropy,希望这个Cross Entropy的值越小越好。
总体来说这件事情跟分类很像,我们可以想象,每一次Decoder在产生一个中文字的时候,其实就是做了一次分类问题,中文字假设有四千个,那就是做有四千个类别的分类的问题。
Teacher forcing:训练时给正确的答案作为Decoder的输入。
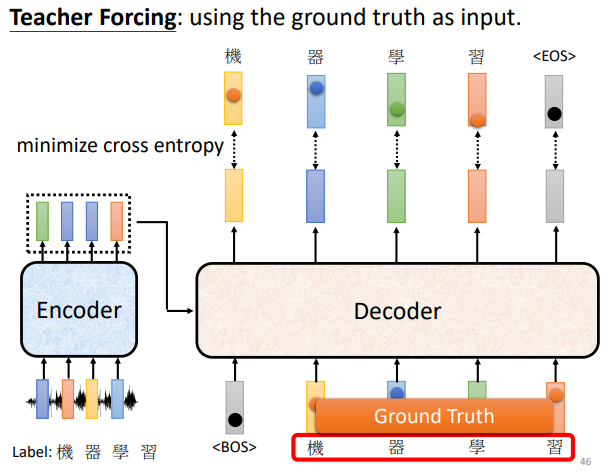
首先,我们已经知道输出应该是机器学习这四个字,然后告诉decoder它的正确输出应该是机器学习这四个中文字的One-Hot Vector,我们希望输出跟这四个字的One-Hot Vector越接近越好,在训练的时候每一个输出都会有一个Cross Entropy,每一个输出跟One-Hot Vector 跟他对应的正确答案都有一个Cross Entropy,最后我们希望所有的Cross Entropy的总和最小。
现在还有end的问题,机器要输出的不只是四个字,还有一个end,所以要让机器知道输出四个字以后,还要记着输出“断”。所以应该告诉decoder第五个位置的输出应该跟断的One-Hot Vector它的Cross Entropy越小越好。这个就是Decoder的训练。
这个训练会产生一个问题:训练的时候decoder会得到正确的答案作为输入,但是testing时decoder得到的是自己上一个的输出,这中间显然会有一个Mismatch。
(1)Copy Mechanism:对一些任务而言,decoder没有必要产生输出,它要做的是从输入的东西中复制一些出来,像这种复制行为的例子有聊天机器人。

(2)Guided Attention:它要做的事情就是要求机器去领导这个Attention的过程,要求机器去做attention的时候是有固定的方式的。

对于语音合成或者语音辨识来说,我们想象中的Attention应该是由左往右的,上图中红色曲线代表Attention的分数,若是语音合成的话,应该先看最左边输入的词去产生声音,再根据中间的词汇去产生声音,最后看右边的词汇产生声音。但是当你做语音合成时发现机器的读取顺序是颠三倒四的,显然是错的,无法合成出好的结果。而Guided Attention在这里要做的事情就是强迫Attention有一个固定的样貌,将这个必须从左到右的限制放到training里面,要求机器学到Attention就应该从左到右。
(3)Beam Search
举个例子来解释:
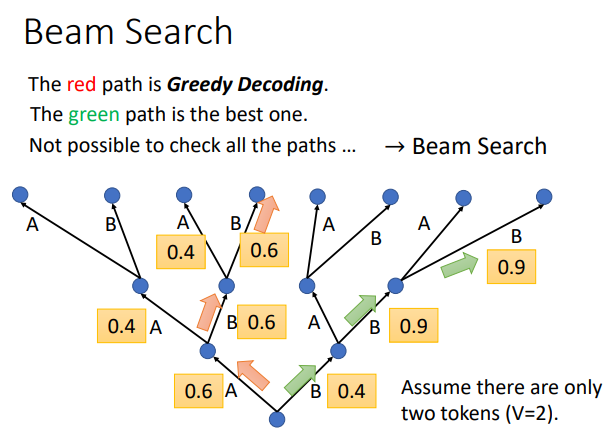
假设现在的decoder只能产生两个字,只能产生两个可能的输出一个是A,另一个为B。那对decoder而言,他做的事情就是在每一次第一个Time Step,在A、B里面决定一个,假如决定A以后将A当作输入在决定A、B要选哪一个,依次向后进行。在这个过程中,每一次Decoder都是选分数最高的那一个,但是有时候刚开始选分数高的,后面还是有可能差下来,还有时候一开始选择分数低点的,后面反而会更好。所以就可以通过Beam Search这个技术来找一个approximate不是完全精准的估测的solution。
现在对于Beam Search的评价有好有坏,当然了,要看具体的任务需求,若一个任务它的答案非常明确,例如语音识别,有唯一明确的答案,通常Beam Search就会比较有帮助。如果需要机器发挥一点创造力的时候,Beam Search的帮助就会很小。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true